Beyond One-Size-Fits-All: Personalized Harmful Content Detection with In-Context Learning
作者: Rufan Zhang, Lin Zhang, Xianghang Mi
分类: cs.CL
发布日期: 2025-10-29
💡 一句话要点
提出基于上下文学习的个性化有害内容检测框架,提升用户定制化和隐私保护。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 上下文学习 有害内容检测 个性化定制 用户隐私 提示工程
📋 核心要点
- 现有内容审核系统中心化、任务特定,缺乏透明度,忽略用户偏好,不适用于隐私敏感场景。
- 利用基础模型的上下文学习(ICL),统一检测毒性、垃圾邮件和负面情绪,实现轻量级个性化定制。
- 实验表明,ICL方法在跨任务泛化方面表现出色,仅需少量用户示例即可实现有效个性化。
📝 摘要(中文)
有害在线内容的泛滥需要强大且适应性强的审核系统。然而,目前流行的审核系统是中心化的和特定于任务的,透明度有限,忽略了不同的用户偏好,这种方法不适合隐私敏感或去中心化的环境。我们提出了一个新颖的框架,该框架利用基础模型的上下文学习(ICL)来统一毒性、垃圾邮件和负面情绪的检测,涵盖二元、多类和多标签设置。至关重要的是,我们的方法实现了轻量级的个性化,允许用户通过简单的基于提示的干预轻松阻止新类别、取消阻止现有类别或将检测扩展到语义变体,而无需模型重新训练。在公共基准(TextDetox、UCI SMS、SST2)和一个新的、带注释的Mastodon数据集上的大量实验表明:(i)基础模型实现了强大的跨任务泛化,通常匹配或超过特定任务的微调模型;(ii)只需一个用户提供的示例或定义即可实现有效的个性化;(iii)用标签定义或理由增强提示可以显著提高对嘈杂的真实世界数据的鲁棒性。我们的工作展示了超越“一刀切”审核的明确转变,将ICL确立为下一代以用户为中心的内容安全系统的实用、保护隐私和高度适应性的途径。为了促进可重复性并促进未来的研究,我们公开发布了GitHub上的代码和Hugging Face上的带注释的Mastodon数据集。
🔬 方法详解
问题定义:现有有害内容检测方法通常是“一刀切”的,无法满足不同用户的个性化需求,并且中心化的模型存在隐私泄露的风险。针对特定任务微调的模型泛化能力有限,难以适应新的有害内容类别或语义变体。
核心思路:利用大型语言模型(LLM)的上下文学习能力(In-Context Learning, ICL),通过少量示例或定义,引导模型识别和过滤用户定义的有害内容。这种方法无需重新训练模型,实现了轻量级的个性化定制,并保护了用户隐私。
技术框架:该框架的核心是利用预训练的基础模型(例如LLM),通过构建合适的提示(Prompt)来指导模型进行有害内容检测。提示中包含任务描述、少量示例(Few-shot learning)或标签定义。用户可以通过修改提示来定制检测规则,例如添加新的有害内容类别或调整现有类别的定义。框架支持二元分类、多类分类和多标签分类等多种任务设置。
关键创新:该论文的关键创新在于将上下文学习应用于个性化有害内容检测,实现了无需模型微调的定制化。通过简单的提示工程,用户可以轻松地调整检测规则,适应不断变化的有害内容形式。这种方法在保护用户隐私的同时,提高了内容审核的灵活性和适应性。
关键设计:提示的设计至关重要,需要包含清晰的任务描述、相关的示例或标签定义。论文研究了不同提示策略对模型性能的影响,例如使用标签定义或理由(Rationale)来增强提示。此外,论文还探索了少量样本学习(Few-shot learning)中样本数量对模型性能的影响。实验表明,即使只有一个用户提供的示例或定义,也能显著提高模型的个性化检测能力。
🖼️ 关键图片
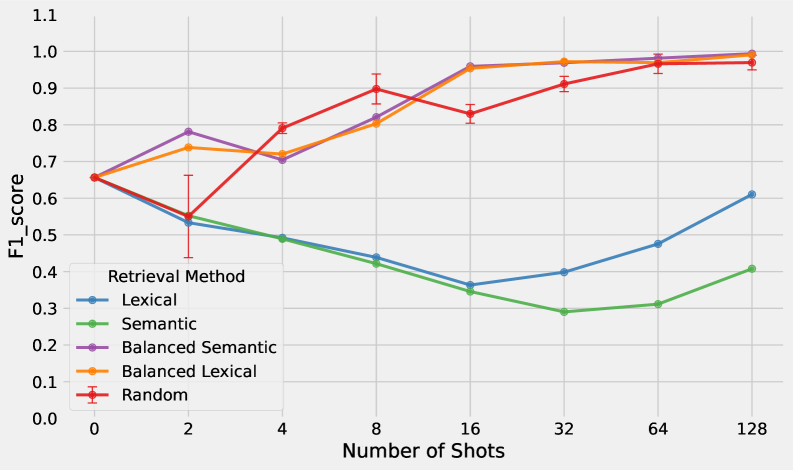
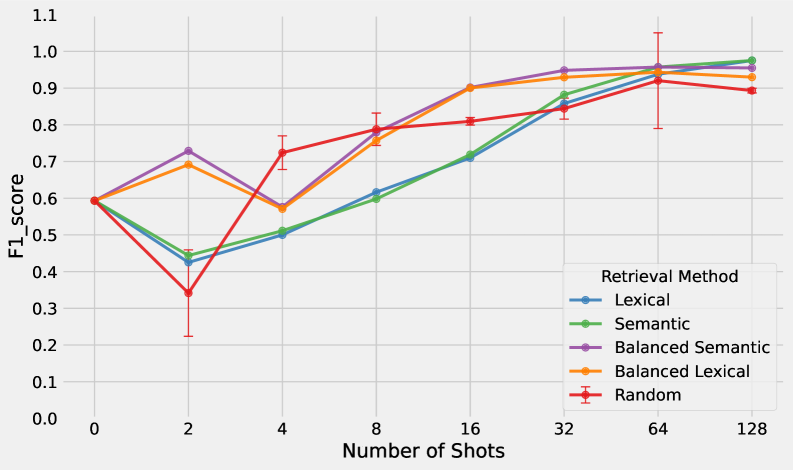
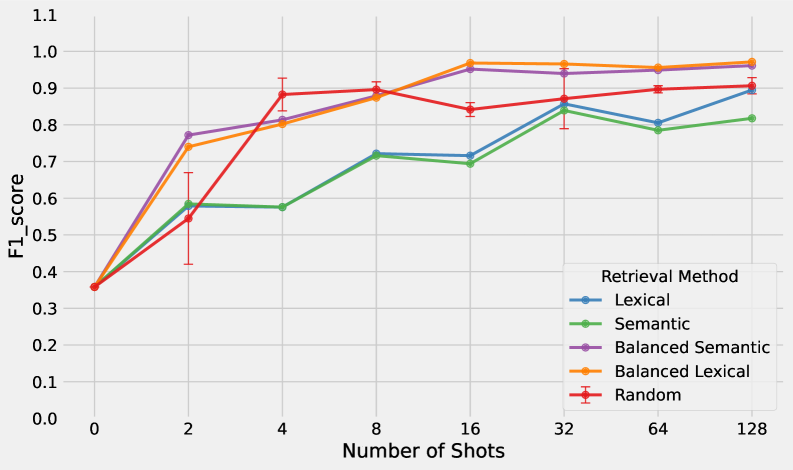
📊 实验亮点
实验结果表明,基于上下文学习的方法在多个公共基准数据集(TextDetox、UCI SMS、SST2)和新的Mastodon数据集上取得了良好的性能,通常可以匹配甚至超过特定任务的微调模型。仅需少量用户提供的示例或定义,即可实现有效的个性化。通过在提示中添加标签定义或理由,可以显著提高模型对真实世界噪声数据的鲁棒性。
🎯 应用场景
该研究成果可应用于各种在线平台的内容审核,例如社交媒体、论坛、电商平台等。用户可以根据自身需求定制有害内容过滤规则,屏蔽不感兴趣或认为有害的内容,从而改善用户体验。该方法还有助于保护用户隐私,避免敏感信息被用于训练中心化的审核模型。未来,该技术可以扩展到其他领域,例如个性化推荐、智能客服等。
📄 摘要(原文)
The proliferation of harmful online content--e.g., toxicity, spam, and negative sentiment--demands robust and adaptable moderation systems. However, prevailing moderation systems are centralized and task-specific, offering limited transparency and neglecting diverse user preferences--an approach ill-suited for privacy-sensitive or decentralized environments. We propose a novel framework that leverages in-context learning (ICL) with foundation models to unify the detection of toxicity, spam, and negative sentiment across binary, multi-class, and multi-label settings. Crucially, our approach enables lightweight personalization, allowing users to easily block new categories, unblock existing ones, or extend detection to semantic variations through simple prompt-based interventions--all without model retraining. Extensive experiments on public benchmarks (TextDetox, UCI SMS, SST2) and a new, annotated Mastodon dataset reveal that: (i) foundation models achieve strong cross-task generalization, often matching or surpassing task-specific fine-tuned models; (ii) effective personalization is achievable with as few as one user-provided example or definition; and (iii) augmenting prompts with label definitions or rationales significantly enhances robustness to noisy, real-world data. Our work demonstrates a definitive shift beyond one-size-fits-all moderation, establishing ICL as a practical, privacy-preserving, and highly adaptable pathway for the next generation of user-centric content safety systems. To foster reproducibility and facilitate future research, we publicly release our code on GitHub and the annotated Mastodon dataset on Hugging Face.