Seeing Through the MiRAGE: Evaluating Multimodal Retrieval Augmented Generation
作者: Alexander Martin, William Walden, Reno Kriz, Dengjia Zhang, Kate Sanders, Eugene Yang, Chihsheng Jin, Benjamin Van Durme
分类: cs.CL, cs.CV, cs.IR
发布日期: 2025-10-28
备注: https://github.com/alexmartin1722/mirage
💡 一句话要点
提出MiRAGE框架,用于评估多模态检索增强生成系统的性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态RAG 检索增强生成 多模态评估 信息检索 事实性评估
📋 核心要点
- 现有RAG评估主要集中于文本,无法有效评估处理视听等多模态信息时的推理和信息验证能力。
- MiRAGE框架通过InfoF1和CiteF1指标,从事实性、信息覆盖率、引用支持和完整性等多维度评估多模态RAG系统。
- 实验表明,人工评估的MiRAGE与人类的质量判断高度一致,并揭示了现有文本中心评估方法的局限性。
📝 摘要(中文)
本文介绍了一个名为MiRAGE的评估框架,用于评估来自多模态源的检索增强生成(RAG)系统。随着视听媒体成为在线信息的主要来源,RAG系统必须能够将这些来源的信息整合到生成过程中。然而,现有的RAG评估方法以文本为中心,限制了它们在多模态、推理密集型环境中的适用性,因为它们不验证信息来源。MiRAGE是一种以声明为中心的多模态RAG评估方法,包含InfoF1(评估事实性和信息覆盖率)和CiteF1(衡量引用支持和完整性)。研究表明,当由人工应用时,MiRAGE与外部质量判断高度一致。此外,本文还介绍了MiRAGE的自动变体以及三个著名的TextRAG指标——ACLE、ARGUE和RAGAS,展示了以文本为中心的工作的局限性,并为自动评估奠定了基础。本文发布了开源实现,并概述了如何评估多模态RAG。
🔬 方法详解
问题定义:现有的检索增强生成(RAG)评估方法主要集中于文本数据,缺乏对多模态数据(如视频、音频)的处理和评估能力。这导致无法有效评估RAG系统在处理和整合多模态信息时的性能,尤其是在需要进行复杂推理和信息验证的场景下。现有方法无法验证生成内容与多模态信息源的一致性,容易产生幻觉和不准确的信息。
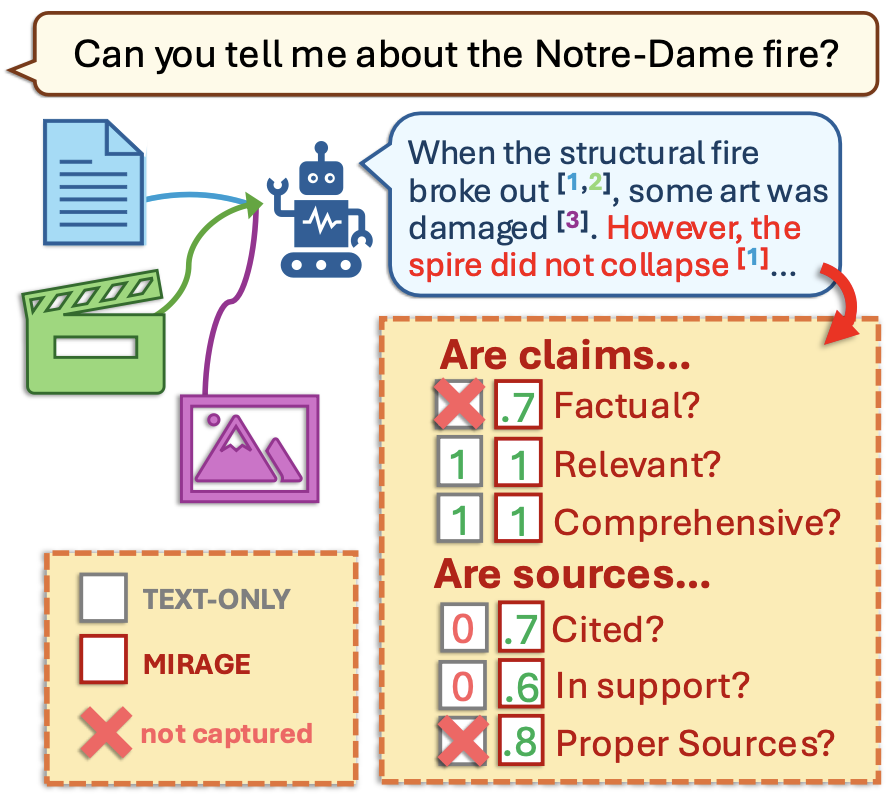
核心思路:MiRAGE的核心思路是以“声明(claim)”为中心进行评估。它首先识别生成内容中的关键声明,然后评估这些声明是否与检索到的多模态信息源相符。通过这种方式,MiRAGE能够更准确地衡量RAG系统在多模态环境下的事实性、信息覆盖率和引用支持。
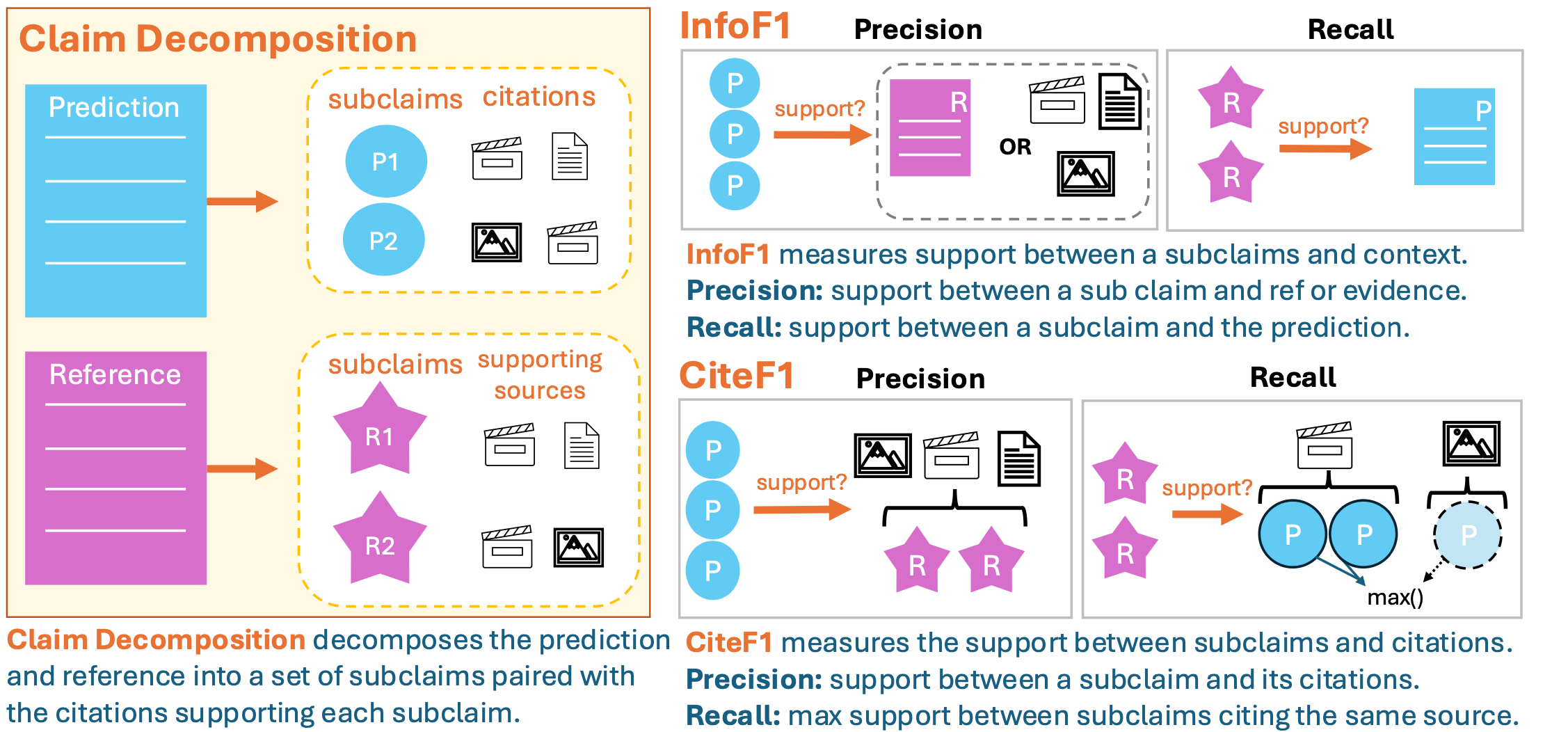
技术框架:MiRAGE框架包含以下主要模块: 1. 声明提取:从RAG系统生成的文本中提取关键声明。 2. 信息检索:利用RAG系统检索到的多模态信息源。 3. 信息验证:将提取的声明与检索到的信息源进行比对,判断声明的真实性和完整性。 4. 指标计算:计算InfoF1和CiteF1指标,评估RAG系统的性能。
关键创新:MiRAGE最重要的创新在于其以声明为中心的评估方法,这与传统的以文本为中心的评估方法有本质区别。MiRAGE能够更准确地评估RAG系统在多模态环境下的信息整合和推理能力,避免了传统方法容易忽略的幻觉问题。此外,MiRAGE还提供了自动评估变体,降低了评估成本。
关键设计:MiRAGE的关键设计包括: * InfoF1:用于评估生成内容的事实性和信息覆盖率,通过计算声明与信息源之间的精确率和召回率来衡量。 * CiteF1:用于评估引用支持和完整性,衡量生成内容是否正确引用了相关的信息源。 * 自动评估变体:利用自然语言处理技术自动提取声明、检索信息和验证信息,从而降低评估成本。
🖼️ 关键图片
📊 实验亮点
实验结果表明,人工评估的MiRAGE与人类的质量判断高度一致,验证了其有效性。同时,MiRAGE揭示了现有文本中心评估方法在多模态RAG评估中的局限性。自动MiRAGE变体为大规模评估多模态RAG系统提供了可能。
🎯 应用场景
MiRAGE框架可应用于评估各种多模态RAG系统,例如视频问答、多模态文档摘要等。它有助于开发者识别和改进RAG系统在处理多模态信息时的不足,提高生成内容的质量和可靠性。该研究对提升多模态信息检索和生成领域的整体水平具有重要意义。
📄 摘要(原文)
We introduce MiRAGE, an evaluation framework for retrieval-augmented generation (RAG) from multimodal sources. As audiovisual media becomes a prevalent source of information online, it is essential for RAG systems to integrate information from these sources into generation. However, existing evaluations for RAG are text-centric, limiting their applicability to multimodal, reasoning intensive settings because they don't verify information against sources. MiRAGE is a claim-centric approach to multimodal RAG evaluation, consisting of InfoF1, evaluating factuality and information coverage, and CiteF1, measuring citation support and completeness. We show that MiRAGE, when applied by humans, strongly aligns with extrinsic quality judgments. We additionally introduce automatic variants of MiRAGE and three prominent TextRAG metrics -- ACLE, ARGUE, and RAGAS -- demonstrating the limitations of text-centric work and laying the groundwork for automatic evaluation. We release open-source implementations and outline how to assess multimodal RAG.