Serve Programs, Not Prompts
作者: In Gim, Lin Zhong
分类: cs.CL
发布日期: 2025-10-29
备注: HotOS 2025. Follow-up implementation work (SOSP 2025) is available at arXiv:2510.24051
💡 一句话要点
提出Symphony系统,通过服务LLM推理程序提升LLM服务效率与灵活性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型服务 LLM推理程序 KV缓存管理 GPU调度 系统架构
📋 核心要点
- 现有LLM服务系统主要面向文本补全,无法有效支持复杂LLM应用,存在效率和灵活性瓶颈。
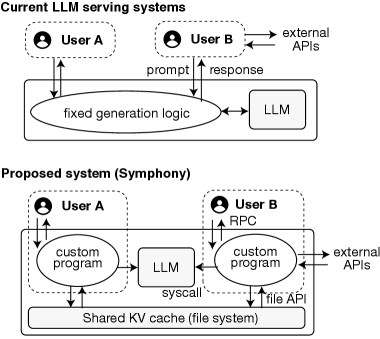
- 论文提出服务LLM推理程序(LIPs)的新架构,允许用户自定义token预测和KV缓存管理,并卸载部分应用逻辑。
- Symphony系统作为LIP的操作系统,通过系统调用暴露模型计算,虚拟化KV缓存,并采用两级调度保证GPU效率。
📝 摘要(中文)
当前的大语言模型(LLM)服务系统主要为文本补全设计,由于其设计上的不灵活性,对于日益复杂的LLM应用来说,既不高效也不具备适应性。为了解决这个问题,我们提出了一种新的LLM服务系统架构,该架构服务于程序而非提示词。这些程序被称为LLM推理程序(LIPs),允许用户在运行时自定义token预测和KV缓存管理,并将部分应用程序逻辑(例如工具执行)卸载到服务器。我们通过一个名为Symphony的系统来描述这种架构的示例,Symphony充当LIP的操作系统。Symphony通过系统调用暴露LLM模型计算,并使用专用文件系统虚拟化KV缓存,同时通过两级进程调度方案确保GPU效率。Symphony有潜力为LLM应用开启一个更高效和可扩展的生态系统。
🔬 方法详解
问题定义:现有LLM服务系统主要针对文本补全任务设计,对于需要复杂逻辑和工具调用的LLM应用,效率低下且缺乏灵活性。传统的prompt工程难以满足复杂应用的需求,且服务器端无法感知和优化用户自定义的推理流程。现有系统无法有效管理和利用KV缓存,导致资源浪费和性能瓶颈。
核心思路:论文的核心思路是将LLM服务从“服务prompt”转变为“服务程序”。通过引入LLM推理程序(LIPs)的概念,允许用户自定义推理过程,并将部分应用逻辑卸载到服务器端执行。这样可以实现更精细化的资源控制和更高效的推理流程。
技术框架:Symphony系统作为LIP的操作系统,其整体架构包含以下几个主要模块:1) LIP执行环境:负责加载和执行LIP,提供系统调用接口访问LLM模型计算和KV缓存。2) KV缓存虚拟化:通过专用文件系统虚拟化KV缓存,允许LIP按需分配和管理缓存空间。3) 两级进程调度:采用两级调度方案,首先将LIP调度到GPU上,然后在LIP内部进行细粒度的任务调度,以最大化GPU利用率。4) 系统调用接口:提供一系列系统调用接口,用于访问LLM模型计算、KV缓存管理、工具调用等功能。
关键创新:最重要的技术创新点在于将LLM服务抽象为“服务程序”,而非传统的“服务prompt”。这种转变使得用户可以自定义推理流程,并将部分应用逻辑卸载到服务器端执行,从而实现更高效和灵活的LLM服务。与现有方法的本质区别在于,Symphony系统允许服务器端感知和优化用户自定义的推理流程,而传统系统只能被动地执行prompt。
关键设计:Symphony的关键设计包括:1) LIP的编程模型:定义了LIP的编程接口和执行规范,允许用户使用高级语言编写推理程序。2) KV缓存的虚拟化机制:采用类似文件系统的接口管理KV缓存,允许LIP按需分配和释放缓存空间。3) 两级进程调度算法:设计了一种高效的两级调度算法,以最大化GPU利用率和降低推理延迟。具体的参数设置和损失函数等细节未在摘要中提及,属于未知信息。
🖼️ 关键图片

📊 实验亮点
摘要中未提供具体的实验数据和性能指标,因此无法总结实验亮点。具体性能提升幅度、对比基线等信息未知。
🎯 应用场景
该研究成果可应用于各种需要复杂推理逻辑和工具调用的LLM应用,例如智能助手、对话系统、代码生成、知识图谱推理等。通过Symphony系统,开发者可以更灵活地定制LLM推理流程,并将其与外部工具和服务集成,从而构建更强大的AI应用。该研究有望推动LLM应用生态的进一步发展。
📄 摘要(原文)
Current large language model (LLM) serving systems, primarily designed for text completion, are neither efficient nor adaptable for increasingly complex LLM applications due to their inflexible design. We propose a new LLM serving system architecture that serves programs instead of prompts to address this problem. These programs, called LLM Inference Programs (LIPs), allow users to customize token prediction and KV cache management at runtime and to offload parts of their application logic, such as tool execution, to the server. We describe an example of this architecture through a system named Symphony, which functions as an operating system for LIPs. Symphony exposes LLM model computations via system calls and virtualizes KV cache with a dedicated file system, while ensuring GPU efficiency with a two-level process scheduling scheme. Symphony has the potential to open the door to a more efficient and extensible ecosystem for LLM applications.