RECAP: Reproducing Copyrighted Data from LLMs Training with an Agentic Pipeline
作者: André V. Duarte, Xuying li, Bin Zeng, Arlindo L. Oliveira, Lei Li, Zhuo Li
分类: cs.CL
发布日期: 2025-10-29
💡 一句话要点
提出RECAP,通过Agent协作从LLM中提取并验证版权数据记忆
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 版权数据提取 Agent协作 反馈循环 越狱攻击
📋 核心要点
- 现有方法难以验证LLM是否记忆了版权数据,缺乏有效提取和验证机制。
- RECAP利用Agent协作,通过反馈循环和越狱模块,引导LLM再现和修正记忆内容。
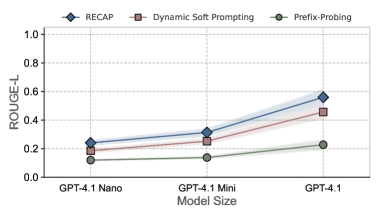
- 实验表明,RECAP在EchoTrace基准上显著提升了版权文本提取的ROUGE-L得分,效果提升明显。
📝 摘要(中文)
如果我们无法检查大型语言模型(LLM)的训练数据,我们如何才能知道它学到了什么?我们认为,当模型本身自由地再现目标内容时,最有说服力的证据就出现了。因此,我们提出了RECAP,一个旨在从LLM输出中引出和验证记忆化训练数据的Agent流程。RECAP的核心是一个反馈驱动的循环,其中初始提取尝试由辅助语言模型评估,该模型将输出与参考段落进行比较并识别差异。然后,这些差异被转化为最小的修正提示,反馈到目标模型以指导后续生成。此外,为了解决对齐诱导的拒绝,RECAP包括一个越狱模块,用于检测和克服此类障碍。我们在EchoTrace(一个包含30多本完整书籍的新基准)上评估了RECAP,结果表明,RECAP比单次迭代方法有了显著的提升。例如,使用GPT-4.1,版权文本提取的平均ROUGE-L得分从0.38提高到0.47,提升了近24%。
🔬 方法详解
问题定义:论文旨在解决如何从大型语言模型(LLM)中提取并验证其记忆的版权数据的问题。现有方法主要依赖于单次prompt,难以有效引出模型记忆的内容,并且模型可能由于对齐限制而拒绝生成相关内容。因此,需要一种更有效的方法来提取和验证LLM记忆的版权数据。
核心思路:论文的核心思路是构建一个Agent协作的反馈循环,通过一个辅助语言模型来评估目标模型的输出,并生成修正提示,引导目标模型逐步完善输出,从而更准确地提取记忆的版权数据。同时,引入越狱模块来克服模型对齐带来的限制,确保模型能够生成所需的内容。
技术框架:RECAP包含以下主要模块:1) 初始提取模块:使用初始prompt从目标LLM中提取内容。2) 评估模块:使用辅助LLM将提取的内容与参考文本进行比较,识别差异。3) 修正提示生成模块:根据差异生成最小的修正提示。4) 反馈循环:将修正提示反馈给目标LLM,引导其生成更准确的内容。5) 越狱模块:检测并克服模型对齐带来的限制。整个流程通过迭代循环,逐步提高提取的准确性。
关键创新:RECAP的关键创新在于Agent协作的反馈循环和越狱模块的结合。反馈循环能够有效地引导目标模型逐步完善输出,提高提取的准确性。越狱模块能够克服模型对齐带来的限制,确保模型能够生成所需的内容。这种结合使得RECAP能够更有效地提取和验证LLM记忆的版权数据。
关键设计:RECAP的关键设计包括:1) 辅助LLM的选择和prompt设计,需要选择合适的LLM并设计有效的prompt,以准确评估目标模型的输出并生成有效的修正提示。2) 越狱模块的设计,需要设计有效的策略来检测和克服模型对齐带来的限制。3) 反馈循环的迭代次数和停止条件,需要根据实际情况进行调整,以达到最佳的提取效果。
🖼️ 关键图片


📊 实验亮点
实验结果表明,RECAP在EchoTrace基准上显著提升了版权文本提取的性能。使用GPT-4.1,RECAP将平均ROUGE-L得分从0.38提高到0.47,提升了近24%。这表明RECAP能够更有效地从LLM中提取和验证版权数据。
🎯 应用场景
RECAP可应用于版权保护领域,帮助识别LLM是否侵犯版权。同时,该方法也可用于评估LLM的训练数据质量,了解模型记忆了哪些信息。此外,RECAP的Agent协作框架可以推广到其他需要从LLM中提取特定信息的任务中,具有广泛的应用前景。
📄 摘要(原文)
If we cannot inspect the training data of a large language model (LLM), how can we ever know what it has seen? We believe the most compelling evidence arises when the model itself freely reproduces the target content. As such, we propose RECAP, an agentic pipeline designed to elicit and verify memorized training data from LLM outputs. At the heart of RECAP is a feedback-driven loop, where an initial extraction attempt is evaluated by a secondary language model, which compares the output against a reference passage and identifies discrepancies. These are then translated into minimal correction hints, which are fed back into the target model to guide subsequent generations. In addition, to address alignment-induced refusals, RECAP includes a jailbreaking module that detects and overcomes such barriers. We evaluate RECAP on EchoTrace, a new benchmark spanning over 30 full books, and the results show that RECAP leads to substantial gains over single-iteration approaches. For instance, with GPT-4.1, the average ROUGE-L score for the copyrighted text extraction improved from 0.38 to 0.47 - a nearly 24% increase.