Revisiting Multilingual Data Mixtures in Language Model Pretraining
作者: Negar Foroutan, Paul Teiletche, Ayush Kumar Tarun, Antoine Bosselut
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-10-29
备注: Under Review
💡 一句话要点
研究多语言数据混合对预训练语言模型的影响,挑战多语言学习的固有认知。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多语言预训练 语言模型 数据混合 枢轴语言 跨语言迁移学习
📋 核心要点
- 多语言预训练中,语言覆盖范围与模型性能的权衡是核心问题,即“多语言学习的诅咒”。
- 该研究通过控制预训练数据中语言的数量和类型,探索不同多语言数据混合策略对模型性能的影响。
- 实验结果表明,适当平衡的多语言数据可以提升模型能力,且未观察到显著的“多语言学习的诅咒”。
📝 摘要(中文)
大型语言模型(LLM)预训练中不同多语言数据混合的影响一直备受争议,人们常常担心语言覆盖范围和模型性能之间可能存在权衡(即多语言学习的诅咒)。本文通过在不同的多语言语料库上训练11亿和30亿参数的LLM,并将语言数量从25种增加到400种,来研究这些假设。我们的研究挑战了围绕多语言训练的普遍看法。首先,我们发现,如果语料库中包含足够数量的token,那么组合英语和多语言数据不一定会降低两者的语言性能。其次,我们观察到,使用英语作为枢轴语言(即一种高资源语言,可以作为多语言泛化的催化剂)可以跨语言族产生益处,并且与预期相反,从特定语言族中选择枢轴语言并不能始终提高该族内语言的性能。最后,我们没有观察到随着模型中训练语言数量的增加,会出现显著的“多语言学习的诅咒”。我们的研究结果表明,如果多语言数据得到适当的平衡,就可以增强语言模型的能力,而不会降低性能,即使在低资源环境中也是如此。
🔬 方法详解
问题定义:现有研究对多语言预训练中数据混合策略的影响存在争议,尤其是在语言覆盖范围和模型性能之间是否存在trade-off,即“多语言学习的诅咒”。此外,如何选择合适的枢轴语言以促进跨语言泛化也是一个待解决的问题。
核心思路:通过系统性地控制预训练数据中语言的数量(25到400)和类型,研究不同多语言数据混合策略对大型语言模型(1.1B和3B参数)性能的影响。重点关注英语作为枢轴语言的作用,以及是否会受到“多语言学习的诅咒”的影响。
技术框架:该研究采用标准的语言模型预训练流程,使用不同的多语言语料库训练Transformer架构的LLM。主要变量是预训练数据中包含的语言数量和语言分布。通过在各种下游任务上评估模型的性能,来衡量不同数据混合策略的效果。
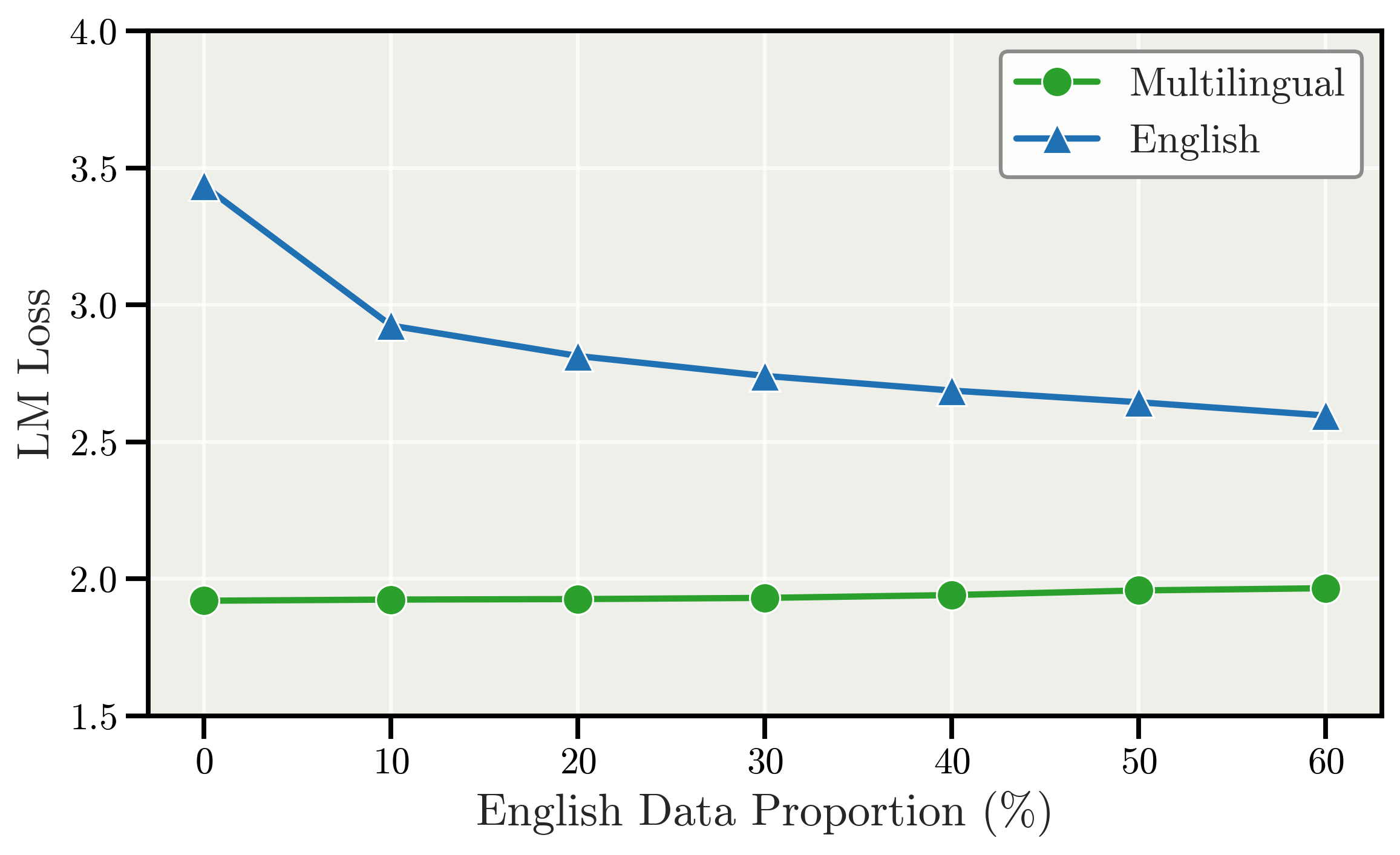
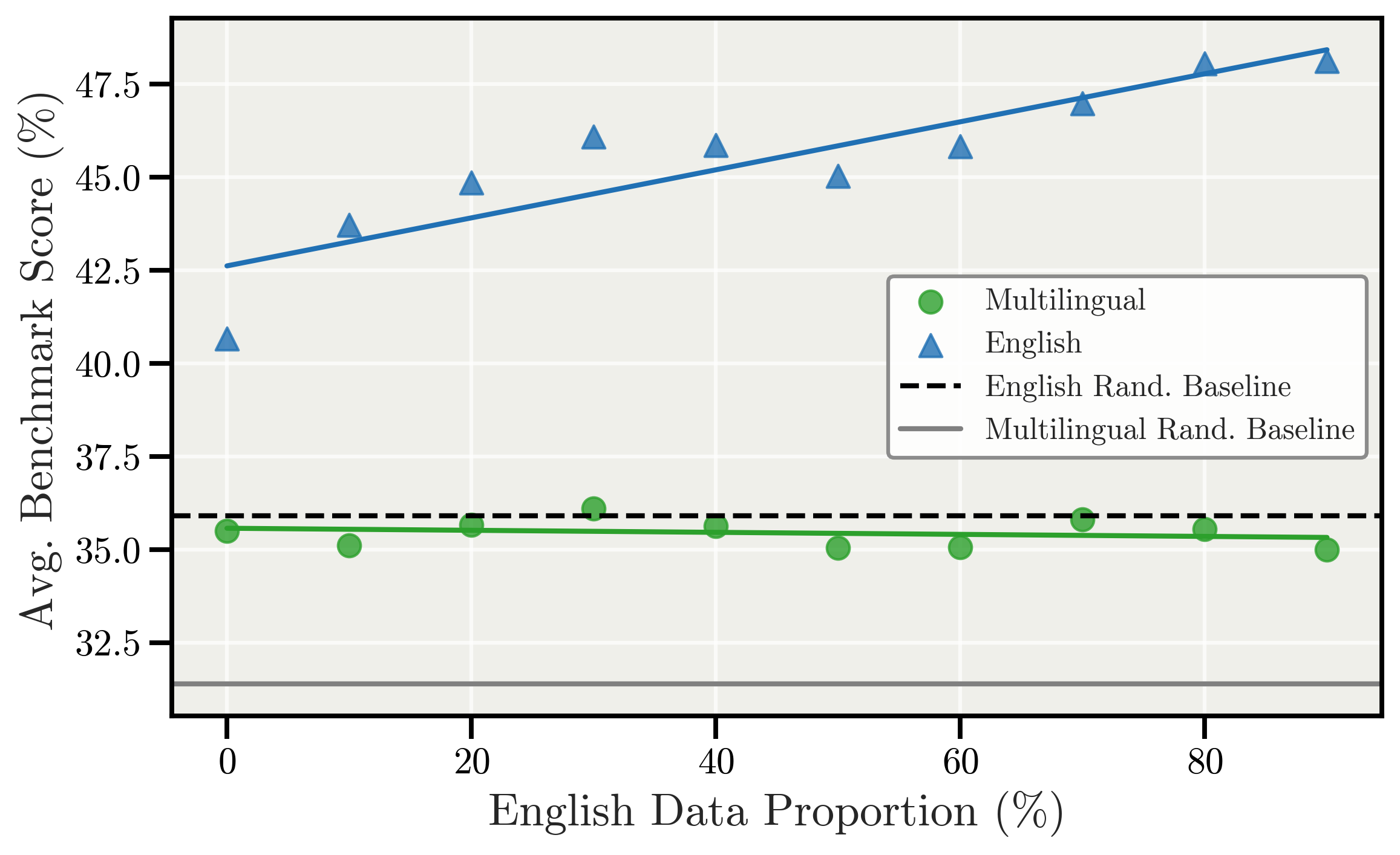
关键创新:该研究挑战了多语言预训练的一些固有认知。首先,证明了在适当平衡的情况下,组合英语和多语言数据不会降低各自的语言性能。其次,发现使用英语作为枢轴语言可以跨语言族产生益处,而并非仅限于特定语言族。最后,没有观察到显著的“多语言学习的诅咒”。
关键设计:研究中关键的设计包括:1) 精心选择和平衡多语言语料库,确保每种语言都有足够的tokens。2) 使用英语作为枢轴语言,并与其他语言进行混合。3) 在各种下游任务上评估模型的性能,包括跨语言迁移学习任务。4) 模型参数规模为1.1B和3B,属于中等规模的LLM。
🖼️ 关键图片

📊 实验亮点
实验结果表明,适当平衡的多语言数据可以提升模型能力,且未观察到显著的“多语言学习的诅咒”。使用英语作为枢轴语言可以跨语言族产生益处,而并非仅限于特定语言族。组合英语和多语言数据不一定会降低各自的语言性能,前提是每种语言都有足够的tokens。
🎯 应用场景
该研究成果可应用于多语言自然语言处理系统的开发,尤其是在低资源语言场景下。通过合理的数据混合策略,可以提升模型在多种语言上的性能,促进跨语言信息交流和知识共享。未来的研究可以探索更大规模的模型和更复杂的数据混合策略。
📄 摘要(原文)
The impact of different multilingual data mixtures in pretraining large language models (LLMs) has been a topic of ongoing debate, often raising concerns about potential trade-offs between language coverage and model performance (i.e., the curse of multilinguality). In this work, we investigate these assumptions by training 1.1B and 3B parameter LLMs on diverse multilingual corpora, varying the number of languages from 25 to 400. Our study challenges common beliefs surrounding multilingual training. First, we find that combining English and multilingual data does not necessarily degrade the in-language performance of either group, provided that languages have a sufficient number of tokens included in the pretraining corpus. Second, we observe that using English as a pivot language (i.e., a high-resource language that serves as a catalyst for multilingual generalization) yields benefits across language families, and contrary to expectations, selecting a pivot language from within a specific family does not consistently improve performance for languages within that family. Lastly, we do not observe a significant "curse of multilinguality" as the number of training languages increases in models at this scale. Our findings suggest that multilingual data, when balanced appropriately, can enhance language model capabilities without compromising performance, even in low-resource settings