A word association network methodology for evaluating implicit biases in LLMs compared to humans
作者: Katherine Abramski, Giulio Rossetti, Massimo Stella
分类: cs.CL, cs.AI
发布日期: 2025-10-28
备注: 24 pages, 13 figures, 3 tables
💡 一句话要点
提出一种基于词语联想网络的LLM内隐偏见评估方法,可与人类偏见直接对比。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 内隐偏见 词语联想网络 语义启动 偏见评估
📋 核心要点
- 现有方法难以有效评估LLM中内隐的社会偏见,这些偏见隐藏在模型的知识表示中。
- 该方法通过构建LLM生成的词语联想网络,模拟语义启动过程,从而挖掘和评估内隐偏见。
- 实验表明,该方法能够直接比较LLM和人类的偏见,揭示二者之间的异同,为LLM风险评估提供新视角。
📝 摘要(中文)
随着大型语言模型(LLM)日益融入我们的生活,其固有的社会偏见仍然是一个紧迫的问题。检测和评估这些偏见具有挑战性,因为它们通常是内隐的而非外显的。因此,开发评估LLM内隐知识表示的方法至关重要。本文提出了一种新颖的词语联想网络方法,用于评估LLM中的内隐偏见,该方法基于模拟LLM生成的词语联想网络中的语义启动。我们基于提示的方法挖掘了LLM中编码的内隐关系结构,从而对偏见进行定量和定性评估。与大多数基于提示的评估方法不同,我们的方法能够直接比较各种LLM和人类,提供有价值的参考点,并为LLM与人类认知的一致性提供新的见解。为了证明该方法的有效性,我们将其应用于人类和几种广泛使用的LLM,以调查与性别、宗教、种族、性取向和政治派别相关的社会偏见。结果揭示了LLM和人类偏见之间的趋同和差异,为使用LLM的潜在风险提供了新的视角。我们的方法为评估和比较多个LLM和人类之间的偏见提供了一个系统、可扩展和通用的框架,从而推进了透明和对社会负责的语言技术的目标。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)中内隐社会偏见的评估问题。现有方法通常侧重于外显偏见的检测,难以捕捉LLM深层知识表示中隐藏的内隐偏见。这些内隐偏见可能在下游任务中产生负面影响,但难以被传统方法有效识别和量化。
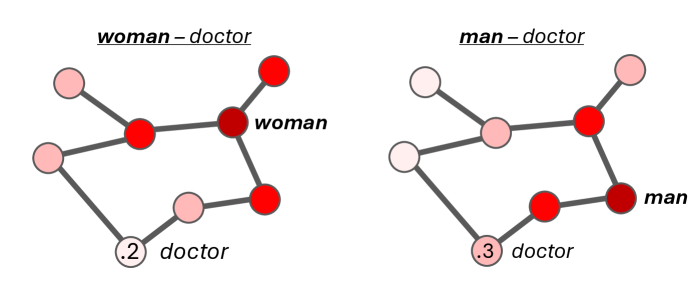
核心思路:论文的核心思路是利用词语联想网络来模拟人类的语义启动过程,从而揭示LLM中内隐的偏见。通过分析LLM生成的词语联想网络,可以推断模型对不同概念之间的关联强度,进而评估其潜在的偏见倾向。这种方法模拟了人类认知过程,使得LLM偏见评估更具可解释性和可比性。
技术框架:该方法主要包含以下几个阶段:1) 提示生成:设计合适的提示语,引导LLM生成与目标概念相关的词语联想;2) 词语联想网络构建:基于LLM的输出,构建词语联想网络,节点代表词语,边代表词语之间的关联强度;3) 偏见评估:分析词语联想网络的结构和属性,例如特定概念与其他概念的关联强度,从而评估LLM的内隐偏见。4) 人类对比:使用相同的方法对人类进行评估,从而实现LLM和人类偏见的直接对比。
关键创新:该方法最重要的创新点在于其能够直接比较LLM和人类的内隐偏见。与以往的LLM偏见评估方法不同,该方法提供了一个人类基准,使得对LLM偏见的理解更加深入和全面。此外,该方法基于词语联想网络,具有较强的可解释性,能够揭示LLM偏见的内在机制。
关键设计:在提示生成方面,需要精心设计提示语,以确保LLM能够生成高质量的词语联想。在词语联想网络构建方面,需要选择合适的关联强度度量方法,例如基于共现频率或语义相似度。在偏见评估方面,可以采用多种网络分析指标,例如节点中心性、社团结构等。此外,需要对人类数据进行预处理,以确保与LLM数据具有可比性。
🖼️ 关键图片

📊 实验亮点
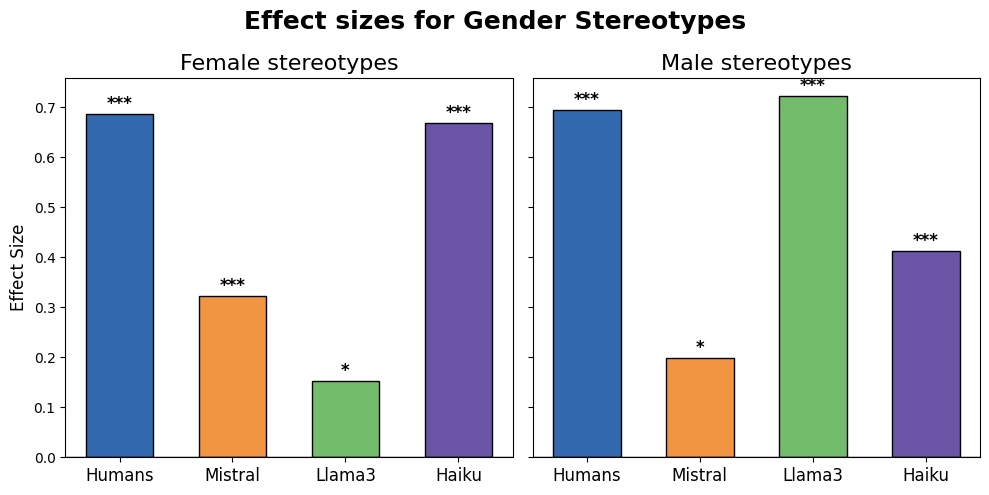
实验结果表明,LLM在性别、宗教、种族、性取向和政治派别等方面存在不同程度的内隐偏见。通过与人类的对比,发现LLM在某些方面的偏见与人类相似,但在另一些方面则存在显著差异。例如,LLM在某些情况下可能表现出比人类更强的刻板印象。
🎯 应用场景
该研究成果可应用于LLM的偏见检测与缓解,帮助开发者构建更公平、更负责任的AI系统。通过对比LLM与人类的偏见,可以更好地理解LLM的认知模式,从而指导模型的改进和优化。此外,该方法还可用于评估不同LLM之间的偏见差异,为用户选择合适的LLM提供参考。
📄 摘要(原文)
As Large language models (LLMs) become increasingly integrated into our lives, their inherent social biases remain a pressing concern. Detecting and evaluating these biases can be challenging because they are often implicit rather than explicit in nature, so developing evaluation methods that assess the implicit knowledge representations of LLMs is essential. We present a novel word association network methodology for evaluating implicit biases in LLMs based on simulating semantic priming within LLM-generated word association networks. Our prompt-based approach taps into the implicit relational structures encoded in LLMs, providing both quantitative and qualitative assessments of bias. Unlike most prompt-based evaluation methods, our method enables direct comparisons between various LLMs and humans, providing a valuable point of reference and offering new insights into the alignment of LLMs with human cognition. To demonstrate the utility of our methodology, we apply it to both humans and several widely used LLMs to investigate social biases related to gender, religion, ethnicity, sexual orientation, and political party. Our results reveal both convergences and divergences between LLM and human biases, providing new perspectives on the potential risks of using LLMs. Our methodology contributes to a systematic, scalable, and generalizable framework for evaluating and comparing biases across multiple LLMs and humans, advancing the goal of transparent and socially responsible language technologies.