Tongyi DeepResearch Technical Report
作者: Tongyi DeepResearch Team, Baixuan Li, Bo Zhang, Dingchu Zhang, Fei Huang, Guangyu Li, Guoxin Chen, Huifeng Yin, Jialong Wu, Jingren Zhou, Kuan Li, Liangcai Su, Litu Ou, Liwen Zhang, Pengjun Xie, Rui Ye, Wenbiao Yin, Xinmiao Yu, Xinyu Wang, Xixi Wu, Xuanzhong Chen, Yida Zhao, Zhen Zhang, Zhengwei Tao, Zhongwang Zhang, Zile Qiao, Chenxi Wang, Donglei Yu, Gang Fu, Haiyang Shen, Jiayin Yang, Jun Lin, Junkai Zhang, Kui Zeng, Li Yang, Hailong Yin, Maojia Song, Ming Yan, Minpeng Liao, Peng Xia, Qian Xiao, Rui Min, Ruixue Ding, Runnan Fang, Shaowei Chen, Shen Huang, Shihang Wang, Shihao Cai, Weizhou Shen, Xiaobin Wang, Xin Guan, Xinyu Geng, Yingcheng Shi, Yuning Wu, Zhuo Chen, Zijian Li, Yong Jiang
分类: cs.CL, cs.AI, cs.IR, cs.LG, cs.MA
发布日期: 2025-10-28 (更新: 2025-11-04)
备注: https://tongyi-agent.github.io/blog
💡 一句话要点
提出 Tongyi DeepResearch,一个面向长程深度信息检索任务的 Agentic 大语言模型。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Agentic 大语言模型 深度信息检索 长程推理 自主研究 数据合成
📋 核心要点
- 现有方法在长程深度信息检索任务中面临推理能力和可扩展性挑战。
- Tongyi DeepResearch 采用 Agentic 训练框架,结合中期和后期训练,提升自主研究能力。
- 通过全自动数据合成流水线和定制环境,实现稳定高效的训练,并在多个基准测试中取得领先。
📝 摘要(中文)
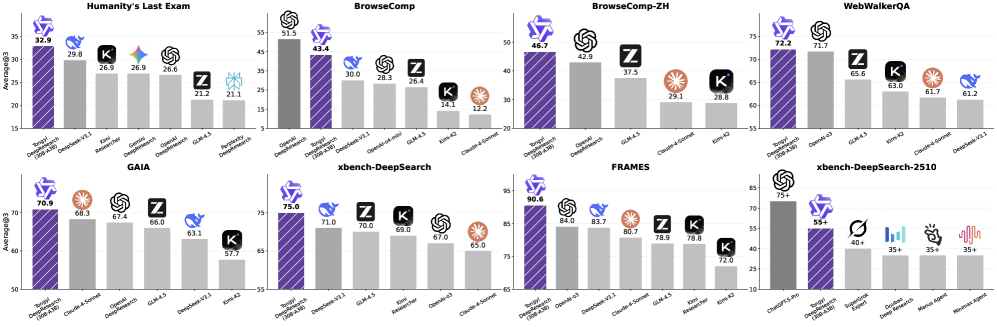
本文介绍了 Tongyi DeepResearch,一个专为长程、深度信息检索研究任务设计的 Agentic 大语言模型。为了激励自主深度研究能力,Tongyi DeepResearch 通过结合 Agentic 中期训练和 Agentic 后期训练的端到端训练框架开发,从而能够在复杂任务中实现可扩展的推理和信息检索。我们设计了一个高度可扩展的数据合成流水线,该流水线是完全自动化的,不依赖于昂贵的人工标注,并支持所有训练阶段。通过为每个阶段构建定制环境,我们的系统能够在整个过程中实现稳定和一致的交互。Tongyi DeepResearch 总参数量为 305 亿,但每个 token 仅激活 33 亿参数,在包括 Humanity's Last Exam、BrowseComp、BrowseComp-ZH、WebWalkerQA、xbench-DeepSearch、FRAMES 和 xbench-DeepSearch-2510 在内的一系列 Agentic 深度研究基准测试中实现了最先进的性能。我们开源了模型、框架和完整解决方案,以赋能社区。
🔬 方法详解
问题定义:现有的大语言模型在处理需要长时间推理和深度信息检索的任务时,往往面临推理能力不足和难以扩展的问题。人工标注成本高昂,限制了训练数据的规模和多样性。
核心思路:Tongyi DeepResearch 的核心思路是构建一个能够自主进行深度研究的 Agentic 大语言模型。通过端到端的训练框架,模型能够学习如何在复杂环境中进行推理、信息检索和决策,从而完成长程研究任务。
技术框架:Tongyi DeepResearch 的整体框架包括数据合成、Agentic 中期训练和 Agentic 后期训练三个主要阶段。数据合成阶段负责生成大规模的训练数据,Agentic 中期训练用于提升模型的基础推理能力,Agentic 后期训练则专注于优化模型在特定研究任务中的表现。每个阶段都配备了定制的环境,以确保训练的稳定性和一致性。
关键创新:Tongyi DeepResearch 的关键创新在于其 Agentic 训练框架和全自动数据合成流水线。Agentic 训练框架能够有效地提升模型的自主研究能力,而全自动数据合成流水线则解决了训练数据规模和多样性的问题,降低了人工标注的成本。
关键设计:Tongyi DeepResearch 采用了 305 亿参数的模型,但每个 token 仅激活 33 亿参数,从而在保证性能的同时降低了计算成本。数据合成流水线采用了多种策略来生成高质量的训练数据,包括问题生成、答案生成和环境模拟等。Agentic 训练框架则采用了强化学习等技术来优化模型的决策能力。
🖼️ 关键图片


📊 实验亮点
Tongyi DeepResearch 在 Humanity's Last Exam、BrowseComp、BrowseComp-ZH、WebWalkerQA、xbench-DeepSearch、FRAMES 和 xbench-DeepSearch-2510 等多个 Agentic 深度研究基准测试中取得了最先进的性能,证明了其在长程深度信息检索任务中的优越性。
🎯 应用场景
Tongyi DeepResearch 可应用于科学研究、市场分析、政策制定等领域,帮助研究人员和决策者更高效地获取和分析信息,从而做出更明智的决策。该模型有望加速知识发现和创新,并为各行各业带来实际价值。
📄 摘要(原文)
We present Tongyi DeepResearch, an agentic large language model, which is specifically designed for long-horizon, deep information-seeking research tasks. To incentivize autonomous deep research agency, Tongyi DeepResearch is developed through an end-to-end training framework that combines agentic mid-training and agentic post-training, enabling scalable reasoning and information seeking across complex tasks. We design a highly scalable data synthesis pipeline that is fully automatic, without relying on costly human annotation, and empowers all training stages. By constructing customized environments for each stage, our system enables stable and consistent interactions throughout. Tongyi DeepResearch, featuring 30.5 billion total parameters, with only 3.3 billion activated per token, achieves state-of-the-art performance across a range of agentic deep research benchmarks, including Humanity's Last Exam, BrowseComp, BrowseComp-ZH, WebWalkerQA, xbench-DeepSearch, FRAMES and xbench-DeepSearch-2510. We open-source the model, framework, and complete solutions to empower the community.