STAR-Bench: Probing Deep Spatio-Temporal Reasoning as Audio 4D Intelligence
作者: Zihan Liu, Zhikang Niu, Qiuyang Xiao, Zhisheng Zheng, Ruoqi Yuan, Yuhang Zang, Yuhang Cao, Xiaoyi Dong, Jianze Liang, Xie Chen, Leilei Sun, Dahua Lin, Jiaqi Wang
分类: cs.SD, cs.CL, eess.AS
发布日期: 2025-10-28 (更新: 2025-11-28)
备注: Homepage: https://internlm.github.io/StarBench/
💡 一句话要点
提出STAR-Bench,用于评估模型在音频4D时空推理方面的能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 音频理解 时空推理 基准测试 多模态学习 4D智能
📋 核心要点
- 现有音频基准测试主要评估可从文本字幕中恢复的语义,忽略了对细粒度感知推理的评估。
- STAR-Bench通过结合基础声学感知和整体时空推理,来评估模型在音频4D时空推理方面的能力。
- 实验结果表明,现有模型在STAR-Bench上与人类相比存在显著差距,尤其是在时空推理方面。
📝 摘要(中文)
本文提出了STAR-Bench,旨在评估多模态大型语言模型和大型音频语言模型在细粒度感知推理方面的不足。该基准测试定义了音频4D智能,即对声音在时间和3D空间中的动态进行推理。STAR-Bench结合了基础声学感知设置(绝对和相对两种模式下的六个属性)和整体时空推理设置,包括连续和离散过程的片段重排序以及涵盖静态定位、多源关系和动态轨迹的空间任务。数据管理流程使用两种方法来确保高质量的样本。对于基础任务,使用程序合成和物理模拟音频。对于整体数据,遵循一个四阶段过程,包括人工标注和基于人工性能的最终选择。与先前基准测试中仅使用字幕回答略微降低准确性不同,STAR-Bench导致更大的下降(时间-31.5%,空间-35.2%),证明了其对语言难以描述的线索的关注。对19个模型的评估表明,与人类相比存在巨大差距,并且存在能力层级:闭源模型受到细粒度感知的限制,而开源模型在感知、知识和推理方面均落后。STAR-Bench为开发具有更强大的物理世界理解能力的未来模型提供了关键见解和明确的途径。
🔬 方法详解
问题定义:现有音频基准测试主要关注可以从文本字幕中恢复的语义信息,而忽略了对声音在时间和空间中动态变化的细粒度感知和推理能力的评估。这使得模型难以真正理解物理世界,阻碍了其在需要复杂音频理解的实际场景中的应用。
核心思路:本文的核心思路是构建一个专门用于评估音频4D时空推理能力的基准测试,即STAR-Bench。该基准测试通过设计一系列具有挑战性的任务,迫使模型不仅要理解声音的语义信息,还要理解声音在时间和空间中的动态变化,从而更全面地评估模型的音频理解能力。
技术框架:STAR-Bench包含两个主要部分:基础声学感知和整体时空推理。基础声学感知部分包含六个属性,分别在绝对和相对两种模式下进行评估。整体时空推理部分包含片段重排序(针对连续和离散过程)以及空间任务,包括静态定位、多源关系和动态轨迹。数据收集流程包括程序合成、物理模拟、人工标注和基于人工性能的最终选择等步骤,以确保数据质量。
关键创新:STAR-Bench的关键创新在于其对音频4D时空推理的明确定义和评估。与以往的基准测试不同,STAR-Bench更加关注声音在时间和空间中的动态变化,而不仅仅是声音的语义信息。此外,STAR-Bench的数据收集流程也更加严格,确保了数据的质量和难度。
关键设计:在数据收集方面,对于基础任务,使用程序合成和物理模拟音频,以保证数据的多样性和可控性。对于整体数据,采用四阶段流程:首先进行人工标注,然后根据人工性能进行最终选择,以确保数据的质量和难度。在评估指标方面,STAR-Bench采用了多种指标来评估模型在不同任务上的性能,包括准确率、召回率等。
🖼️ 关键图片


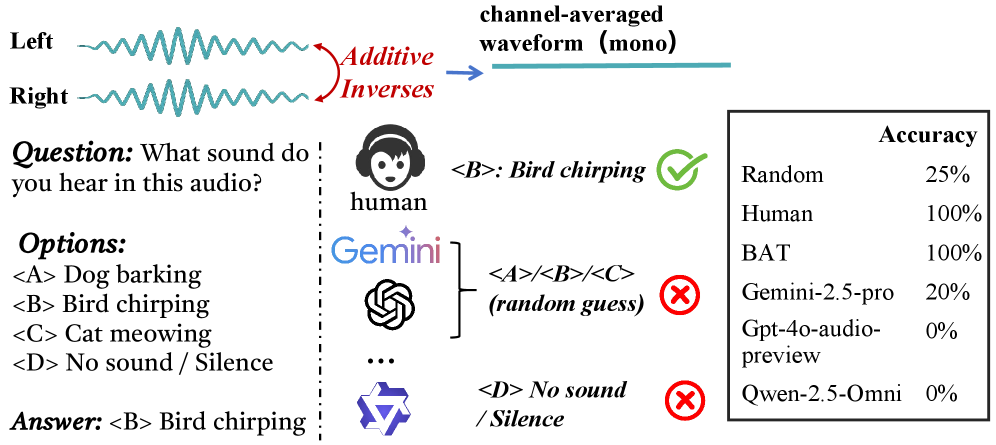
📊 实验亮点
对19个模型的评估结果表明,现有模型在STAR-Bench上与人类相比存在显著差距。具体而言,闭源模型在细粒度感知方面存在瓶颈,而开源模型在感知、知识和推理方面均落后。在时空推理任务中,STAR-Bench导致模型性能大幅下降(时间-31.5%,空间-35.2%),表明该基准测试能够有效评估模型在语言难以描述的线索上的推理能力。
🎯 应用场景
STAR-Bench的研究成果可应用于机器人、自动驾驶、智能家居等领域。例如,机器人可以通过理解声音在空间中的位置和动态变化,更好地进行导航和物体识别。自动驾驶系统可以通过分析车辆周围的声音,提高对交通状况的感知能力。智能家居系统可以通过识别用户的语音指令和环境声音,提供更智能化的服务。该研究有助于提升AI系统对物理世界的理解能力,促进人机交互的自然性和可靠性。
📄 摘要(原文)
Despite rapid progress in Multi-modal Large Language Models and Large Audio-Language Models, existing audio benchmarks largely test semantics that can be recovered from text captions, masking deficits in fine-grained perceptual reasoning. We formalize audio 4D intelligence that is defined as reasoning over sound dynamics in time and 3D space, and introduce STAR-Bench to measure it. STAR-Bench combines a Foundational Acoustic Perception setting (six attributes under absolute and relative regimes) with a Holistic Spatio-Temporal Reasoning setting that includes segment reordering for continuous and discrete processes and spatial tasks spanning static localization, multi-source relations, and dynamic trajectories. Our data curation pipeline uses two methods to ensure high-quality samples. For foundational tasks, we use procedurally synthesized and physics-simulated audio. For holistic data, we follow a four-stage process that includes human annotation and final selection based on human performance. Unlike prior benchmarks where caption-only answering reduces accuracy slightly, STAR-Bench induces far larger drops (-31.5\% temporal, -35.2\% spatial), evidencing its focus on linguistically hard-to-describe cues. Evaluating 19 models reveals substantial gaps compared with humans and a capability hierarchy: closed-source models are bottlenecked by fine-grained perception, while open-source models lag across perception, knowledge, and reasoning. Our STAR-Bench provides critical insights and a clear path forward for developing future models with a more robust understanding of the physical world.