A Critical Study of Automatic Evaluation in Sign Language Translation
作者: Shakib Yazdani, Yasser Hamidullah, Cristina España-Bonet, Eleftherios Avramidis, Josef van Genabith
分类: cs.CL
发布日期: 2025-10-29 (更新: 2025-11-14)
备注: Submitted to the LREC 2026 conference
💡 一句话要点
针对手语翻译, критически 评估现有自动评估指标的局限性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 手语翻译 自动评估 文本指标 大型语言模型 多模态评估
📋 核心要点
- 现有手语翻译评估主要依赖文本指标,无法准确反映手语的语义和视觉特征。
- 论文通过控制释义、幻觉和长度等因素,系统评估了多种文本评估指标的优缺点。
- 实验表明,传统指标存在局限性,LLM评估器虽有提升但存在偏差,需多模态评估。
📝 摘要(中文)
自动评估指标对于推进手语翻译(SLT)至关重要。目前SLT的评估指标,如BLEU和ROUGE,仅基于文本,文本指标在多大程度上能够可靠地捕捉SLT输出的质量仍不清楚。为了解决这个问题,我们通过分析六种指标来研究基于文本的SLT评估指标的局限性,包括BLEU、chrF和ROUGE,以及BLEURT,以及基于大型语言模型(LLM)的评估器,如G-Eval和GEMBA零样本直接评估。具体而言,我们评估了这些指标在三种受控条件下的Consistency和鲁棒性:释义、模型输出中的幻觉以及句子长度的变化。我们的分析突出了词汇重叠指标的局限性,并表明虽然基于LLM的评估器更好地捕捉了传统指标经常遗漏的语义等价性,但它们也可能表现出对LLM释义翻译的偏见。此外,虽然所有指标都能够检测到幻觉,但BLEU往往过于敏感,而BLEURT和基于LLM的评估器对细微情况相对宽容。这促使我们需要超越基于文本的指标的多模态评估框架,以实现对手语翻译输出的更全面评估。
🔬 方法详解
问题定义:手语翻译(SLT)的自动评估依赖于文本指标,如BLEU和ROUGE,这些指标无法充分捕捉手语的视觉和语义信息。现有方法的痛点在于无法准确评估SLT的质量,导致模型优化方向可能存在偏差。
核心思路:论文的核心思路是通过系统性的实验,分析现有文本评估指标在不同情况下的表现,从而揭示其局限性。通过控制释义、幻觉和句子长度等因素,评估指标的Consistency和鲁棒性,为未来开发更有效的SLT评估方法提供依据。
技术框架:论文采用实验分析的方法,主要分为以下几个阶段: 1. 选择多种文本评估指标,包括BLEU、chrF、ROUGE、BLEURT、G-Eval和GEMBA。 2. 构建包含释义、幻觉和不同长度句子的测试数据集。 3. 使用选定的评估指标对测试数据集进行评估,并分析评估结果。 4. 对比不同指标在不同情况下的表现,总结其优缺点。
关键创新:论文的关键创新在于对现有SLT评估指标进行了全面的 критически 分析,揭示了文本指标在评估SLT质量方面的局限性。同时,论文强调了多模态评估框架的重要性,为未来SLT评估方法的研究方向提供了指导。
关键设计:论文的关键设计包括: 1. 精心设计的测试数据集,包含释义、幻觉和不同长度的句子,用于评估指标的Consistency和鲁棒性。 2. 选择具有代表性的文本评估指标,包括基于词汇重叠的指标和基于LLM的指标。 3. 采用零样本直接评估方法,评估基于LLM的评估器的性能。
🖼️ 关键图片
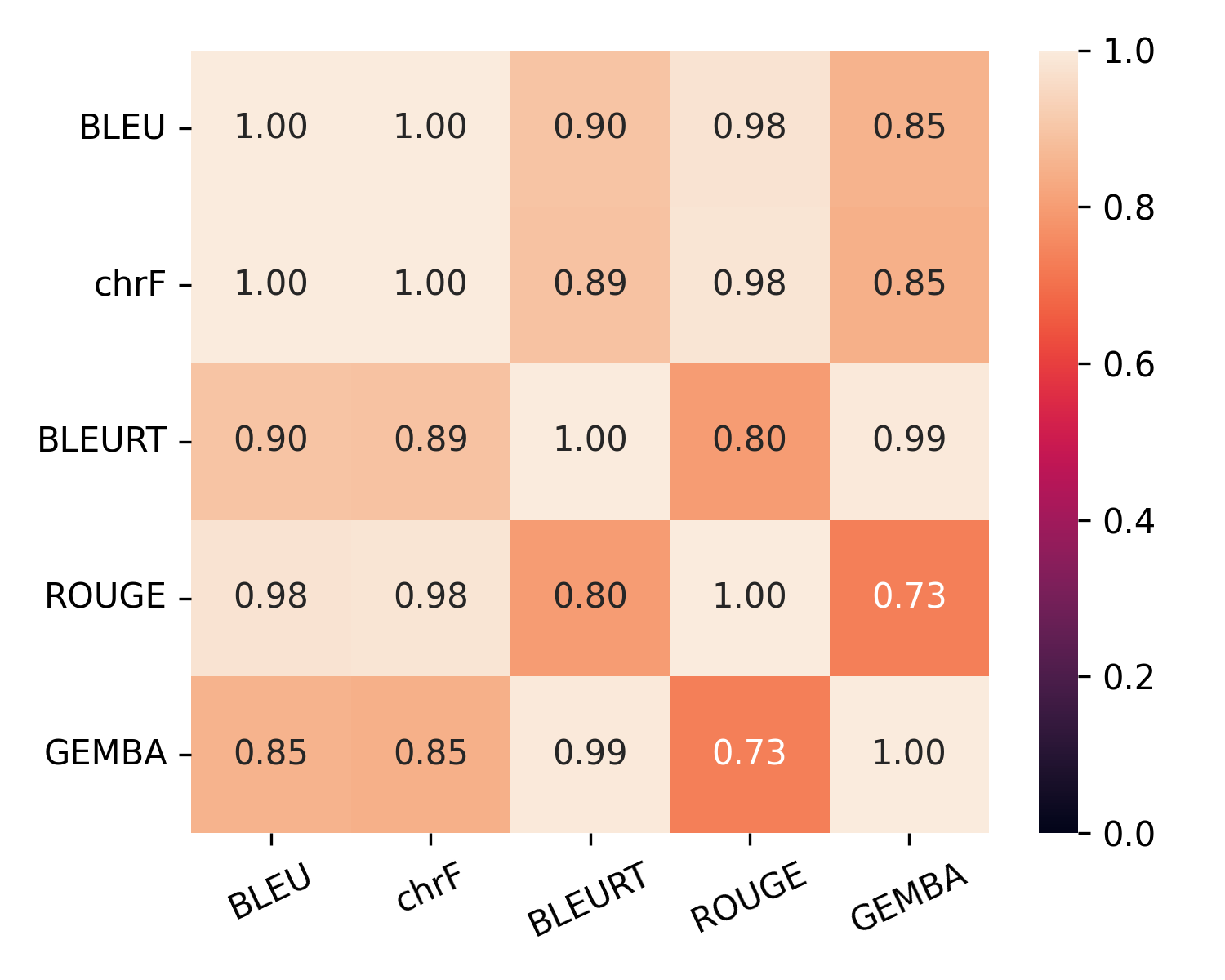


📊 实验亮点
实验结果表明,传统的词汇重叠指标(如BLEU)在评估SLT质量方面存在局限性,对释义和句子长度变化敏感。基于LLM的评估器(如G-Eval和GEMBA)在捕捉语义等价性方面有所提升,但可能存在对LLM释义翻译的偏见。所有指标都能检测到幻觉,但BLEU过于敏感,而BLEURT和LLM评估器相对宽容。
🎯 应用场景
该研究成果可应用于手语翻译系统的开发和评估,有助于提高手语翻译的质量和准确性。未来的研究可以基于此,开发多模态评估框架,更好地评估手语翻译系统的性能,促进手语交流的普及。
📄 摘要(原文)
Automatic evaluation metrics are crucial for advancing sign language translation (SLT). Current SLT evaluation metrics, such as BLEU and ROUGE, are only text-based, and it remains unclear to what extent text-based metrics can reliably capture the quality of SLT outputs. To address this gap, we investigate the limitations of text-based SLT evaluation metrics by analyzing six metrics, including BLEU, chrF, and ROUGE, as well as BLEURT on the one hand, and large language model (LLM)-based evaluators such as G-Eval and GEMBA zero-shot direct assessment on the other hand. Specifically, we assess the consistency and robustness of these metrics under three controlled conditions: paraphrasing, hallucinations in model outputs, and variations in sentence length. Our analysis highlights the limitations of lexical overlap metrics and demonstrates that while LLM-based evaluators better capture semantic equivalence often missed by conventional metrics, they can also exhibit bias toward LLM-paraphrased translations. Moreover, although all metrics are able to detect hallucinations, BLEU tends to be overly sensitive, whereas BLEURT and LLM-based evaluators are comparatively lenient toward subtle cases. This motivates the need for multimodal evaluation frameworks that extend beyond text-based metrics to enable a more holistic assessment of SLT outputs.