Teaching Sarcasm: Few-Shot Multimodal Sarcasm Detection via Distillation to a Parameter-Efficient Student
作者: Soumyadeep Jana, Sanasam Ranbir Singh
分类: cs.CL
发布日期: 2025-10-29
💡 一句话要点
提出PEKD框架,通过知识蒸馏提升小样本多模态讽刺检测的参数高效微调性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态讽刺检测 小样本学习 知识蒸馏 参数高效微调 熵感知门控 深度学习 自然语言处理
📋 核心要点
- 小样本多模态讽刺检测面临数据稀缺难题,模型难以捕捉细微的图文矛盾。
- PEKD框架通过知识蒸馏,将大规模数据训练的教师模型知识迁移到参数高效的学生模型。
- 熵感知门控机制动态调整蒸馏强度,缓解教师模型噪声干扰,提升模型鲁棒性。
📝 摘要(中文)
多模态讽刺检测具有挑战性,尤其是在低资源环境下,由于标注数据稀缺,模型难以学习到细微的图文矛盾,从而影响模型性能。参数高效微调(PEFT)方法,如adapters、LoRA和prompt tuning,虽然可以减少过拟合,但由于小样本数据的监督有限,难以达到最佳性能。我们提出了PEKD,一个统一的框架,通过从大规模讽刺数据上训练的专家模型(教师模型)进行知识蒸馏来增强PEFT方法。为了减轻来自教师模型的不可靠信号的影响,我们引入了一种熵感知门控机制,该机制根据教师的置信度动态调整蒸馏强度。在两个公共数据集上的实验表明,我们的PEKD框架使PEFT方法能够超越先前的参数高效方法和大型多模态模型,在小样本场景中取得了强大的结果。该框架是模块化的,适用于各种多模态模型和任务。
🔬 方法详解
问题定义:论文旨在解决小样本多模态讽刺检测问题。现有方法,特别是参数高效微调(PEFT)方法,在数据量不足的情况下,难以充分学习到图像和文本之间的细微矛盾关系,导致模型性能受限。现有PEFT方法虽然能减少过拟合,但缺乏足够的监督信号,无法达到最优效果。
核心思路:论文的核心思路是利用知识蒸馏,将一个在大规模讽刺数据集上训练的“教师”模型的知识迁移到一个参数高效的“学生”模型。通过这种方式,学生模型可以在小样本数据集上获得更好的泛化能力,从而提高讽刺检测的准确率。同时,为了避免教师模型输出的噪声对学生模型产生负面影响,引入了熵感知门控机制。
技术框架:PEKD框架包含以下几个主要模块:1) 教师模型:一个在大规模数据集上预训练的多模态讽刺检测模型,作为知识的来源。2) 学生模型:一个采用参数高效微调(PEFT)方法(如adapters、LoRA或prompt tuning)的多模态模型,用于接收教师模型的知识。3) 知识蒸馏模块:将教师模型的输出(例如,预测概率)作为软标签,用于指导学生模型的训练。4) 熵感知门控机制:根据教师模型的预测置信度(熵)动态调整蒸馏损失的权重,降低教师模型不确定性预测的影响。
关键创新:论文的关键创新在于提出了PEKD框架,将知识蒸馏与参数高效微调相结合,并引入了熵感知门控机制。与传统的知识蒸馏方法不同,PEKD框架特别关注小样本场景下的知识迁移问题,并针对教师模型可能存在的噪声进行了优化。熵感知门控机制能够有效地过滤掉教师模型的不确定性预测,从而提高学生模型的学习效率和鲁棒性。
关键设计:熵感知门控机制是PEKD框架的关键设计之一。该机制通过计算教师模型预测概率的熵来衡量其置信度。具体来说,对于每个样本,计算教师模型预测概率分布的熵值,并将其归一化到[0, 1]区间。然后,使用一个门控函数(例如,sigmoid函数)将归一化的熵值转换为一个权重,用于调整蒸馏损失的贡献。当教师模型的预测置信度较低(熵值较高)时,门控权重会降低,从而减少该样本对学生模型训练的影响。蒸馏损失函数通常采用交叉熵损失或KL散度。
🖼️ 关键图片

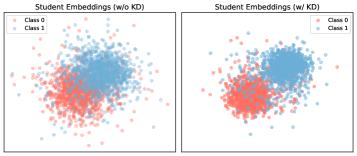
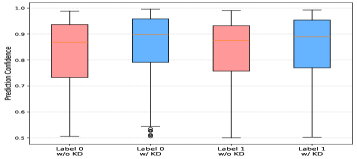
📊 实验亮点
实验结果表明,PEKD框架在两个公共数据集上显著提升了参数高效微调方法的性能。例如,在小样本设置下,PEKD框架使LoRA方法在讽刺检测准确率上提升了5%以上,超过了先前的参数高效方法和大型多模态模型。熵感知门控机制的有效性也得到了验证,能够显著降低教师模型噪声对学生模型的影响。
🎯 应用场景
该研究成果可应用于社交媒体情感分析、舆情监控、智能客服等领域。通过提高讽刺检测的准确率,可以更有效地理解用户的情感倾向,从而提升用户体验和决策支持。未来,该方法可以扩展到其他低资源多模态学习任务中,例如图像描述生成、视频摘要等。
📄 摘要(原文)
Multimodal sarcasm detection is challenging, especially in low-resource settings where subtle image-text contradictions are hard to learn due to scarce annotated data, which hinders the model's performance. Parameter-efficient fine-tuning (PEFT) methods like adapters, LoRA, and prompt tuning reduce overfitting but struggle to reach optimal performance due to limited supervision from few-shot data. We propose PEKD, a unified framework that enhances PEFT methods via distillation from an expert model trained on large-scale sarcasm data, which acts as the teacher. To mitigate unreliable signals from the teacher, we introduce an entropy-aware gating mechanism that dynamically adjusts the distillation strength based on teacher confidence. Experiments on two public datasets demonstrate that our PEKD framework enables PEFT methods to outperform both prior parameter-efficient approaches and large multimodal models, achieving strong results in the few-shot scenario. The framework is modular and adaptable to a wide range of multimodal models and tasks.