TextualVerifier: Verify TextGrad Step-by-Step
作者: Eugenius Mario Situmorang, Adila Alfa Krisnadhi, Ari Wibisono
分类: cs.CL
发布日期: 2025-10-29
💡 一句话要点
提出TextualVerifier,为TextGrad提供基于LLM的文本推理验证框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文本推理 自验证 大型语言模型 思维链 TextGrad
📋 核心要点
- TextGrad缺乏有效的自验证机制,难以保证文本推理决策的正确性,限制了其在复杂任务中的应用。
- TextualVerifier利用思维链、变体生成和多数投票等技术,构建LLM驱动的验证框架,无需数值梯度即可实现TextGrad的自验证。
- 实验表明,TextualVerifier显著提升了TextGrad的推理有效性,在多个基准测试中取得了性能提升,验证了其有效性。
📝 摘要(中文)
TextGrad是一种新颖的基于文本的自动微分方法,它使复合AI系统能够在没有显式数值方程的情况下执行优化。然而,它目前缺乏自我验证机制,以确保基于文本的决策中的推理有效性。本研究引入了TextualVerifier,这是一个验证框架,它利用思维链推理和大型语言模型(LLM)的多数投票来解决这一验证差距。TextualVerifier实现了四个阶段的工作流程:思维链分解、变体生成、多数投票和共识聚合。它以非侵入方式与TextGrad在损失函数和优化结果验证阶段集成。使用Gemini 1.5 Pro模型进行了两个阶段的实验评估:(1)在PRM800K上进行独立评估,以及(2)在GPQA-Diamond、MMLU-ML和MMLU-CP基准上与TextGrad集成评估。结果显示出具有统计学意义的改进(p < 0.001)。在第一阶段,TextualVerifier将推理步骤的有效性提高了29%。在第二阶段,集成到TextGrad损失函数中,从68.2%提高到70.4%,提高了2.2个百分点,平均开销为5.9次LLM调用。TextualVerifier版本控制的进一步评估在GPQA、MMLU-ML和MMLU-CP上分别产生了8.08、10.71和3.92个百分点的改进。因此,TextualVerifier提出了第一个基于LLM技术的TextGrad自验证框架,无需数值梯度,从而实现了更可靠的推理,并为基于文本的优化中的验证开辟了新的方向。
🔬 方法详解
问题定义:TextGrad虽然能够进行基于文本的自动微分,但缺乏有效的自我验证机制。这意味着在复杂的推理过程中,TextGrad难以保证每一步推理的正确性,容易产生错误累积,最终影响决策的可靠性。现有方法依赖数值梯度,不适用于TextGrad的文本环境。
核心思路:TextualVerifier的核心思路是利用大型语言模型(LLM)的强大推理能力,通过生成多个推理变体并进行多数投票,来验证TextGrad的推理步骤。这种方法模拟了人类专家评审的过程,能够有效地发现和纠正TextGrad的推理错误,提高其决策的可靠性。
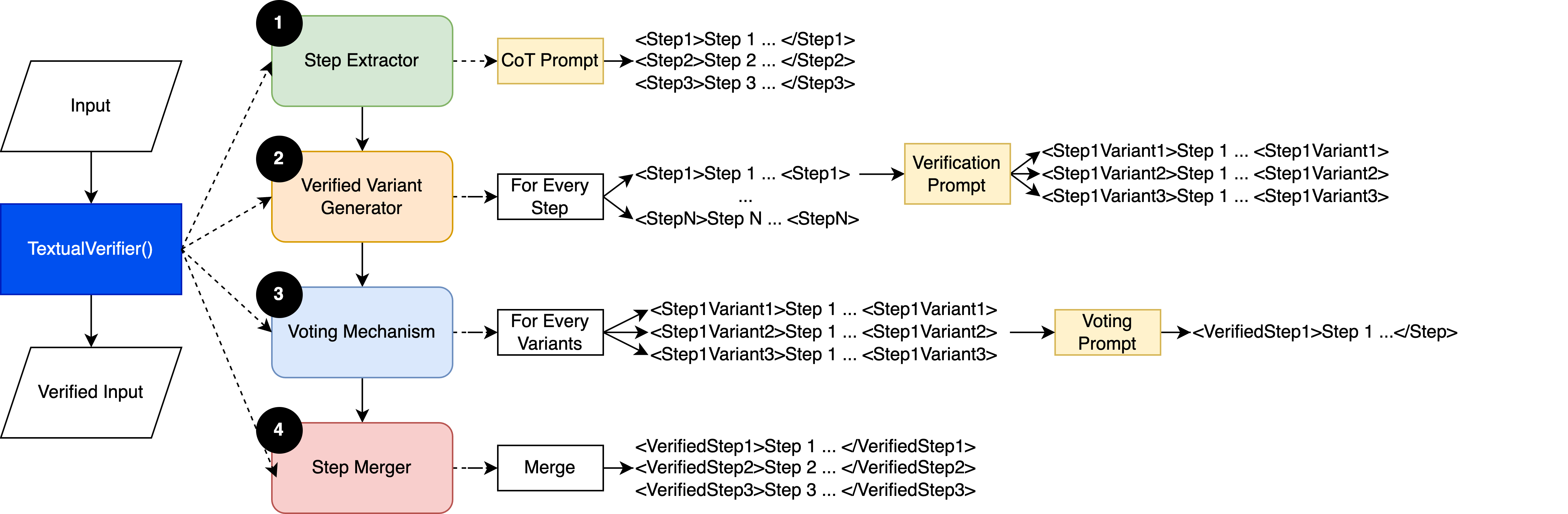
技术框架:TextualVerifier包含四个主要阶段:1) 思维链分解:将复杂的推理过程分解为多个步骤,形成思维链;2) 变体生成:利用LLM针对每个推理步骤生成多个不同的推理变体;3) 多数投票:对每个推理步骤的多个变体进行投票,选择得票最多的结果;4) 共识聚合:将通过多数投票验证的推理步骤聚合起来,形成最终的验证结果。TextualVerifier可以集成到TextGrad的损失函数和优化结果验证阶段。
关键创新:TextualVerifier的关键创新在于提出了一个基于LLM的文本推理自验证框架,无需数值梯度即可实现TextGrad的验证。它将思维链、变体生成和多数投票等技术巧妙地结合起来,构建了一个有效的验证流程。这是第一个专门为TextGrad设计的自验证框架。
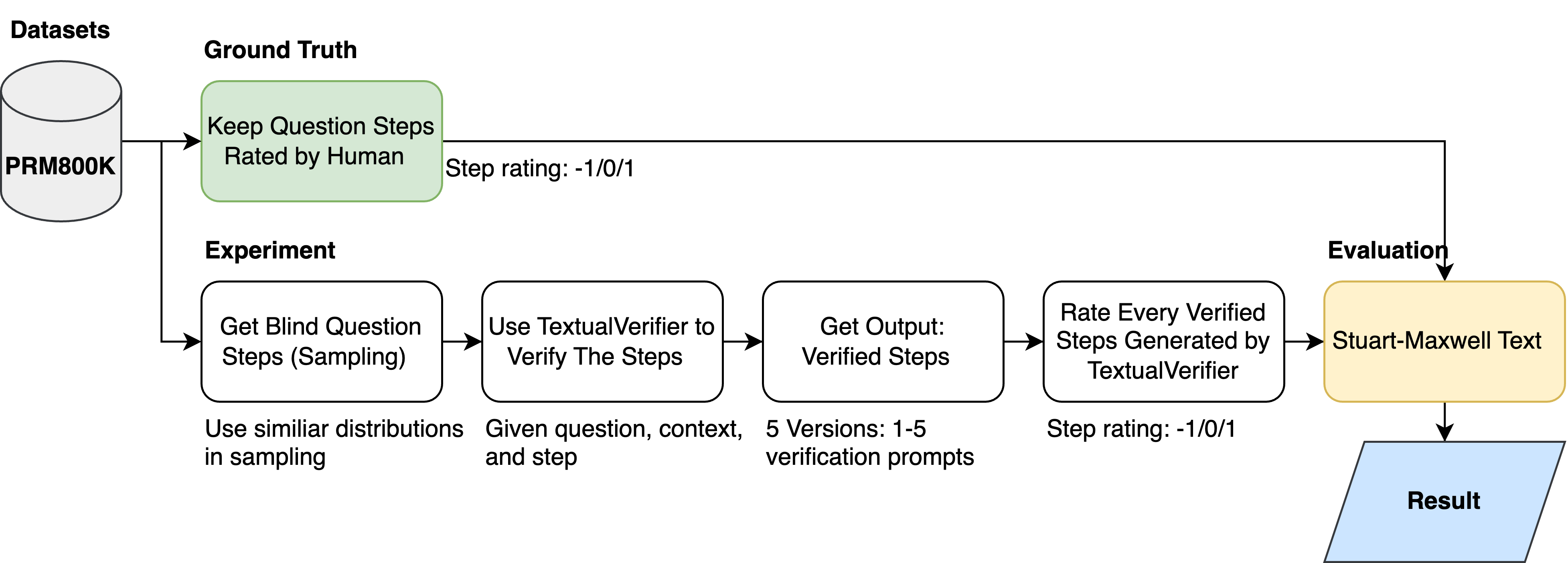
关键设计:TextualVerifier使用Gemini 1.5 Pro作为LLM,通过prompt engineering来引导LLM生成高质量的推理变体。在多数投票阶段,采用简单的计数方法,选择出现次数最多的结果。实验中,平均每个推理步骤生成5.9个变体。具体prompt的设计和LLM的选择是影响TextualVerifier性能的关键因素。
🖼️ 关键图片

📊 实验亮点
TextualVerifier在PRM800K上独立评估时,将推理步骤的有效性提高了29%。与TextGrad集成后,在GPQA-Diamond、MMLU-ML和MMLU-CP基准测试中,TextualVerifier分别取得了8.08、10.71和3.92个百分点的性能提升。集成到TextGrad损失函数中,性能从68.2%提高到70.4%,提高了2.2个百分点,平均开销为5.9次LLM调用。
🎯 应用场景
TextualVerifier可应用于各种需要可靠文本推理的场景,例如自动代码生成、文本摘要、问答系统和对话系统。通过提高TextGrad的推理可靠性,TextualVerifier可以促进这些应用在安全性要求较高的领域(如医疗、金融)的应用,并提升用户体验。
📄 摘要(原文)
TextGrad is a novel approach to text-based automatic differentiation that enables composite AI systems to perform optimization without explicit numerical equations. However, it currently lacks self-verification mechanisms that ensure reasoning validity in text-based decision making. This research introduces TextualVerifier, a verification framework that leverages chain-of-thought reasoning and majority voting with large language models to address this verification gap. TextualVerifier implements a four-stage workflow: chain-of-thought decomposition, variant generation, majority voting, and consensus aggregation. It integrates non-invasively with TextGrad at both the loss function and optimization result verification stages. Experimental evaluation using the Gemini 1.5 Pro model is conducted in two phases: (1) standalone evaluation on PRM800K, and (2) integrated evaluation with TextGrad on GPQA-Diamond, MMLU-ML, and MMLU-CP benchmarks. Results show statistically significant improvements (p < 0.001). In phase one, TextualVerifier improves the validity of reasoning steps by 29 percent. In phase two, integration into TextGrad loss function yields a 2.2 percentage point gain from 68.2 to 70.4 percent with a moderate overhead of 5.9 LLM calls on average. Further evaluations of TextualVerifier versioning yield 8.08, 10.71, and 3.92 percentage point improvements on GPQA, MMLU-ML, and MMLU-CP respectively. TextualVerifier thus presents the first self-verification framework for TextGrad through LLM-based techniques without requiring numerical gradients, enabling more reliable reasoning and opening new directions for verification in text-based optimization.