Do Large Language Models Grasp The Grammar? Evidence from Grammar-Book-Guided Probing in Luxembourgish
作者: Lujun Li, Yewei Song, Lama Sleem, Yiqun Wang, Yangjie Xu, Cedric Lothritz, Niccolo Gentile, Radu State, Tegawende F. Bissyande, Jacques Klein
分类: cs.CL
发布日期: 2025-10-28
💡 一句话要点
提出基于语法书指导的评测框架,评估大语言模型对卢森堡语语法的理解能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 语法评估 低资源语言 卢森堡语 机器翻译
📋 核心要点
- 自然语言处理领域缺乏针对语法的评估协议,尤其是在低资源语言方面,这是一个显著的差距。
- 论文提出了一种基于语法书指导的评估流程,旨在系统地评估大语言模型对语法的理解能力,并以卢森堡语为例进行了研究。
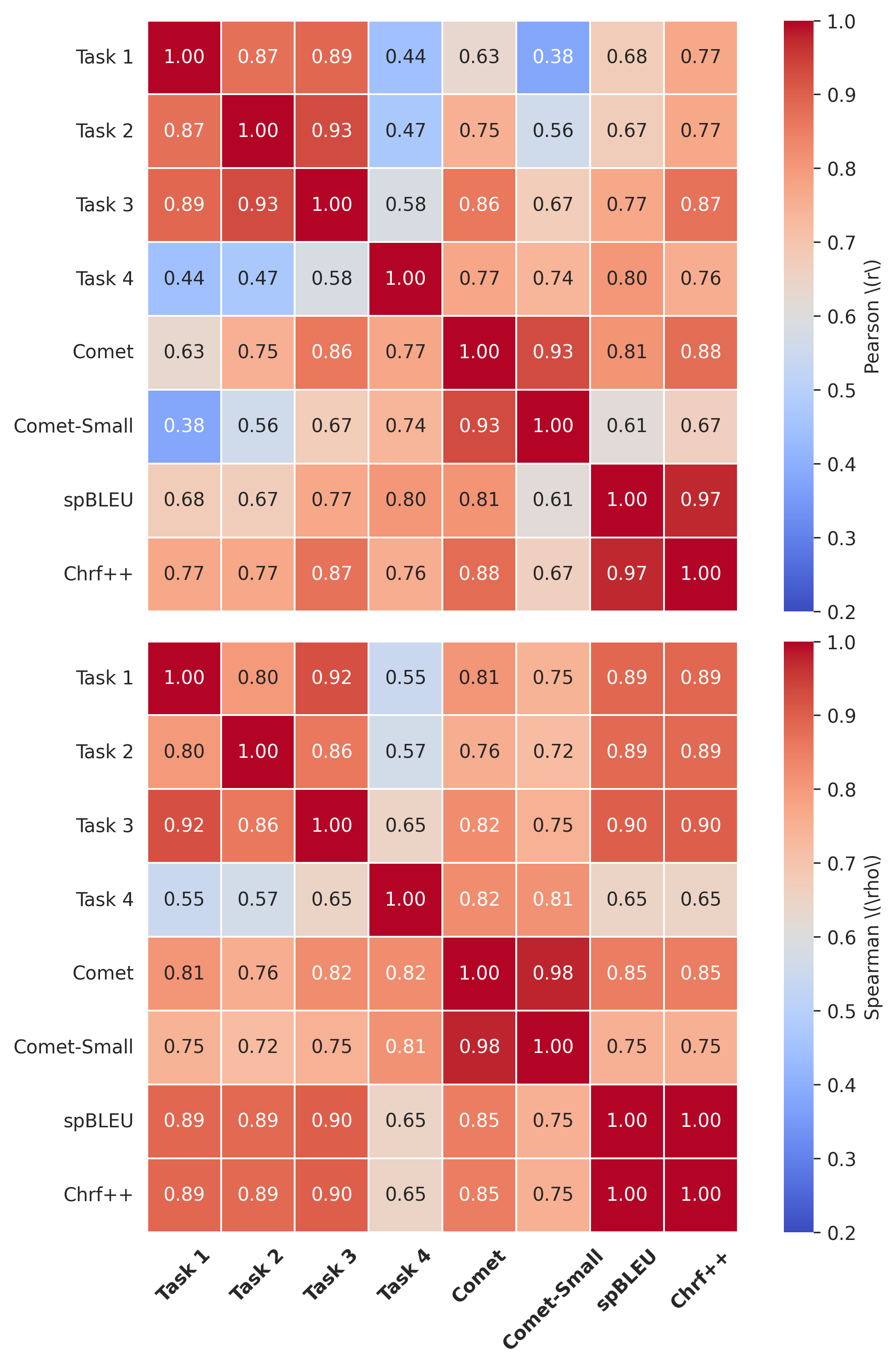
- 实验结果表明,翻译性能与语法理解之间相关性较弱,且大型模型在形态学和句法方面存在不足,但推理能力有望提升语法理解。
📝 摘要(中文)
本文提出了一种基于语法书指导的评估流程,旨在为语法评估提供一个系统且通用的框架。该框架包含四个关键阶段,并以卢森堡语作为案例研究。研究结果表明,翻译性能与语法理解之间存在微弱的正相关关系,这意味着强大的翻译能力并不一定意味着对语法的深刻理解。更大的模型由于其语义强度而表现良好,但在形态学和句法方面仍然较弱,尤其是在最小对任务中表现不佳。强大的推理能力为提高其语法理解能力提供了一种有希望的途径。
🔬 方法详解
问题定义:论文旨在解决大语言模型(LLM)是否真正理解语法结构,特别是句法结构和语义之间的映射关系的问题。现有方法缺乏针对语法的系统性评估,尤其是在低资源语言上。现有方法无法有效区分LLM是通过死记硬背还是真正理解语法规则来进行翻译或生成文本。
核心思路:论文的核心思路是构建一个基于语法书指导的评估流程,该流程能够系统性地测试LLM在不同语法规则上的表现。通过将LLM的输出与语法书中的规则进行对比,从而判断LLM是否真正理解了语法。这种方法避免了仅仅依赖翻译质量来评估语法理解的局限性。
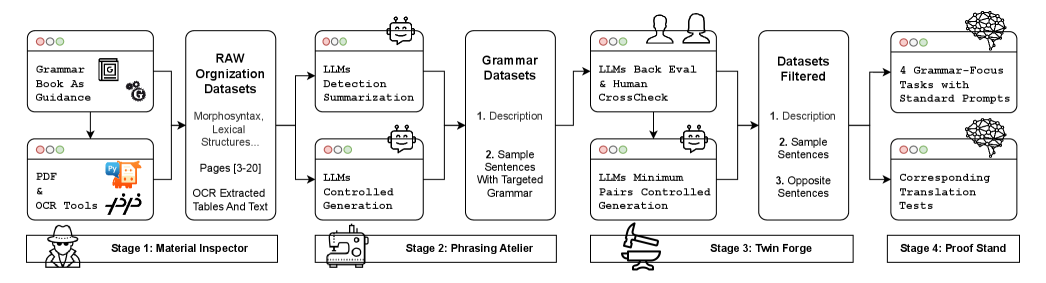
技术框架:该评估流程包含四个关键阶段:1) 语法规则提取:从卢森堡语语法书中提取需要评估的语法规则。2) 测试用例生成:基于提取的语法规则,生成相应的测试用例,包括正例和反例。3) 模型预测:使用LLM对测试用例进行预测,例如进行翻译或判断句子是否符合语法。4) 结果评估:将LLM的预测结果与标准答案进行对比,评估LLM对语法规则的理解程度。
关键创新:该论文的关键创新在于提出了一个通用的、系统性的语法评估框架,该框架可以应用于不同的语言和不同的语法规则。该框架不仅仅关注翻译质量,而是直接评估LLM对语法规则的理解程度。此外,该框架还特别关注低资源语言的语法评估,填补了该领域的空白。
关键设计:论文的关键设计包括:1) 语法书的选择:选择权威的卢森堡语语法书作为评估的依据。2) 测试用例的多样性:生成包含不同语法规则和不同难度的测试用例。3) 评估指标的合理性:设计能够有效反映LLM语法理解程度的评估指标,例如准确率、召回率和F1值。4) 最小对任务的设计:通过设计最小对任务,更精确地评估LLM对细微语法差异的敏感度。
🖼️ 关键图片

📊 实验亮点
实验结果表明,大型模型在语义理解方面表现良好,但在形态学和句法方面仍然存在不足,尤其是在最小对任务中表现不佳。翻译性能与语法理解之间存在微弱的正相关关系,表明翻译能力强并不一定意味着对语法的深刻理解。研究还发现,强大的推理能力有望提升LLM的语法理解能力。
🎯 应用场景
该研究成果可应用于提升机器翻译质量,尤其是在低资源语言的翻译中。通过评估和改进LLM的语法理解能力,可以提高机器翻译的准确性和流畅性。此外,该研究还可以用于开发更智能的语言学习工具,帮助学习者更好地掌握语法规则。未来,该方法可以推广到其他语言,构建更全面的语法评估体系。
📄 摘要(原文)
Grammar refers to the system of rules that governs the structural organization and the semantic relations among linguistic units such as sentences, phrases, and words within a given language. In natural language processing, there remains a notable scarcity of grammar focused evaluation protocols, a gap that is even more pronounced for low-resource languages. Moreover, the extent to which large language models genuinely comprehend grammatical structure, especially the mapping between syntactic structures and meanings, remains under debate. To investigate this issue, we propose a Grammar Book Guided evaluation pipeline intended to provide a systematic and generalizable framework for grammar evaluation consisting of four key stages, and in this work we take Luxembourgish as a case study. The results show a weak positive correlation between translation performance and grammatical understanding, indicating that strong translations do not necessarily imply deep grammatical competence. Larger models perform well overall due to their semantic strength but remain weak in morphology and syntax, struggling particularly with Minimal Pair tasks, while strong reasoning ability offers a promising way to enhance their grammatical understanding.