Parrot: A Training Pipeline Enhances Both Program CoT and Natural Language CoT for Reasoning
作者: Senjie Jin, Lu Chen, Zhiheng Xi, Yuhui Wang, Sirui Song, Yuhao Zhou, Xinbo Zhang, Peng Sun, Hong Lu, Tao Gui, Qi Zhang, Xuanjing Huang
分类: cs.CL
发布日期: 2025-10-29
💡 一句话要点
Parrot:一种训练流程,增强程序CoT和自然语言CoT的数学推理能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 数学推理 思维链 程序思维链 自然语言思维链 大语言模型
📋 核心要点
- 现有方法在增强大语言模型数学推理能力时,通常只关注自然语言CoT或程序CoT的单向增强,未能充分利用两者的互补优势。
- Parrot提出一种新颖的训练流程,通过集成顺序P-CoT和N-CoT生成、混合训练策略和辅助奖励机制,实现两种范式的相互增强。
- 实验结果表明,Parrot显著提升了N-CoT和P-CoT的性能,尤其是在N-CoT上,在MathQA数据集上取得了显著的性能提升。
📝 摘要(中文)
自然语言思维链(N-CoT)和程序思维链(P-CoT)已成为大语言模型(LLMs)解决数学推理问题的两种主要范式。目前的研究通常致力于实现单向增强:P-CoT增强N-CoT或N-CoT增强P-CoT。本文旨在充分发挥这两种范式的优势,实现相互增强,并最终实现同步改进。我们对两种范式的错误类型进行了详细分析,在此基础上,我们提出了一种用于数学问题的新型训练流程Parrot:1)三个目标设计的子任务集成了顺序P-CoT和N-CoT生成。2)一种子任务混合训练策略,以促进自然语言语义可迁移性。3)转换后的N-CoT辅助奖励旨在缓解P-CoT优化中的稀疏奖励。大量的实验表明,Parrot显著提高了N-CoT和P-CoT的性能,尤其是在N-CoT上。使用Parrot SFT,LLaMA2和CodeLLaMA的N-CoT在MathQA上的性能比资源密集型的RL基线分别提高了+21.87和+21.48。
🔬 方法详解
问题定义:现有的大语言模型在解决数学推理问题时,主要依赖于自然语言思维链(N-CoT)和程序思维链(P-CoT)。然而,现有研究通常只关注单向增强,即利用P-CoT增强N-CoT,或者反之。这种单向增强忽略了两种范式之间的互补性,未能充分发挥它们的潜力。此外,P-CoT的训练通常面临奖励稀疏的问题,影响了其优化效果。
核心思路:Parrot的核心思路是设计一个训练流程,使得N-CoT和P-CoT能够相互增强,从而实现性能的同步提升。具体来说,通过集成两种范式的生成过程,并利用N-CoT的语义信息来辅助P-CoT的优化,从而克服各自的局限性。这种相互增强的设计旨在充分利用两种范式的优势,提高模型的推理能力。
技术框架:Parrot训练流程包含三个主要子任务:1)顺序P-CoT和N-CoT生成,旨在将两种范式集成到一个统一的框架中。2)子任务混合训练策略,通过混合不同子任务的数据,促进自然语言语义的可迁移性。3)N-CoT辅助奖励,利用转换后的N-CoT信息作为P-CoT的辅助奖励,缓解P-CoT优化中的稀疏奖励问题。整体流程旨在实现N-CoT和P-CoT的协同训练和相互增强。
关键创新:Parrot的关键创新在于其相互增强的训练流程,它不同于以往的单向增强方法。通过集成P-CoT和N-CoT的生成过程,并利用N-CoT的语义信息来辅助P-CoT的优化,Parrot实现了两种范式的协同训练和相互增强。这种相互增强的设计能够充分利用两种范式的优势,提高模型的推理能力。
关键设计:在子任务混合训练策略中,论文可能使用了特定的采样比例来平衡不同子任务的数据。N-CoT辅助奖励的设计可能涉及到特定的转换函数,将N-CoT信息转换为适合P-CoT优化的奖励信号。具体的损失函数可能结合了交叉熵损失和强化学习损失,以实现监督学习和强化学习的联合优化。这些技术细节的具体实现方式在论文中可能有所描述,但在此处未知。
🖼️ 关键图片
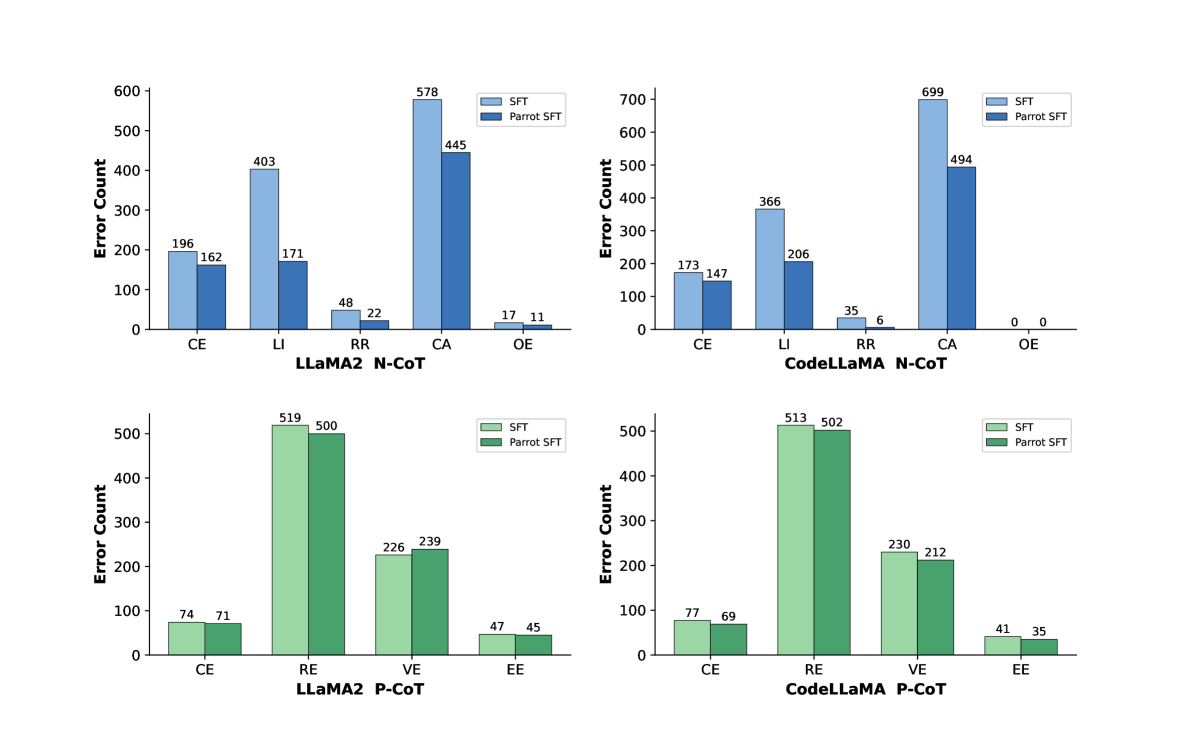

📊 实验亮点
Parrot在MathQA数据集上取得了显著的性能提升。使用Parrot SFT训练后,LLaMA2和CodeLLaMA的N-CoT性能分别提高了+21.87和+21.48,超过了资源密集型的RL基线。这些结果表明,Parrot能够有效地增强大语言模型的数学推理能力,尤其是在N-CoT方面。
🎯 应用场景
Parrot的研究成果可以应用于各种需要复杂数学推理的场景,例如自动化解题系统、智能辅导系统、科学计算等。通过提高大语言模型的数学推理能力,可以提升这些系统的智能化水平和解决问题的能力,从而在教育、科研等领域产生积极影响。未来的研究可以探索将Parrot应用于更广泛的推理任务,例如逻辑推理、常识推理等。
📄 摘要(原文)
Natural language chain-of-thought (N-CoT) and Program chain-of-thought (P-CoT) have emerged as two primary paradigms for large language models (LLMs) to solve mathematical reasoning problems. Current research typically endeavors to achieve unidirectional enhancement: P-CoT enhanced N-CoT or N-CoT enhanced P-CoT. In this paper, we seek to fully unleash the two paradigms' strengths for mutual enhancement and ultimately achieve simultaneous improvements. We conduct a detailed analysis of the error types across two paradigms, based on which we propose Parrot, a novel training pipeline for mathematical problems: 1) Three target-designed subtasks integrate sequential P-CoT and N-CoT generation. 2) A subtask hybrid training strategy to facilitate natural language semantic transferability. 3) The converted N-CoT auxiliary reward is designed to alleviate the sparse rewards in P-CoT optimization. Extensive experiments demonstrate that Parrot significantly enhances both the performance of N-CoT and P-CoT, especially on N-CoT. Using Parrot SFT, the N-CoT performance of LLaMA2 and CodeLLaMA achieve gains of +21.87 and +21.48 on MathQA over the RL baseline, which is resource-intensive.