Model-Document Protocol for AI Search
作者: Hongjin Qian, Zheng Liu
分类: cs.CL, cs.AI, cs.IR
发布日期: 2025-10-29 (更新: 2025-10-30)
备注: 10 pages
💡 一句话要点
提出模型-文档协议(MDP)框架,提升LLM在AI搜索中的知识利用效率
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: AI搜索 大型语言模型 知识表示 文档处理 代理推理 信息检索 模型-文档协议 MDP-Agent
📋 核心要点
- 现有AI搜索方法难以有效利用冗长、非结构化的原始文档,导致LLM需要处理大量低质量信息。
- 提出模型-文档协议(MDP),通过代理推理、记忆 grounding 和结构化利用等途径,将原始文档转化为LLM易于理解和使用的知识表示。
- 实验表明,MDP-Agent在信息搜索任务中优于现有方法,证明了MDP框架及其代理实例的有效性。
📝 摘要(中文)
AI搜索依赖于将大型语言模型(LLM)与海量的外部知识源连接起来。然而,网页、PDF文件和其他原始文档并非天生就适合LLM使用:它们冗长、嘈杂且非结构化。传统的检索方法将这些文档视为逐字文本,并返回原始段落,将片段组装和上下文推理的负担留给了LLM。这种差距突显了对一种新的检索范式的需求,该范式重新定义了模型与文档交互的方式。我们介绍了模型-文档协议(MDP),这是一个通用框架,它形式化了如何通过可消费的知识表示将原始文本桥接到LLM。MDP不将检索视为段落获取,而是定义了多个途径,将非结构化文档转换为特定于任务的、LLM就绪的输入。这些途径包括:代理推理,将原始证据整理成连贯的上下文;记忆 grounding,积累可重用的笔记以丰富推理;以及结构化利用,将文档编码为诸如图或键值缓存之类的正式表示。所有这三个途径都具有相同的目标:确保到达LLM的不是原始片段,而是紧凑的、结构化的知识,可以直接用于推理。作为一种实例化,我们提出了MDP-Agent,它通过代理过程实现该协议:构建文档级别的要点记忆以实现全局覆盖,执行基于扩散的探索与垂直利用以发现分层依赖关系,并应用map-reduce风格的合成来将大规模证据集成到紧凑但充分的上下文中。在信息搜索基准上的实验表明,MDP-Agent优于基线,验证了MDP框架的合理性和其代理实例的有效性。
🔬 方法详解
问题定义:现有AI搜索方法在处理原始文档时,通常直接将文档片段提供给LLM,导致LLM需要处理大量冗余、噪声信息,增加了推理负担,降低了搜索效率。核心问题在于如何将原始文档转化为LLM易于理解和使用的知识表示。
核心思路:论文的核心思路是提出一个通用的模型-文档协议(MDP),该协议定义了多种途径,可以将非结构化文档转换为特定于任务的、LLM就绪的输入。这些途径包括代理推理、记忆 grounding 和结构化利用。通过这些途径,可以将原始文档中的信息进行提炼、整合和结构化,从而减少LLM需要处理的信息量,提高推理效率。
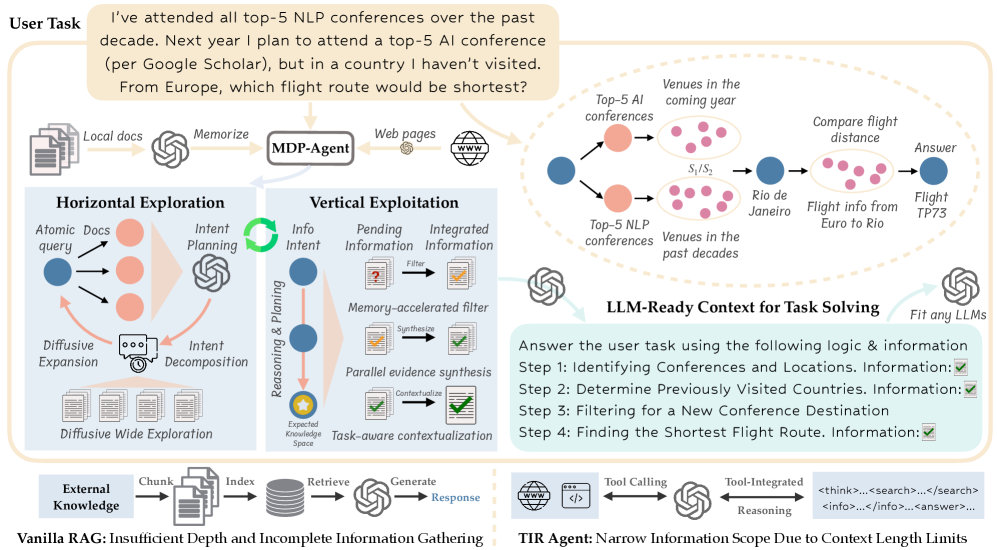
技术框架:MDP框架包含三个主要途径:1) 代理推理:利用智能体对文档进行探索和推理,提取关键信息并构建连贯的上下文。2) 记忆 grounding:积累可重用的笔记,形成知识库,用于丰富推理过程。3) 结构化利用:将文档编码为诸如图或键值缓存之类的正式表示,方便LLM进行查询和推理。MDP-Agent是MDP框架的一个具体实现,它通过代理过程实现文档处理和知识提取。
关键创新:MDP框架的关键创新在于它重新定义了模型与文档交互的方式,不再将检索视为简单的段落获取,而是通过多种途径将原始文档转化为LLM易于理解和使用的知识表示。MDP-Agent通过代理推理、扩散探索和map-reduce风格的合成等技术,实现了高效的文档处理和知识提取。
关键设计:MDP-Agent的关键设计包括:1) 文档级别要点记忆:用于全局覆盖文档信息。2) 基于扩散的探索与垂直利用:用于发现文档中的分层依赖关系。3) map-reduce风格的合成:用于将大规模证据集成到紧凑但充分的上下文中。具体参数设置、损失函数和网络结构等细节未在摘要中详细描述,属于未知信息。
🖼️ 关键图片

📊 实验亮点
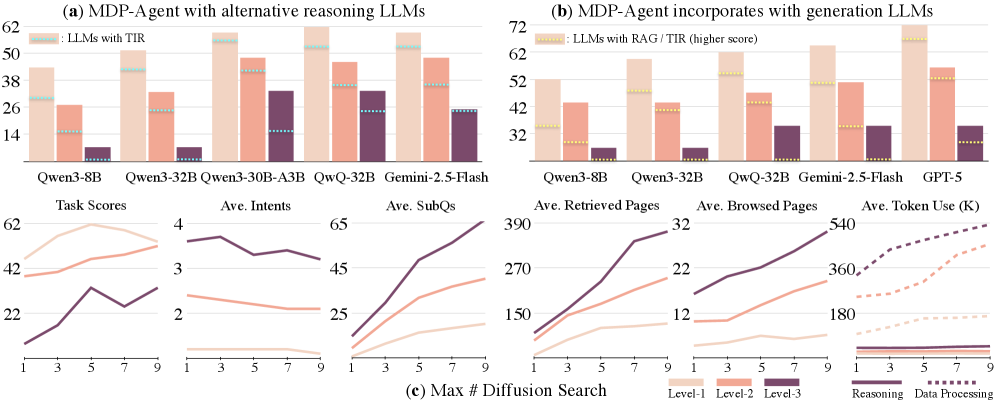
实验结果表明,MDP-Agent在信息搜索基准上优于现有方法,验证了MDP框架的有效性。具体的性能数据和提升幅度未在摘要中给出,属于未知信息。但结论表明,MDP框架及其代理实例在处理原始文档和提高LLM推理效率方面具有显著优势。
🎯 应用场景
该研究成果可应用于各种需要从海量文档中提取信息的场景,例如智能问答、知识图谱构建、信息检索等。通过将原始文档转化为LLM易于理解和使用的知识表示,可以提高AI系统的效率和准确性,为用户提供更好的服务。未来,该研究可以进一步扩展到处理多模态文档,例如包含图像、视频和音频的文档。
📄 摘要(原文)
AI search depends on linking large language models (LLMs) with vast external knowledge sources. Yet web pages, PDF files, and other raw documents are not inherently LLM-ready: they are long, noisy, and unstructured. Conventional retrieval methods treat these documents as verbatim text and return raw passages, leaving the burden of fragment assembly and contextual reasoning to the LLM. This gap underscores the need for a new retrieval paradigm that redefines how models interact with documents. We introduce the Model-Document Protocol (MDP), a general framework that formalizes how raw text is bridged to LLMs through consumable knowledge representations. Rather than treating retrieval as passage fetching, MDP defines multiple pathways that transform unstructured documents into task-specific, LLM-ready inputs. These include agentic reasoning, which curates raw evidence into coherent context; memory grounding, which accumulates reusable notes to enrich reasoning; and structured leveraging, which encodes documents into formal representations such as graphs or key-value caches. All three pathways share the same goal: ensuring that what reaches the LLM is not raw fragments but compact, structured knowledge directly consumable for reasoning. As an instantiation, we present MDP-Agent, which realizes the protocol through an agentic process: constructing document-level gist memories for global coverage, performing diffusion-based exploration with vertical exploitation to uncover layered dependencies, and applying map-reduce style synthesis to integrate large-scale evidence into compact yet sufficient context. Experiments on information-seeking benchmarks demonstrate that MDP-Agent outperforms baselines, validating both the soundness of the MDP framework and the effectiveness of its agentic instantiation.