FlowMM: Cross-Modal Information Flow Guided KV Cache Merging for Efficient Multimodal Context Inference
作者: Kunxi Li, Yufan Xiong, Zhonghua Jiang, Yiyun Zhou, Zhaode Wang, Chengfei Lv, Shengyu Zhang
分类: cs.CL
发布日期: 2025-10-29 (更新: 2025-11-13)
💡 一句话要点
FlowMM:跨模态信息流引导的KV缓存融合,提升多模态上下文推理效率
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 KV缓存 模型压缩 信息流 大语言模型 上下文推理 模型加速
📋 核心要点
- 传统KV缓存淘汰策略在多模态场景下易导致上下文丢失或幻觉,降低生成质量。
- FlowMM利用跨模态信息流自适应地融合KV缓存,并结合敏感度评估,保留关键信息。
- 实验表明,FlowMM显著降低了KV缓存内存占用和解码延迟,同时保持了任务性能。
📝 摘要(中文)
本文提出FlowMM,一个自适应的跨模态信息流引导的多模态KV缓存融合框架,旨在解决传统KV缓存淘汰策略在多模态场景下因模态分布偏差和跨模态交互偏差而导致生成质量下降的问题。FlowMM利用跨模态信息流动态地应用特定层的融合策略,捕捉模态特定模式,同时保持上下文完整性。此外,引入了一种敏感度自适应的token匹配机制,联合评估token相似性和任务关键敏感性,融合低风险token,同时保护高敏感性token。在多个领先的多模态大语言模型上的大量实验表明,FlowMM可将KV缓存内存减少80%到95%,解码延迟降低1.3-1.8倍,同时保持具有竞争力的任务性能。
🔬 方法详解
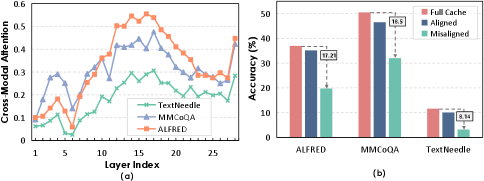
问题定义:论文旨在解决多模态大语言模型中,KV缓存占用大量内存,导致推理效率低下的问题。现有的KV缓存淘汰策略,如基于注意力得分的淘汰,容易丢失关键上下文信息,影响生成质量。而基于相似度的KV缓存融合方法,在多模态场景下,由于模态分布偏差和跨模态交互偏差,效果受限。
核心思路:论文的核心思路是利用跨模态信息流来指导KV缓存的融合过程,并结合token的敏感度评估,自适应地决定哪些token可以安全地融合,哪些token需要保留。通过这种方式,既能减少KV缓存的内存占用,又能保证模型的生成质量。
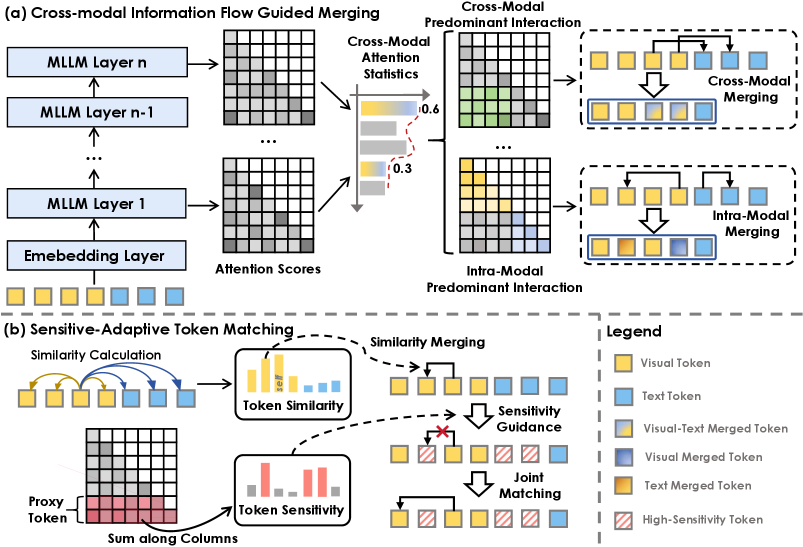
技术框架:FlowMM框架主要包含两个核心模块:跨模态信息流分析模块和敏感度自适应token匹配模块。跨模态信息流分析模块用于捕捉不同模态之间的交互模式,并根据这些模式动态地调整每一层的融合策略。敏感度自适应token匹配模块则用于评估每个token的重要性,并根据其重要性决定是否进行融合。整体流程是,首先利用跨模态信息流分析模块确定每一层的融合策略,然后利用敏感度自适应token匹配模块对KV缓存中的token进行评估,最后根据评估结果进行融合。
关键创新:FlowMM的关键创新在于其跨模态信息流引导的融合策略和敏感度自适应的token匹配机制。传统的KV缓存融合方法通常采用静态的融合策略,忽略了不同模态之间的差异和交互。而FlowMM能够根据跨模态信息流动态地调整融合策略,从而更好地适应多模态场景。此外,FlowMM的敏感度自适应token匹配机制能够更准确地评估token的重要性,避免了关键信息的丢失。
关键设计:FlowMM的关键设计包括:1) 使用跨模态注意力权重来衡量信息流;2) 设计了层特定的融合策略,允许不同层采用不同的融合比例;3) 引入了敏感度评分函数,结合token相似度和任务损失梯度来评估token的重要性;4) 使用加权平均的方式进行token融合,权重由相似度和敏感度评分共同决定。
🖼️ 关键图片

📊 实验亮点
实验结果表明,FlowMM在多个领先的多模态大语言模型上,能够将KV缓存内存减少80%到95%,解码延迟降低1.3-1.8倍,同时保持具有竞争力的任务性能。例如,在某个图像描述任务上,FlowMM在减少90% KV缓存内存的同时,性能仅下降了不到1%。
🎯 应用场景
FlowMM可应用于各种多模态大语言模型,特别是在资源受限的设备上,如移动设备和边缘设备。通过减少KV缓存的内存占用,FlowMM能够使这些模型在这些设备上更高效地运行。此外,FlowMM还可以用于加速多模态内容的生成和理解,例如图像描述、视频摘要和多模态对话等。
📄 摘要(原文)
Traditional KV cache eviction strategies, which discard less critical KV-pairs based on attention scores, often degrade generation quality, causing context loss or hallucinations. Recent efforts shift toward KV merging, merging eviction tokens with retention tokens based on similarity. However, in multimodal scenarios, distributional biases across modality tokens and attentional biases in cross-modal interactions limit its effectiveness. This work introduces FlowMM, an adaptive framework for cross-modal information flow-guided multimodal KV cache merging. FlowMM leverages cross-modal information flow to dynamically apply layer-specific merging strategies, capturing modality-specific patterns while preserving contextual integrity. Furthermore, we introduce a sensitivity-adaptive token matching mechanism that jointly evaluates token similarity and task-critical sensitivity, merging low-risk tokens while safeguarding high-sensitivity ones. Extensive experiments across diverse leading MLLMs show that FlowMM reduces KV cache memory by 80% to 95% and decoding latency by 1.3-1.8x, while maintaining competitive task performance.