ReForm: Reflective Autoformalization with Prospective Bounded Sequence Optimization
作者: Guoxin Chen, Jing Wu, Xinjie Chen, Wayne Xin Zhao, Ruihua Song, Chengxi Li, Kai Fan, Dayiheng Liu, Minpeng Liao
分类: cs.CL
发布日期: 2025-10-28 (更新: 2025-10-30)
备注: https://github.com/Chen-GX/ReForm
💡 一句话要点
提出ReForm,通过自反形式化与前瞻有界序列优化提升自然语言数学的形式化转换。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自动形式化 大型语言模型 语义一致性 自反学习 序列优化
📋 核心要点
- 现有LLM方法将形式化视为简单的翻译任务,缺乏人类专家常用的自反思和迭代改进机制,导致语义保持能力不足。
- ReForm的核心思想是将语义一致性评估融入形式化过程,通过迭代生成、评估和纠正,实现语义保真度更高的形式化转换。
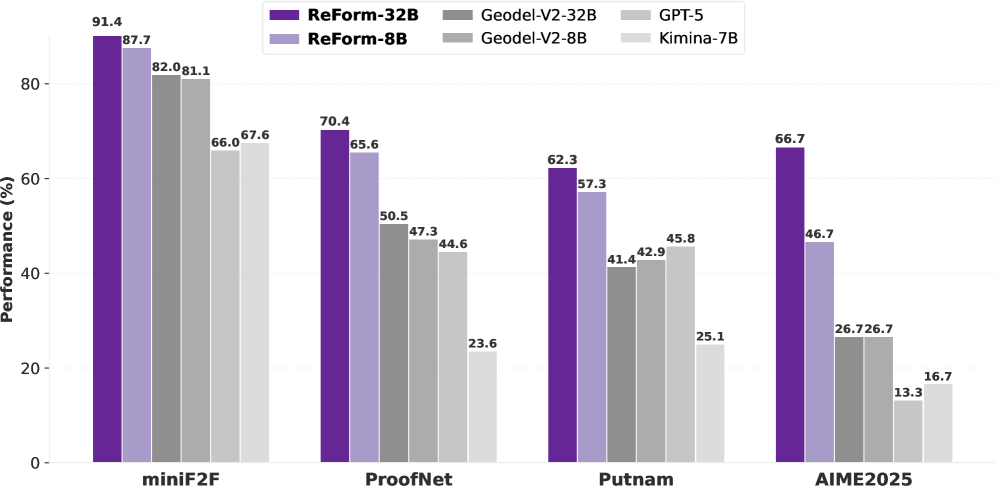
- 实验结果表明,ReForm在多个基准测试中显著优于现有方法,平均提升高达22.6个百分点,验证了其有效性。
📝 摘要(中文)
本文提出了一种名为ReForm的自反形式化方法,旨在解决大型语言模型(LLM)在将自然语言数学问题转换为机器可验证的形式化语句时,未能充分保持原始语义意图的问题。ReForm将语义一致性评估紧密集成到形式化过程中,使模型能够迭代生成形式化语句,评估语义保真度,并通过渐进式改进来纠正已识别的错误。为了有效训练这种自反模型,本文引入了前瞻有界序列优化(PBSO),它在不同的序列位置采用不同的奖励,以确保模型发展出准确的形式化和正确的语义验证能力,防止肤浅的批评破坏自反的目的。在四个形式化基准上的大量实验表明,ReForm比最强的基线平均提高了22.6个百分点。为了进一步确保评估的可靠性,本文引入了ConsistencyCheck,这是一个包含859个专家标注项目的基准,它不仅验证了LLM作为判断者的能力,还揭示了形式化本质上的困难:即使是人类专家也会在高达38.5%的情况下产生语义错误。
🔬 方法详解
问题定义:现有的大型语言模型在进行自动形式化时,通常将自然语言数学问题直接翻译成形式化语言,忽略了对语义一致性的保持。这种方法容易产生语法正确但语义错误的公式,限制了形式化推理在解决自然语言数学问题中的应用。现有方法的痛点在于缺乏有效的自反思和迭代改进机制,难以保证形式化结果的语义正确性。
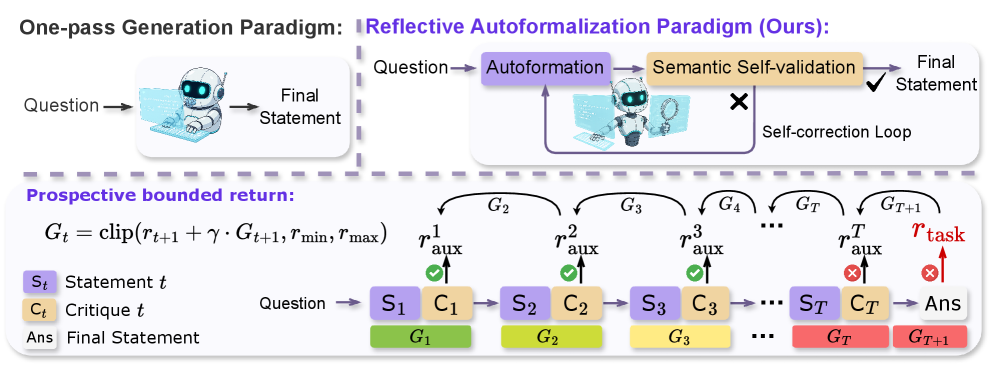
核心思路:ReForm的核心思路是将语义一致性评估融入到自动形式化的过程中,使模型能够像人类专家一样,通过迭代生成、评估和修正来逐步完善形式化结果。通过引入自反机制,模型可以主动识别并纠正形式化过程中的语义错误,从而提高形式化结果的准确性和可靠性。
技术框架:ReForm的整体框架包含三个主要阶段:1) 形式化语句生成:使用LLM生成初始的形式化语句。2) 语义一致性评估:使用LLM评估生成的形式化语句与原始自然语言问题之间的语义一致性。3) 自我修正:根据语义一致性评估的结果,LLM对形式化语句进行迭代修正,直到满足语义一致性要求。该过程循环进行,直到达到预设的迭代次数或满足停止条件。
关键创新:ReForm最重要的技术创新点在于将语义一致性评估紧密集成到自动形式化过程中,实现了自反形式化。此外,提出的前瞻有界序列优化(PBSO)方法,通过在序列的不同位置设置不同的奖励,有效地训练了自反模型,避免了模型产生肤浅的批评。与现有方法相比,ReForm能够更有效地识别和纠正形式化过程中的语义错误,从而提高形式化结果的准确性。
关键设计:在语义一致性评估阶段,使用了LLM作为判断器,判断形式化语句是否准确表达了原始自然语言问题的含义。为了训练这个判断器,使用了ConsistencyCheck基准,该基准包含专家标注的数据,用于评估LLM判断语义一致性的能力。PBSO通过在序列的不同位置设置不同的奖励,鼓励模型在生成形式化语句的早期阶段注重语法正确性,在后续阶段注重语义一致性。具体来说,PBSO对生成正确的形式化语句给予正向奖励,对识别出语义错误的语句给予更高的奖励,从而引导模型进行有效的自我修正。
🖼️ 关键图片
📊 实验亮点
ReForm在四个自动形式化基准测试中取得了显著的性能提升,平均超过最强基线22.6个百分点。ConsistencyCheck基准的引入,不仅验证了LLM作为判断者的能力,还揭示了形式化任务的难度,即使是人类专家也会在高达38.5%的情况下产生语义错误。这些实验结果充分证明了ReForm的有效性和实用性。
🎯 应用场景
ReForm在自动定理证明、数学教育、智能合约验证等领域具有广泛的应用前景。它可以帮助研究人员和学生更方便地将自然语言数学问题转换为形式化语言,从而利用形式化方法进行推理和验证。此外,ReForm还可以应用于智能合约的自动验证,提高智能合约的安全性和可靠性。未来,ReForm有望成为数学和计算机科学领域的重要工具。
📄 摘要(原文)
Autoformalization, which translates natural language mathematics into machine-verifiable formal statements, is critical for using formal mathematical reasoning to solve math problems stated in natural language. While Large Language Models can generate syntactically correct formal statements, they often fail to preserve the original problem's semantic intent. This limitation arises from the LLM approaches' treating autoformalization as a simplistic translation task which lacks mechanisms for self-reflection and iterative refinement that human experts naturally employ. To address these issues, we propose ReForm, a Reflective Autoformalization method that tightly integrates semantic consistency evaluation into the autoformalization process. This enables the model to iteratively generate formal statements, assess its semantic fidelity, and self-correct identified errors through progressive refinement. To effectively train this reflective model, we introduce Prospective Bounded Sequence Optimization (PBSO), which employs different rewards at different sequence positions to ensure that the model develops both accurate autoformalization and correct semantic validations, preventing superficial critiques that would undermine the purpose of reflection. Extensive experiments across four autoformalization benchmarks demonstrate that ReForm achieves an average improvement of 22.6 percentage points over the strongest baselines. To further ensure evaluation reliability, we introduce ConsistencyCheck, a benchmark of 859 expert-annotated items that not only validates LLMs as judges but also reveals that autoformalization is inherently difficult: even human experts produce semantic errors in up to 38.5% of cases.