POWSM: A Phonetic Open Whisper-Style Speech Foundation Model
作者: Chin-Jou Li, Kalvin Chang, Shikhar Bharadwaj, Eunjung Yeo, Kwanghee Choi, Jian Zhu, David Mortensen, Shinji Watanabe
分类: cs.CL, eess.AS
发布日期: 2025-10-28 (更新: 2026-01-16)
备注: 18 pages, under review. Model available at https://huggingface.co/espnet/powsm
💡 一句话要点
提出POWSM:一个语音开放Whisper风格的语音基础模型,统一解决多种语音音素相关任务
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语音基础模型 多任务学习 音素识别 字形-音素转换 音素-字形转换 自动语音识别 低资源语音处理 Transformer
📋 核心要点
- 现有语音处理在音素任务上各自孤立,依赖于特定架构和数据集,缺乏统一性。
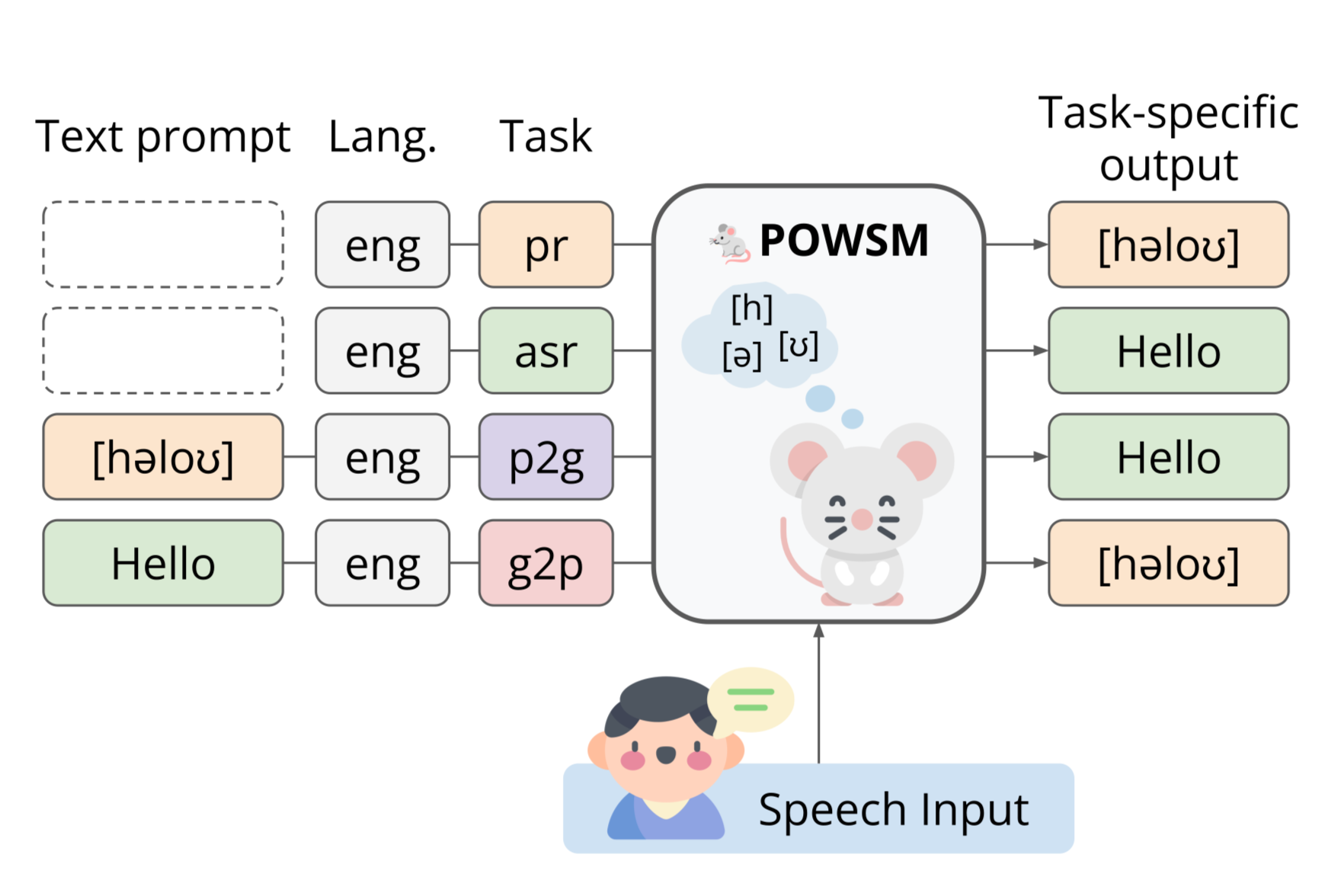
- POWSM通过统一框架,实现音频、文本和音素之间的转换,支持多种音素相关任务的联合处理。
- 实验表明,POWSM在音素识别上达到或超过专用模型水平,同时支持G2P、P2G和ASR。
📝 摘要(中文)
本文介绍POWSM(Phonetic Open Whisper-style Speech Model),这是首个能够联合执行多个音素相关任务的统一框架。POWSM实现了音频、文本(字形)和音素之间的无缝转换,为通用和低资源语音处理开辟了新的可能性。我们的模型在联合支持字形-音素转换(G2P)、音素-字形转换(P2G)和自动语音识别(ASR)的同时,性能优于或匹配了类似大小的专用音素识别(PR)模型(Wav2Vec2Phoneme和ZIPA)。我们发布了训练数据、代码和模型,以促进开放科学。
🔬 方法详解
问题定义:现有语音处理方法在处理自动语音识别(ASR)、音素识别(PR)、字形-音素转换(G2P)和音素-字形转换(P2G)等任务时,通常采用孤立的方式,即每个任务都依赖于特定的模型架构和数据集。这种方式缺乏通用性,且难以在低资源场景下有效工作。现有方法的痛点在于无法利用不同任务之间的关联性,导致模型效率低下,泛化能力受限。
核心思路:POWSM的核心思路是构建一个统一的语音基础模型,该模型能够同时处理多种音素相关的任务。通过共享底层表示和学习不同任务之间的关联性,POWSM旨在提高模型在各个任务上的性能,并实现跨任务的知识迁移。这种统一框架的设计使得模型能够更好地适应低资源场景,并为通用语音处理提供新的可能性。
技术框架:POWSM的技术框架基于Transformer架构,并采用了类似于OpenAI Whisper的训练方式。整体流程包括:1)数据预处理:对音频数据进行特征提取,例如梅尔频谱;对文本数据进行分词或字形编码;对音素数据进行音素编码。2)模型训练:使用大规模语音数据集进行预训练,目标是学习通用的语音表示。在预训练阶段,模型学习音频、文本和音素之间的映射关系。3)任务微调:在特定任务上进行微调,例如ASR、G2P、P2G或PR。通过微调,模型能够更好地适应特定任务的需求。
关键创新:POWSM的关键创新在于其统一的框架设计,能够同时处理多种音素相关的任务。与现有方法相比,POWSM不再需要为每个任务单独设计模型,而是通过一个统一的模型来实现多个任务。这种统一框架的设计使得模型能够更好地利用不同任务之间的关联性,提高模型在各个任务上的性能。此外,POWSM还采用了类似于OpenAI Whisper的训练方式,利用大规模语音数据集进行预训练,从而学习通用的语音表示。
关键设计:POWSM的关键设计包括:1)Transformer架构:采用Transformer作为模型的基础架构,利用其强大的序列建模能力。2)多任务学习:通过多任务学习的方式,同时训练模型处理多个音素相关的任务。3)大规模预训练:利用大规模语音数据集进行预训练,学习通用的语音表示。4)类似于Whisper的训练方式:借鉴OpenAI Whisper的训练方式,例如使用自监督学习和数据增强技术。5)损失函数:针对不同的任务,采用不同的损失函数,例如交叉熵损失函数用于分类任务,连接时序分类(CTC)损失函数用于ASR任务。
🖼️ 关键图片
📊 实验亮点
POWSM在音素识别任务上取得了与专用模型(如Wav2Vec2Phoneme和ZIPA)相当或更优的性能,同时还支持G2P、P2G和ASR等任务。这表明POWSM的统一框架具有很强的竞争力,能够在多个任务上实现良好的性能。此外,POWSM的训练数据、代码和模型已开源,为语音研究领域提供了宝贵的资源。
🎯 应用场景
POWSM具有广泛的应用前景,包括语音识别、语音合成、语音翻译、语音搜索等领域。尤其在低资源语音处理方面,POWSM的统一框架和跨任务学习能力使其能够更好地适应资源匮乏的场景。此外,POWSM还可以用于开发新的语音应用,例如语音辅助学习、语音游戏等,具有重要的实际价值和未来影响。
📄 摘要(原文)
Recent advances in spoken language processing have led to substantial progress in phonetic tasks such as automatic speech recognition (ASR), phone recognition (PR), grapheme-to-phoneme conversion (G2P), and phoneme-to-grapheme conversion (P2G). Despite their conceptual similarity, these tasks have largely been studied in isolation, each relying on task-specific architectures and datasets. In this paper, we introduce POWSM (Phonetic Open Whisper-style Speech Model), the first unified framework capable of jointly performing multiple phone-related tasks. POWSM enables seamless conversion between audio, text (graphemes), and phones, opening up new possibilities for universal and low-resource speech processing. Our model outperforms or matches specialized PR models of similar size (Wav2Vec2Phoneme and ZIPA) while jointly supporting G2P, P2G, and ASR. Our training data, code and models are released to foster open science.