AgentFrontier: Expanding the Capability Frontier of LLM Agents with ZPD-Guided Data Synthesis
作者: Xuanzhong Chen, Zile Qiao, Guoxin Chen, Liangcai Su, Zhen Zhang, Xinyu Wang, Pengjun Xie, Fei Huang, Jingren Zhou, Yong Jiang
分类: cs.CL
发布日期: 2025-10-28
备注: https://tongyi-agent.github.io/blog/introducing-tongyi-deep-research/
💡 一句话要点
AgentFrontier:利用ZPD引导的数据合成扩展LLM Agent的能力边界
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM Agent 最近发展区 数据合成 能力边界 自动化基准
📋 核心要点
- 现有LLM Agent在能力边界上的任务处理能力不足,限制了其高级推理能力的发挥。
- 论文提出AgentFrontier Engine,通过ZPD引导的数据合成,生成位于LLM能力边界的高质量数据。
- 实验表明,使用合成数据训练的AgentFrontier-30B-A3B模型在多个基准测试中取得了SOTA结果。
📝 摘要(中文)
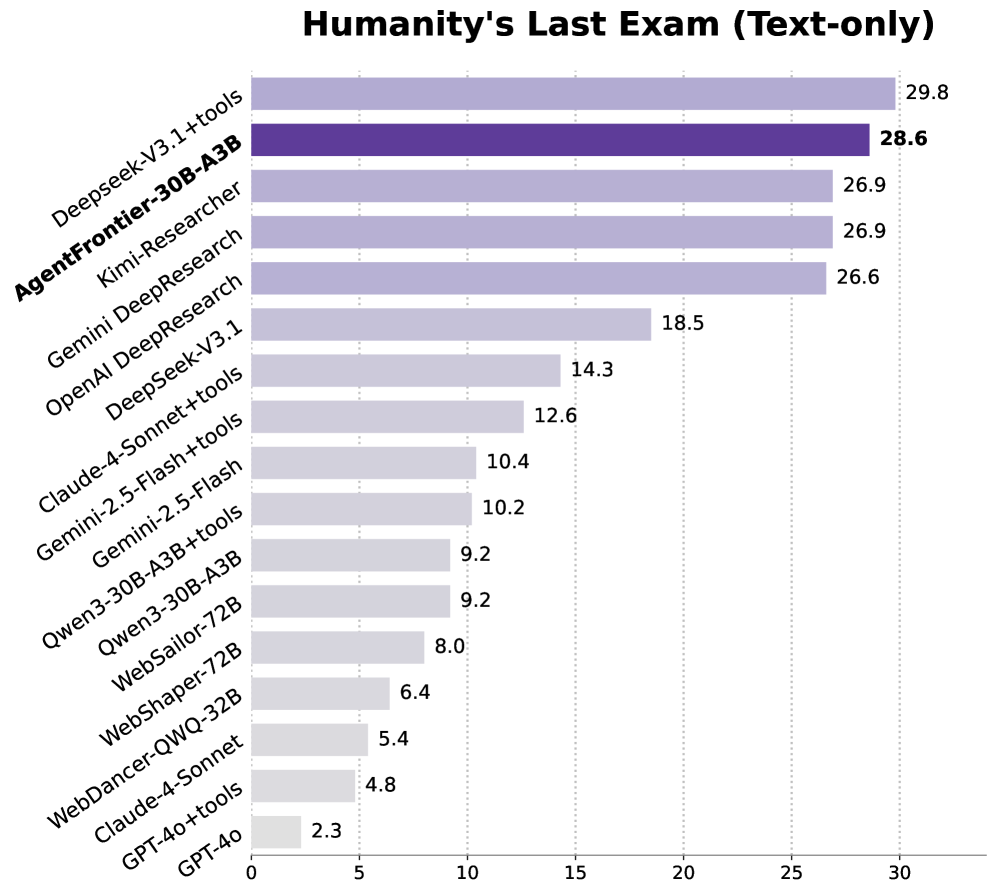
本文提出了一种受教育理论“最近发展区(ZPD)”启发的数据合成方法,旨在训练大语言模型Agent,使其能够处理能力边界上的任务,从而解锁高级推理能力。ZPD将能力边界定义为LLM无法独立解决但可以通过指导掌握的任务。为此,作者提出了AgentFrontier Engine,这是一个自动化流程,用于合成高质量、多学科的数据,这些数据精确地位于LLM的ZPD内。该引擎支持使用知识密集型数据进行持续预训练,以及针对复杂推理任务的定向后训练。此外,该框架还衍生出ZPD Exam,这是一个动态且自动化的基准,旨在评估Agent在这些前沿任务上的能力。作者使用合成数据训练了AgentFrontier-30B-A3B模型,该模型在诸如Humanity's Last Exam等高要求基准测试中取得了最先进的结果,甚至超过了一些领先的专有Agent。这项工作表明,ZPD引导的数据合成方法为构建更强大的LLM Agent提供了一条可扩展且有效的途径。
🔬 方法详解
问题定义:现有的大语言模型Agent在处理超出自身能力范围的任务时表现不佳,无法充分发挥其推理潜力。现有方法难以有效地生成高质量的、位于Agent能力边界附近的数据,从而限制了Agent能力的提升。
核心思路:论文的核心思路是借鉴教育学中的“最近发展区(ZPD)”理论,将Agent的能力边界定义为Agent在没有指导的情况下无法完成,但在指导下可以掌握的任务。通过合成位于Agent ZPD内的数据,可以有效地提升Agent的能力。
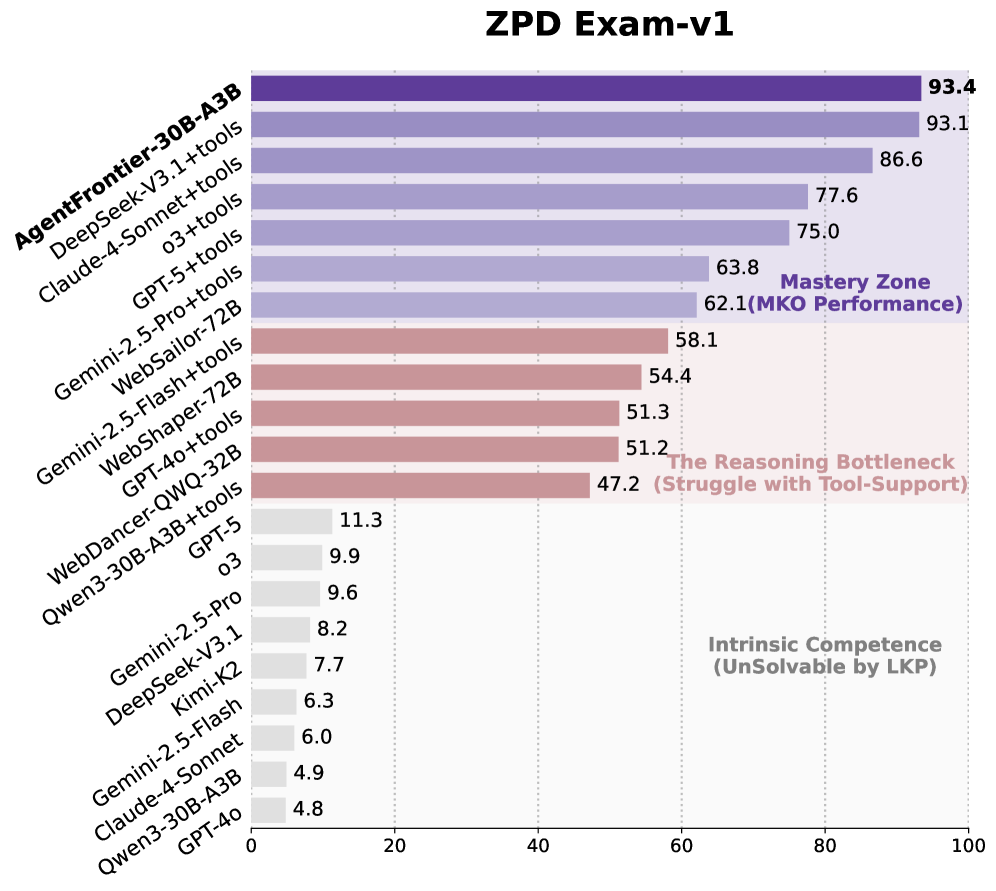
技术框架:AgentFrontier Engine包含数据生成、数据筛选和模型训练三个主要阶段。数据生成阶段利用LLM生成候选数据,数据筛选阶段根据ZPD原则筛选高质量数据,模型训练阶段使用筛选后的数据对Agent进行训练。ZPD Exam则用于动态评估Agent在ZPD任务上的表现。
关键创新:该方法的核心创新在于将ZPD理论应用于LLM Agent的数据合成,提出了一种自动化的数据生成和筛选流程,能够有效地生成位于Agent能力边界附近的高质量数据。与传统的数据增强方法相比,该方法能够更有效地提升Agent的能力。
关键设计:数据生成阶段使用prompt工程引导LLM生成多样化的候选数据。数据筛选阶段使用基于LLM的评估器,根据ZPD原则对候选数据进行评分和筛选。模型训练阶段使用标准的transformer架构,并采用合适的损失函数进行优化。
🖼️ 关键图片

📊 实验亮点
AgentFrontier-30B-A3B模型在Humanity's Last Exam等高要求基准测试中取得了最先进的结果,超过了许多领先的专有Agent。实验结果表明,ZPD引导的数据合成方法能够有效地提升LLM Agent的能力,使其能够更好地处理复杂推理任务。
🎯 应用场景
该研究成果可应用于各种需要复杂推理和决策的场景,例如智能客服、自动驾驶、金融分析、医疗诊断等。通过持续合成和学习位于Agent能力边界的数据,可以不断提升Agent的智能水平,使其能够更好地解决现实世界中的复杂问题,具有广阔的应用前景。
📄 摘要(原文)
Training large language model agents on tasks at the frontier of their capabilities is key to unlocking advanced reasoning. We introduce a data synthesis approach inspired by the educational theory of the Zone of Proximal Development (ZPD), which defines this frontier as tasks an LLM cannot solve alone but can master with guidance. To operationalize this, we present the AgentFrontier Engine, an automated pipeline that synthesizes high-quality, multidisciplinary data situated precisely within the LLM's ZPD. This engine supports both continued pre-training with knowledge-intensive data and targeted post-training on complex reasoning tasks. From the same framework, we derive the ZPD Exam, a dynamic and automated benchmark designed to evaluate agent capabilities on these frontier tasks. We train AgentFrontier-30B-A3B model on our synthesized data, which achieves state-of-the-art results on demanding benchmarks like Humanity's Last Exam, even surpassing some leading proprietary agents. Our work demonstrates that a ZPD-guided approach to data synthesis offers a scalable and effective path toward building more capable LLM agents.