Scaling Latent Reasoning via Looped Language Models
作者: Rui-Jie Zhu, Zixuan Wang, Kai Hua, Tianyu Zhang, Ziniu Li, Haoran Que, Boyi Wei, Zixin Wen, Fan Yin, He Xing, Lu Li, Jiajun Shi, Kaijing Ma, Shanda Li, Taylor Kergan, Andrew Smith, Xingwei Qu, Mude Hui, Bohong Wu, Qiyang Min, Hongzhi Huang, Xun Zhou, Wei Ye, Jiaheng Liu, Jian Yang, Yunfeng Shi, Chenghua Lin, Enduo Zhao, Tianle Cai, Ge Zhang, Wenhao Huang, Yoshua Bengio, Jason Eshraghian
分类: cs.CL
发布日期: 2025-10-29 (更新: 2025-11-17)
💡 一句话要点
Ouro:通过循环语言模型和隐空间推理提升LLM性能
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 循环语言模型 隐空间推理 预训练 深度学习 知识操纵
📋 核心要点
- 现有LLM主要依赖显式文本生成(如CoT)进行推理,推理过程放在后训练阶段,未能充分利用预训练数据。
- Ouro通过循环语言模型(LoopLM)在预训练阶段构建推理能力,利用隐空间迭代计算和熵正则化目标函数。
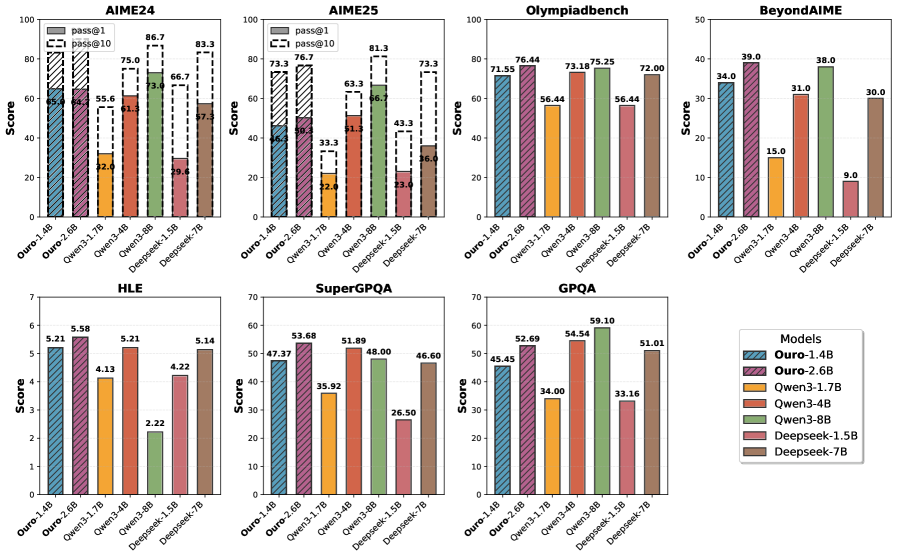
- 实验表明,Ouro 1.4B和2.6B模型在多个基准测试中达到甚至超过了12B参数的SOTA LLM的性能。
📝 摘要(中文)
本文提出了一种新的预训练方法,名为Ouro,它是一系列循环语言模型(LoopLM),旨在将推理能力融入到预训练阶段。Ouro通过以下方式实现:(i) 在隐空间中进行迭代计算,(ii) 使用熵正则化目标函数进行学习深度分配,以及(iii) 扩展到7.7T tokens。Ouro 1.4B和2.6B模型的性能优于现有12B参数的最先进LLM。通过对照实验表明,这种优势并非来自知识容量的增加,而是来自更强的知识操纵能力。此外,LoopLM产生的推理轨迹与最终输出比显式CoT更一致。该研究表明LoopLM作为推理时代的一种新的扩展方向具有潜力。模型已开源。
🔬 方法详解
问题定义:现有大型语言模型(LLM)的推理能力主要依赖于显式的文本生成方法,例如思维链(Chain-of-Thought, CoT)。这种方法将推理过程推迟到预训练之后,导致模型无法充分利用预训练数据中蕴含的推理信息。因此,如何将推理能力有效地融入到LLM的预训练阶段,是一个重要的研究问题。
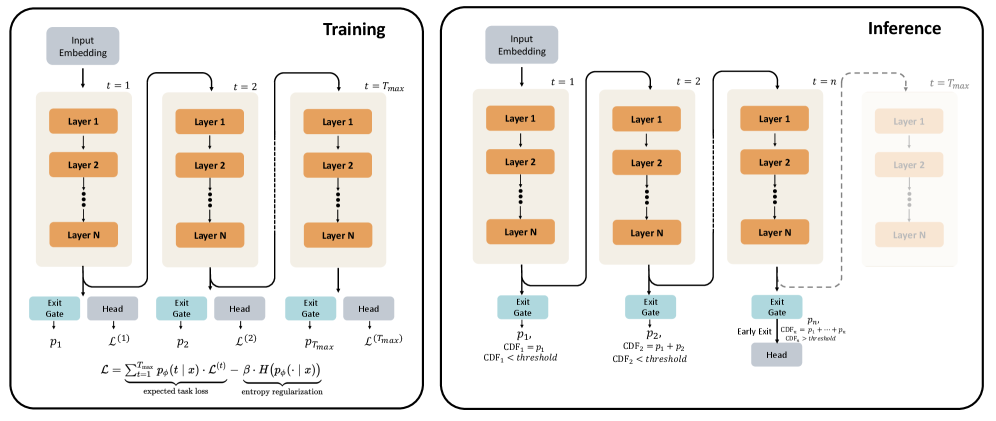
核心思路:Ouro的核心思路是通过循环语言模型(LoopLM)在隐空间中进行迭代计算,从而在预训练阶段就构建模型的推理能力。这种方法模拟了人类的思考过程,即在解决问题时,我们会反复思考、修正思路,最终得出答案。通过在隐空间中进行多次迭代,模型可以逐步提炼和完善其推理过程。
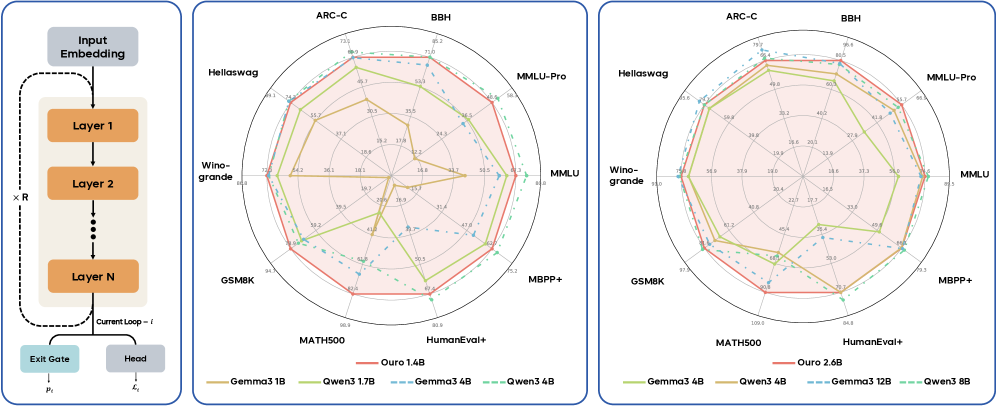
技术框架:Ouro的技术框架主要包括以下几个关键组成部分:1) 循环语言模型(LoopLM):模型的核心是一个循环神经网络,它在隐空间中进行迭代计算。2) 熵正则化目标函数:该目标函数用于学习深度分配,即决定在隐空间中进行多少次迭代。通过熵正则化,可以鼓励模型探索不同的迭代深度,从而提高模型的泛化能力。3) 大规模预训练:Ouro模型在7.7T tokens的数据集上进行预训练,从而获得丰富的知识和推理能力。
关键创新:Ouro最重要的技术创新点在于它将推理能力融入到LLM的预训练阶段。与传统的CoT方法相比,Ouro不需要在后训练阶段进行额外的推理训练,而是直接利用预训练数据来学习推理能力。此外,Ouro通过在隐空间中进行迭代计算,可以模拟人类的思考过程,从而提高模型的推理能力。
关键设计:Ouro的关键设计包括:1) 循环神经网络的结构:具体采用何种循环神经网络结构(例如LSTM、GRU或Transformer)未知,但循环结构是实现隐空间迭代计算的基础。2) 熵正则化系数:熵正则化系数控制了模型探索不同迭代深度的程度。合适的熵正则化系数可以提高模型的泛化能力。3) 预训练数据集的选择:预训练数据集的质量和规模对Ouro的性能至关重要。选择包含丰富知识和推理信息的数据集可以提高模型的推理能力。
🖼️ 关键图片
📊 实验亮点
Ouro 1.4B和2.6B模型在多个基准测试中表现出色,性能与12B参数的SOTA LLM相当甚至超过。实验结果表明,Ouro的优势并非来自知识容量的增加,而是来自更强的知识操纵能力。此外,LoopLM产生的推理轨迹与最终输出比显式CoT更一致,表明Ouro能够更有效地进行推理。
🎯 应用场景
Ouro具有广泛的应用前景,包括但不限于:问答系统、文本摘要、机器翻译、代码生成等。通过将推理能力融入到预训练阶段,Ouro可以提高LLM在这些任务中的性能。此外,Ouro还可以用于开发更智能的对话系统和虚拟助手,从而改善人机交互体验。未来,Ouro有望成为新一代LLM的基础模型。
📄 摘要(原文)
Modern LLMs are trained to "think" primarily via explicit text generation, such as chain-of-thought (CoT), which defers reasoning to post-training and under-leverages pre-training data. We present and open-source Ouro, named after the recursive Ouroboros, a family of pre-trained Looped Language Models (LoopLM) that instead build reasoning into the pre-training phase through (i) iterative computation in latent space, (ii) an entropy-regularized objective for learned depth allocation, and (iii) scaling to 7.7T tokens. Ouro 1.4B and 2.6B models enjoy superior performance that match the results of up to 12B SOTA LLMs across a wide range of benchmarks. Through controlled experiments, we show this advantage stems not from increased knowledge capacity, but from superior knowledge manipulation capabilities. We also show that LoopLM yields reasoning traces more aligned with final outputs than explicit CoT. We hope our results show the potential of LoopLM as a novel scaling direction in the reasoning era. Our model is available here: http://ouro-llm.github.io.