Can LLMs Estimate Cognitive Complexity of Reading Comprehension Items?
作者: Seonjeong Hwang, Hyounghun Kim, Gary Geunbae Lee
分类: cs.CL
发布日期: 2025-10-29
💡 一句话要点
利用大型语言模型评估阅读理解题目的认知复杂度
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 阅读理解 认知复杂度 难度评估 教育应用
📋 核心要点
- 现有方法难以提取阅读理解题目中与答案推理相关的认知特征,依赖人工标注,成本高昂。
- 本研究探索利用大型语言模型评估阅读理解题目的认知复杂度,关注证据范围和转换级别两个维度。
- 实验表明,大型语言模型能够近似估计题目的认知复杂度,但元认知能力存在不足。
📝 摘要(中文)
评估阅读理解(RC)题目的认知复杂度对于在施测前评估题目难度至关重要。与段落长度或选项之间的语义相似性等句法和语义特征不同,在答案推理过程中产生的认知特征无法使用现有的NLP工具直接提取,传统上依赖于人工标注。本研究探讨了大型语言模型(LLM)是否可以通过关注两个维度——证据范围和转换级别——来估计RC题目的认知复杂度,这两个维度表明了答案推理中涉及的认知负担程度。实验结果表明,LLM可以近似估计题目的认知复杂度,表明它们有潜力作为先验难度分析的工具。进一步的分析揭示了LLM的推理能力和元认知意识之间的差距:即使它们产生了正确的答案,有时也无法正确识别其自身推理过程的潜在特征。
🔬 方法详解
问题定义:论文旨在解决阅读理解题目认知复杂度自动评估的问题。现有方法主要依赖人工标注,耗时耗力且主观性强。现有的NLP工具难以有效提取与答案推理过程相关的认知特征,例如证据范围和转换级别等,导致难以准确评估题目难度。
核心思路:论文的核心思路是利用大型语言模型(LLM)的强大推理能力,直接评估阅读理解题目的认知复杂度。通过提示工程,引导LLM分析题目所需的证据范围和转换级别,从而判断题目的认知难度。这种方法旨在减少对人工标注的依赖,实现自动化的认知复杂度评估。
技术框架:论文的技术框架主要包括以下几个步骤:1) 数据收集:收集包含阅读理解题目和对应答案的数据集。2) 特征定义:定义认知复杂度的两个维度:证据范围(Evidence Scope)和转换级别(Transformation Level)。3) 提示工程:设计合适的提示语,引导LLM分析题目并给出证据范围和转换级别的评估。4) 模型评估:将LLM的评估结果与人工标注结果进行比较,评估LLM的性能。
关键创新:论文的关键创新在于利用大型语言模型直接评估阅读理解题目的认知复杂度,避免了传统方法中对人工标注的依赖。通过关注证据范围和转换级别这两个关键维度,能够更准确地捕捉题目推理过程中的认知负担。此外,论文还发现了LLM在推理能力和元认知意识之间的差距,为后续研究提供了新的方向。
关键设计:论文的关键设计包括:1) 证据范围的定义:将证据范围分为局部和全局两种类型,分别对应于答案推理所需信息的局部性和全局性。2) 转换级别的定义:将转换级别分为直接提取和推理转换两种类型,分别对应于答案推理所需信息的直接性和间接性。3) 提示语的设计:设计清晰明确的提示语,引导LLM分析题目并给出证据范围和转换级别的评估。例如,提示语可以包含题目文本、选项以及对证据范围和转换级别的解释。
🖼️ 关键图片

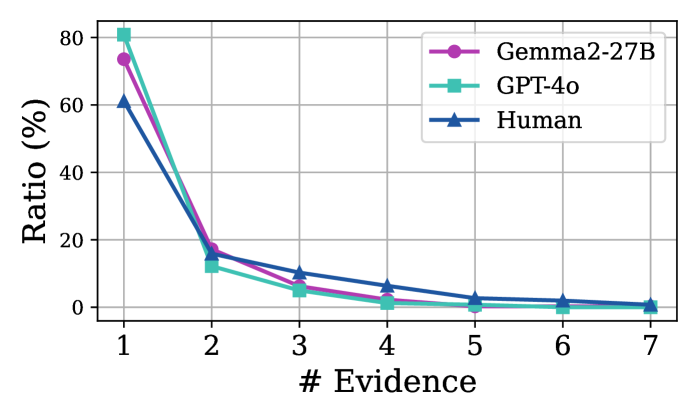

📊 实验亮点
实验结果表明,大型语言模型能够较好地估计阅读理解题目的认知复杂度,与人工标注结果具有一定的相关性。尽管LLM在生成正确答案时表现良好,但在识别自身推理过程的潜在特征方面存在不足,揭示了LLM在元认知能力方面的局限性。具体性能数据未知。
🎯 应用场景
该研究成果可应用于教育领域,辅助教师和命题者设计更科学合理的阅读理解题目,提升教学质量。通过自动评估题目难度,可以实现个性化学习和自适应测试,为学生提供更有效的学习体验。此外,该方法还可以应用于其他认知任务的难度评估,例如逻辑推理和问题解决。
📄 摘要(原文)
Estimating the cognitive complexity of reading comprehension (RC) items is crucial for assessing item difficulty before it is administered to learners. Unlike syntactic and semantic features, such as passage length or semantic similarity between options, cognitive features that arise during answer reasoning are not readily extractable using existing NLP tools and have traditionally relied on human annotation. In this study, we examine whether large language models (LLMs) can estimate the cognitive complexity of RC items by focusing on two dimensions-Evidence Scope and Transformation Level-that indicate the degree of cognitive burden involved in reasoning about the answer. Our experimental results demonstrate that LLMs can approximate the cognitive complexity of items, indicating their potential as tools for prior difficulty analysis. Further analysis reveals a gap between LLMs' reasoning ability and their metacognitive awareness: even when they produce correct answers, they sometimes fail to correctly identify the features underlying their own reasoning process.