Emergence of Minimal Circuits for Indirect Object Identification in Attention-Only Transformers
作者: Rabin Adhikari
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-10-28
备注: 9 pages, 10 figures
💡 一句话要点
训练极简注意力Transformer以解决间接对象识别任务,揭示核心推理电路
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Transformer 注意力机制 可解释性 间接对象识别 推理电路
📋 核心要点
- 大型语言模型复杂性高,难以理解其内部推理机制,阻碍了可解释性研究。
- 通过在IOI任务上训练极简Transformer,论文旨在揭示实现核心推理功能的最小电路。
- 实验表明,单层双头或双层单头注意力Transformer即可完美解决IOI任务,并能进行详细分析。
📝 摘要(中文)
机械可解释性旨在将大型语言模型(LLM)逆向工程为人类可理解的计算电路。然而,预训练模型的复杂性常常掩盖了特定推理任务所需的最小机制。本文从头开始训练小型、纯注意力Transformer,使其执行间接对象识别(IOI)任务的符号版本——这是研究Transformer中指代消解类推理的基准。令人惊讶的是,一个仅包含两头注意力的单层模型实现了完美的IOI准确率,尽管它缺少MLP和归一化层。通过残差流分解、频谱分析和嵌入干预,我们发现这两个头专门用于加性和对比子电路,共同实现IOI解析。此外,我们表明,一个两层、单头模型通过跨层查询-值交互来组合信息,从而实现类似的性能。这些结果表明,特定于任务的训练会诱导出高度可解释的最小电路,从而为探索Transformer推理的计算基础提供了一个受控的测试平台。
🔬 方法详解
问题定义:论文旨在解决Transformer模型中如何进行指代消解类推理的问题,具体表现为间接对象识别(IOI)任务。现有大型预训练模型结构复杂,难以从中提取出完成该任务的最小必要机制,可解释性差。
核心思路:论文的核心思路是通过从头开始训练小型、纯注意力Transformer模型,使其在IOI任务上达到高性能。通过控制模型的规模和结构,可以更容易地分析和理解模型内部的计算过程,从而揭示完成IOI任务所需的最小电路。
技术框架:论文采用的整体框架是训练一个或两个Transformer层,仅包含注意力机制,不使用MLP和归一化层。模型输入是符号化的IOI任务数据,输出是IOI的预测结果。通过残差流分解、频谱分析和嵌入干预等技术手段,分析模型内部不同注意力头的行为和功能。
关键创新:最重要的技术创新点在于发现仅使用极简的注意力机制(单层双头或双层单头)即可实现完美的IOI准确率。这表明完成IOI任务并不需要复杂的模型结构,而是可以通过精心设计的注意力机制来实现。
关键设计:论文的关键设计包括:1) 使用符号化的IOI任务数据,简化了输入表示;2) 训练极小的Transformer模型,降低了分析的复杂度;3) 通过残差流分解、频谱分析和嵌入干预等手段,深入分析了注意力头的行为;4) 探索了不同注意力头之间的协作方式,例如加性和对比子电路。
🖼️ 关键图片
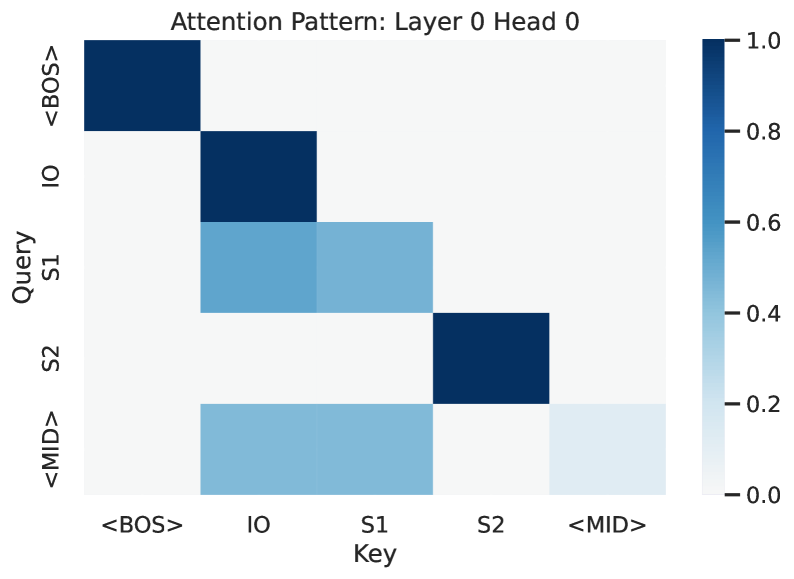
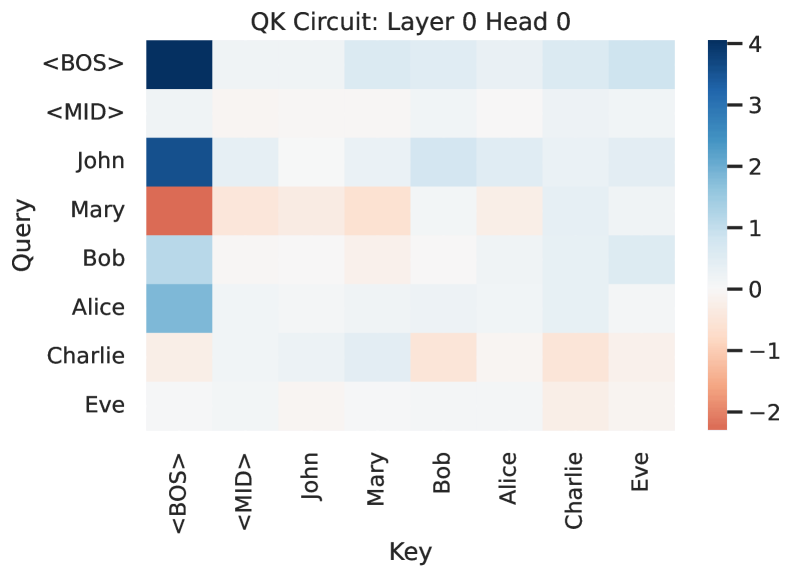

📊 实验亮点
实验结果表明,一个单层、双头注意力Transformer模型,或者一个两层、单头注意力Transformer模型,可以在IOI任务上达到完美的准确率。通过分析,发现双头模型将IOI解析分解为加性和对比子电路,而双层单头模型则通过跨层查询-值交互来组合信息。
🎯 应用场景
该研究成果可应用于开发更轻量级、可解释性更强的自然语言处理模型。通过理解Transformer模型中的核心推理机制,可以设计更高效的模型架构,并提高模型的可控性和可靠性。此外,该方法也为研究其他复杂推理任务提供了新的思路。
📄 摘要(原文)
Mechanistic interpretability aims to reverse-engineer large language models (LLMs) into human-understandable computational circuits. However, the complexity of pretrained models often obscures the minimal mechanisms required for specific reasoning tasks. In this work, we train small, attention-only transformers from scratch on a symbolic version of the Indirect Object Identification (IOI) task -- a benchmark for studying coreference -- like reasoning in transformers. Surprisingly, a single-layer model with only two attention heads achieves perfect IOI accuracy, despite lacking MLPs and normalization layers. Through residual stream decomposition, spectral analysis, and embedding interventions, we find that the two heads specialize into additive and contrastive subcircuits that jointly implement IOI resolution. Furthermore, we show that a two-layer, one-head model achieves similar performance by composing information across layers through query-value interactions. These results demonstrate that task-specific training induces highly interpretable, minimal circuits, offering a controlled testbed for probing the computational foundations of transformer reasoning.