Can LLMs Write Faithfully? An Agent-Based Evaluation of LLM-generated Islamic Content
作者: Abdullah Mushtaq, Rafay Naeem, Ezieddin Elmahjub, Ibrahim Ghaznavi, Shawqi Al-Maliki, Mohamed Abdallah, Ala Al-Fuqaha, Junaid Qadir
分类: cs.CL, cs.AI, cs.CY, cs.MA
发布日期: 2025-10-28
备注: Accepted at 39th Conference on Neural Information Processing Systems (NeurIPS 2025) Workshop: 5th Muslims in Machine Learning (MusIML) Workshop
💡 一句话要点
提出基于Agent的框架,评估LLM在生成伊斯兰内容时的准确性和一致性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 伊斯兰内容生成 Agent评估框架 准确性评估 信仰敏感领域
📋 核心要点
- 现有大型语言模型在伊斯兰指导应用中,存在引文错误、教法误用和文化不一致等问题。
- 论文提出双Agent评估框架,分别从定量和定性角度评估LLM生成的伊斯兰内容的质量。
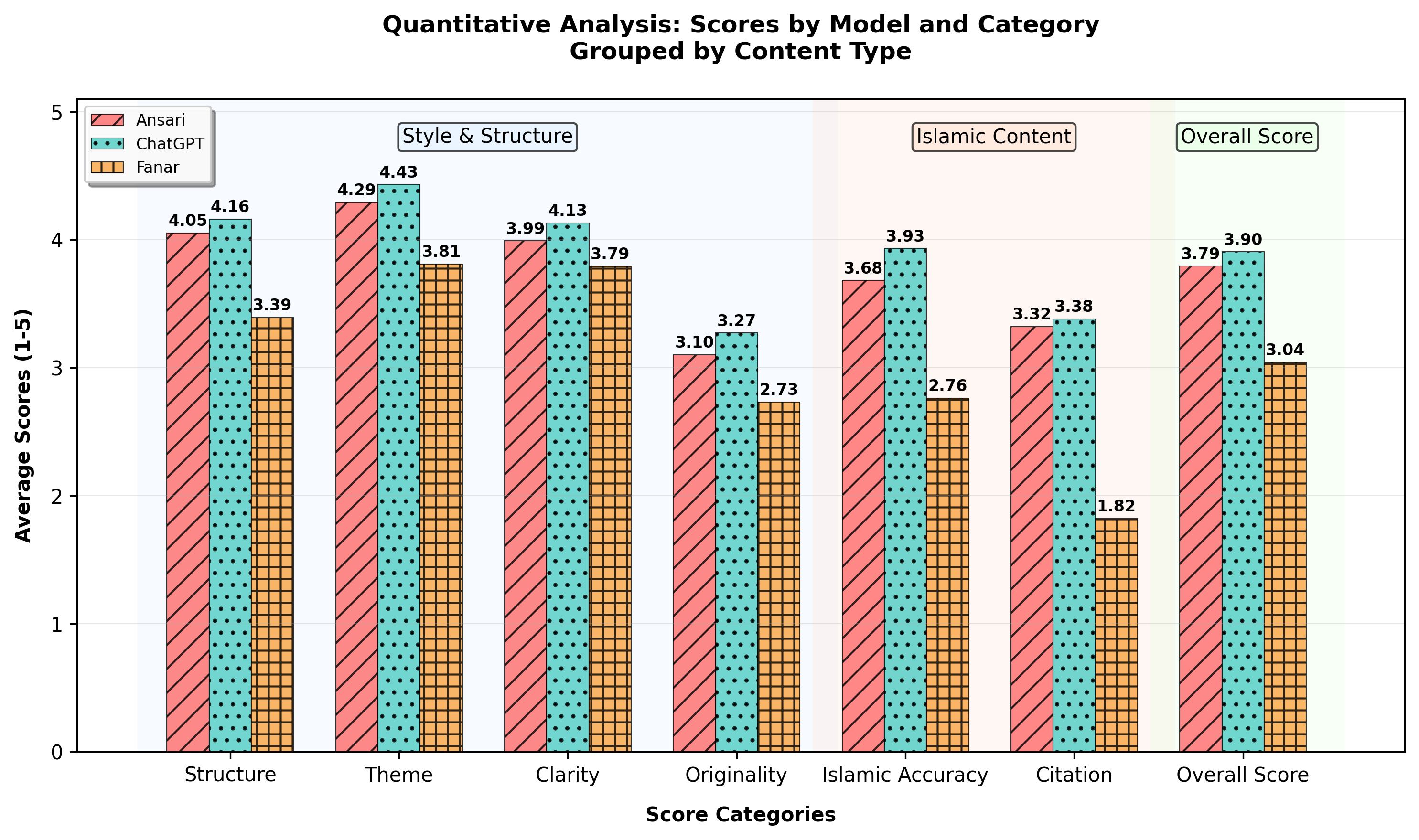
- 实验表明,GPT-4o在伊斯兰准确性和引文方面表现最佳,但所有模型仍需提升可靠性。
📝 摘要(中文)
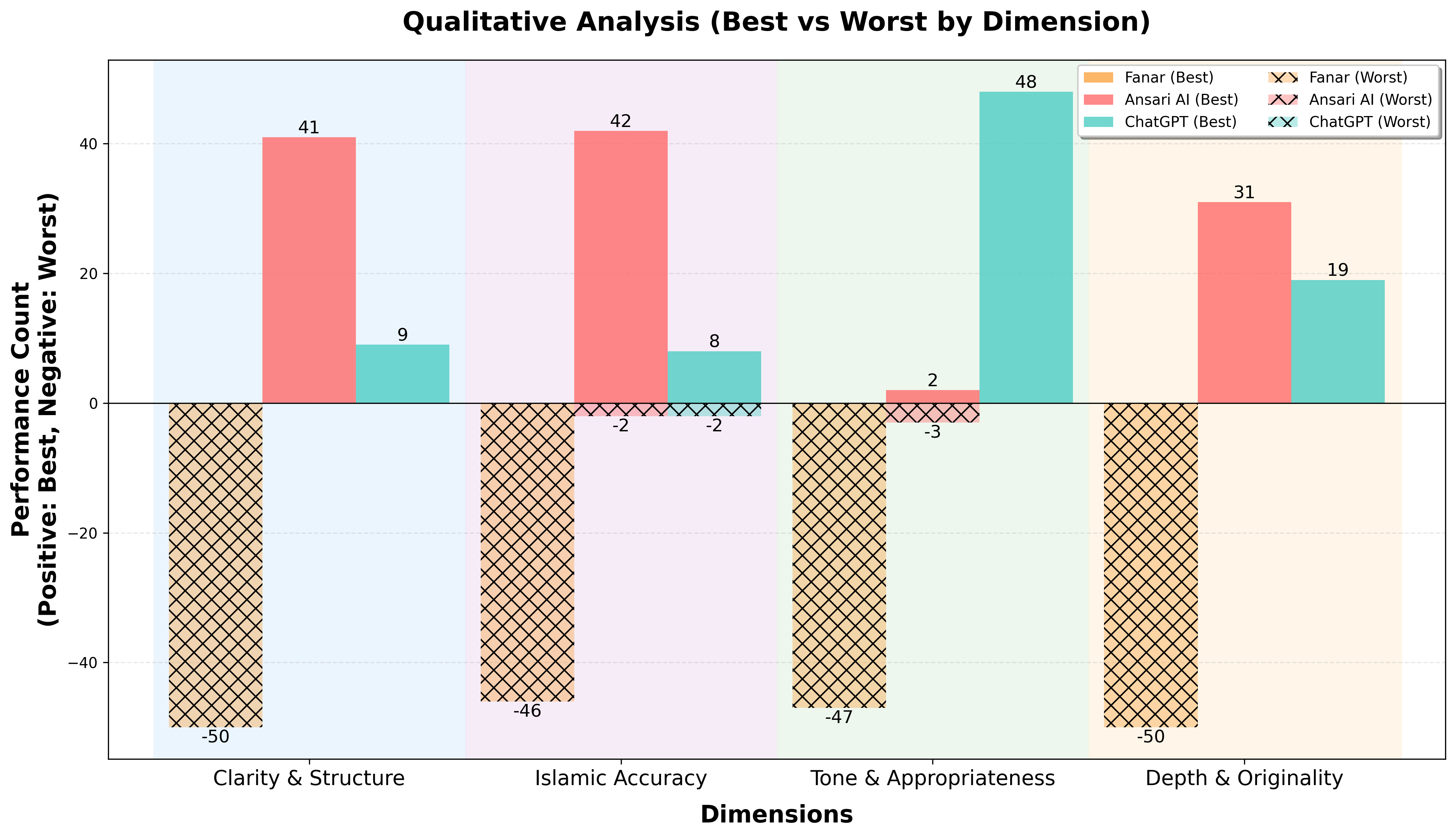
大型语言模型越来越多地被用于提供伊斯兰指导,但存在误引经文、错误应用伊斯兰教法或产生文化上不一致的回应的风险。本文对GPT-4o、Ansari AI和Fanar在来自真实伊斯兰博客的提示下进行了评估。研究采用双Agent框架,使用定量Agent进行引文验证和六维度评分(如结构、伊斯兰一致性、引文),以及定性Agent进行五维度并排比较(如语气、深度、原创性)。GPT-4o在伊斯兰准确性(3.93)和引文(3.38)方面得分最高,Ansari AI紧随其后(3.68, 3.32),Fanar则落后(2.76, 1.82)。尽管性能相对较强,但模型在可靠地生成准确的伊斯兰内容和引文方面仍然不足,这在信仰敏感的写作中至关重要。GPT-4o的平均定量得分最高(3.90/5),而Ansari AI在定性成对比较中领先(116/200)。Fanar虽然落后,但为伊斯兰和阿拉伯语环境引入了创新。这项研究强调了以穆斯林视角为中心的社区驱动基准的必要性,为在伊斯兰知识以及医学、法律和新闻等高风险领域实现更可靠的AI迈出了初步一步。
🔬 方法详解
问题定义:论文旨在评估大型语言模型(LLM)在生成伊斯兰相关内容时的准确性和可靠性。现有方法缺乏针对伊斯兰知识的专门评估,并且难以量化LLM在信仰敏感领域的表现,容易出现误引经文、错误应用教法等问题。
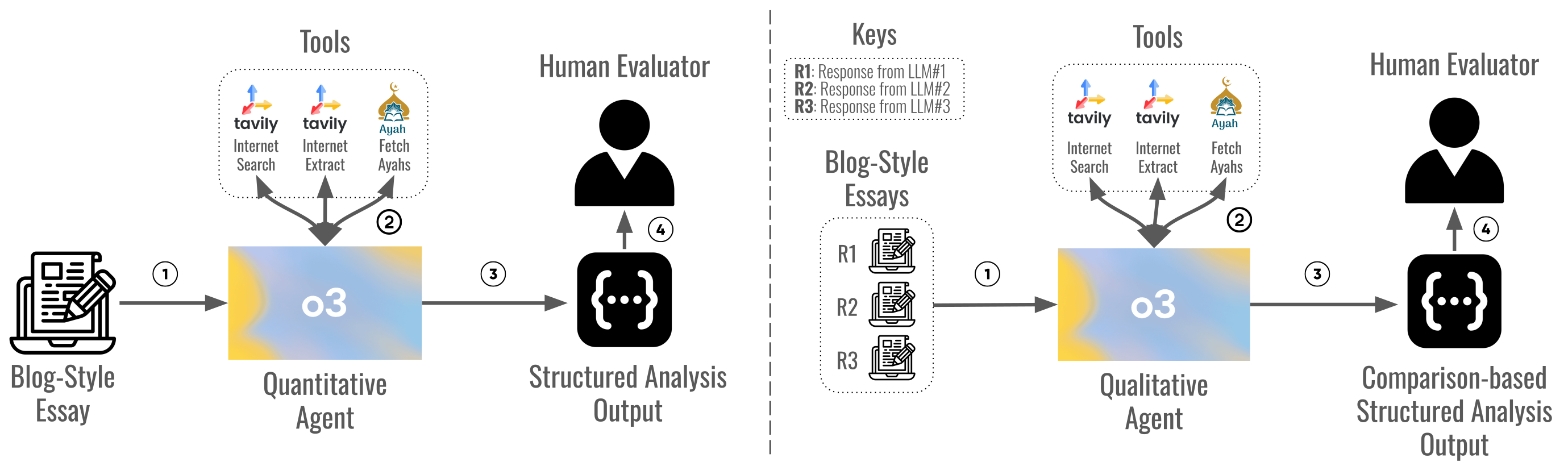
核心思路:论文的核心思路是构建一个基于Agent的评估框架,通过模拟专家评审的方式,从定量和定性两个维度对LLM生成的内容进行评估。这种方法能够更全面地捕捉LLM在伊斯兰知识方面的表现,并识别潜在的错误和偏差。
技术框架:该框架包含两个主要Agent:定量Agent和定性Agent。定量Agent负责引文验证和六维度评分(结构、伊斯兰一致性、引文等),采用预定义的规则和指标进行评估。定性Agent则进行五维度并排比较(语气、深度、原创性等),侧重于主观判断和比较分析。两个Agent的评估结果结合起来,形成对LLM性能的综合评估。
关键创新:该研究的关键创新在于提出了一个专门针对伊斯兰内容的LLM评估框架,并采用了双Agent协同评估的方法。这种方法不仅能够量化LLM的准确性,还能够捕捉其在语气、深度等方面的表现,从而更全面地评估LLM在信仰敏感领域的适用性。
关键设计:定量Agent使用预定义的评分标准和引文验证方法,例如,通过检索相关伊斯兰文本数据库来验证引文的准确性。定性Agent则采用并排比较的方式,由人工专家对不同LLM生成的内容进行比较,并给出主观评价。具体的参数设置和损失函数未知,因为论文侧重于评估框架的设计而不是模型的训练。
🖼️ 关键图片
📊 实验亮点
实验结果表明,GPT-4o在伊斯兰准确性(3.93/5)和引文(3.38/5)方面得分最高,但所有模型在生成准确的伊斯兰内容和引文方面仍有不足。Ansari AI在定性成对比较中表现最佳(116/200),表明其在语气和深度方面具有优势。Fanar虽然整体表现落后,但其在伊斯兰和阿拉伯语环境中的创新值得关注。
🎯 应用场景
该研究成果可应用于开发更可靠的伊斯兰知识问答系统、智能伊斯兰教育平台等。此外,该评估框架的设计思路也可推广到其他高风险领域,如医学、法律和新闻,以确保AI生成内容的准确性和可靠性,避免产生误导或造成不良影响。
📄 摘要(原文)
Large language models are increasingly used for Islamic guidance, but risk misquoting texts, misapplying jurisprudence, or producing culturally inconsistent responses. We pilot an evaluation of GPT-4o, Ansari AI, and Fanar on prompts from authentic Islamic blogs. Our dual-agent framework uses a quantitative agent for citation verification and six-dimensional scoring (e.g., Structure, Islamic Consistency, Citations) and a qualitative agent for five-dimensional side-by-side comparison (e.g., Tone, Depth, Originality). GPT-4o scored highest in Islamic Accuracy (3.93) and Citation (3.38), Ansari AI followed (3.68, 3.32), and Fanar lagged (2.76, 1.82). Despite relatively strong performance, models still fall short in reliably producing accurate Islamic content and citations -- a paramount requirement in faith-sensitive writing. GPT-4o had the highest mean quantitative score (3.90/5), while Ansari AI led qualitative pairwise wins (116/200). Fanar, though trailing, introduces innovations for Islamic and Arabic contexts. This study underscores the need for community-driven benchmarks centering Muslim perspectives, offering an early step toward more reliable AI in Islamic knowledge and other high-stakes domains such as medicine, law, and journalism.