Diffusion LLM with Native Variable Generation Lengths: Let [EOS] Lead the Way
作者: Yicun Yang, Cong Wang, Shaobo Wang, Zichen Wen, Biqing Qi, Hanlin Xu, Linfeng Zhang
分类: cs.CL
发布日期: 2025-10-28
💡 一句话要点
提出dLLM-Var,实现原生可变长度生成的扩散语言模型,显著提升推理速度。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 扩散语言模型 可变长度生成 文本生成 并行推理 [EOS] token预测
📋 核心要点
- 现有扩散语言模型(dLLMs)生成长度固定,需要在解码前设定,限制了效率和灵活性。
- dLLM-Var通过训练模型准确预测[EOS] token,实现原生可变长度生成,并保持全局双向注意。
- 实验表明,dLLM-Var相比传统dLLM推理加速30.1倍,比Qwen/Llama等自回归模型加速2.4倍。
📝 摘要(中文)
基于扩散的大型语言模型(dLLMs)在并行文本生成方面展现出巨大潜力,与自回归模型相比,有望实现更高效的生成。然而,现有的dLLMs存在生成长度固定的问题,这意味着dLLMs的生成长度必须在解码前确定为一个超参数,导致效率和灵活性问题。为了解决这些问题,本文提出了一种具有原生可变生成长度的扩散LLM,简称为dLLM-Var。具体而言,我们的目标是训练一个模型来准确预测生成文本中的[EOS] token,这使得dLLM能够以块扩散的方式进行原生推理,同时保持全局双向(完全)注意力和高并行性。在标准基准上的实验表明,我们的方法比传统的dLLM推理范式实现了30.1倍的加速,相对于Qwen和Llama等自回归模型实现了2.4倍的加速。我们的方法实现了更高的准确性和更快的推理速度,使dLLMs超越了纯粹的学术新颖性,并支持它们在实际应用中的实际使用。代码和模型已发布。
🔬 方法详解
问题定义:现有基于扩散的语言模型(dLLMs)在生成文本时,其生成长度是固定的,需要在解码之前就确定为一个超参数。这导致了两个主要问题:一是效率低下,因为需要预先确定一个可能远大于实际需要的长度;二是缺乏灵活性,无法根据生成内容的需要动态调整长度。因此,需要一种方法使得dLLMs能够生成可变长度的文本,从而提高效率和灵活性。
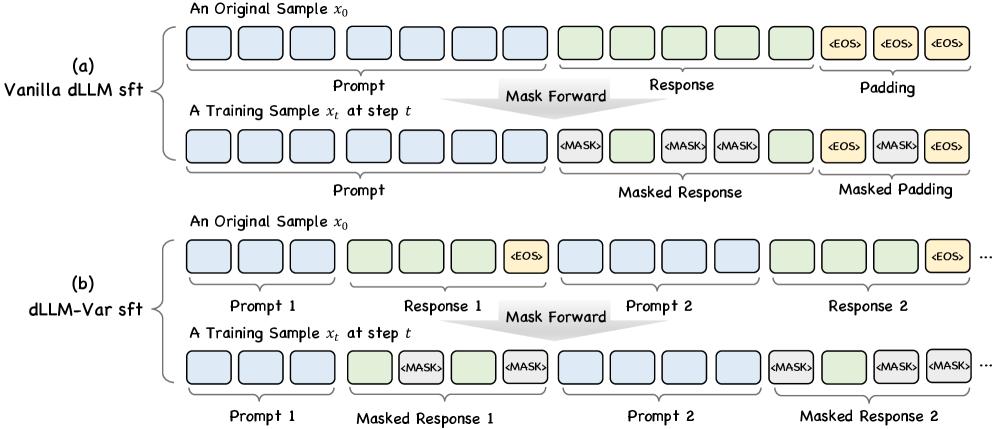
核心思路:论文的核心思路是训练一个dLLM,使其能够准确预测生成文本中的[EOS](End of Sequence)token。通过准确预测[EOS] token,模型可以在生成过程中动态地决定何时停止生成,从而实现可变长度的生成。这种方法允许dLLM以块扩散的方式进行推理,同时保持全局双向注意力和高并行性。
技术框架:dLLM-Var的整体框架仍然基于扩散模型,但关键在于训练过程中引入了对[EOS] token的预测能力。具体来说,模型在扩散和逆扩散过程中,不仅要预测文本内容,还要预测何时出现[EOS] token。这需要在模型的输出层增加一个专门用于预测[EOS] token的模块。在推理阶段,模型会不断生成文本块,并预测每个块中是否包含[EOS] token。一旦预测到[EOS] token,生成过程就会停止。
关键创新:该论文的关键创新在于将[EOS] token预测融入到扩散语言模型的训练和推理过程中,从而实现了原生可变长度生成。与现有方法相比,该方法不需要预先确定生成长度,而是可以根据生成内容的需要动态调整长度。此外,该方法还保持了dLLMs的全局双向注意力和高并行性优势。
关键设计:在训练过程中,论文可能采用了特殊的损失函数来鼓励模型准确预测[EOS] token。例如,可以增加一个额外的损失项,用于衡量模型预测[EOS] token的准确性。此外,可能还需要对网络结构进行一些调整,以更好地支持[EOS] token的预测。具体的参数设置和网络结构细节需要在论文中进一步查找。
🖼️ 关键图片

📊 实验亮点
实验结果表明,dLLM-Var在标准基准测试中实现了显著的性能提升。与传统dLLM推理范式相比,推理速度提高了30.1倍。与Qwen和Llama等自回归模型相比,推理速度提高了2.4倍。这些结果表明,dLLM-Var在保证生成质量的同时,显著提高了生成效率。
🎯 应用场景
该研究成果可广泛应用于需要灵活文本生成的场景,如对话系统、文本摘要、机器翻译等。通过实现可变长度生成,可以显著提高生成效率和用户体验。未来,该技术有望推动扩散模型在自然语言处理领域的更广泛应用,并促进相关应用的智能化升级。
📄 摘要(原文)
Diffusion-based large language models (dLLMs) have exhibited substantial potential for parallel text generation, which may enable more efficient generation compared to autoregressive models. However, current dLLMs suffer from fixed generation lengths, which indicates the generation lengths of dLLMs have to be determined before decoding as a hyper-parameter, leading to issues in efficiency and flexibility. To solve these problems, in this work, we propose to train a diffusion LLM with native variable generation lengths, abbreviated as dLLM-Var. Concretely, we aim to train a model to accurately predict the [EOS] token in the generated text, which makes a dLLM be able to natively infer in a block diffusion manner, while still maintaining the ability of global bi-directional (full) attention and high parallelism. Experiments on standard benchmarks demonstrate that our method achieves a 30.1x speedup over traditional dLLM inference paradigms and a 2.4x speedup relative to autoregressive models such as Qwen and Llama. Our method achieves higher accuracy and faster inference, elevating dLLMs beyond mere academic novelty and supporting their practical use in real-world applications. Codes and models have been released.