Automatically Benchmarking LLM Code Agents through Agent-Driven Annotation and Evaluation
作者: Lingyue Fu, Bolun Zhang, Hao Guan, Yaoming Zhu, Lin Qiu, Weiwen Liu, Xuezhi Cao, Xunliang Cai, Weinan Zhang, Yong Yu
分类: cs.SE, cs.CL
发布日期: 2025-10-28
💡 一句话要点
提出基于Agent驱动的LLM代码智能体评测基准PRDBench,解决标注成本高和评测指标单一问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码智能体 基准测试 LLM Agent驱动 自动化评估
📋 核心要点
- 现有代码智能体评测基准存在标注成本高、需要专业知识以及评测指标过于依赖单元测试等局限性。
- 论文提出Agent驱动的基准构建流程,通过人工监督高效生成多样且具挑战性的项目级任务。
- 构建了包含50个真实Python项目的PRDBench基准,并采用Agent-as-a-Judge范式进行更全面的评估。
📝 摘要(中文)
本文提出了一种基于Agent驱动的基准构建流程,旨在解决现有代码智能体评测基准中存在的标注成本高、专业知识要求高以及主要依赖单元测试的评测指标僵化等问题。该流程利用人工监督,高效生成多样且具有挑战性的项目级任务。基于此,本文构建了一个名为PRDBench的新基准,它包含20个领域中50个真实的Python项目,每个项目都具有结构化的产品需求文档(PRD)要求、全面的评估标准和参考实现。PRDBench具有丰富的数据源、高任务复杂性和灵活的指标。此外,本文还采用Agent-as-a-Judge范式来对智能体输出进行评分,从而能够评估单元测试之外的各种测试类型。在PRDBench上进行的大量实验证明了其在评估代码智能体和评估智能体的能力方面的有效性,为注释和评估提供了一个可扩展且强大的框架。
🔬 方法详解
问题定义:现有代码智能体评测基准主要面临两个问题:一是标注成本高昂,需要大量的人工投入和专业知识;二是评测指标过于依赖单元测试,无法全面评估代码智能体的能力,尤其是在项目级别的复杂任务中。这些限制阻碍了代码智能体的快速发展和有效评估。
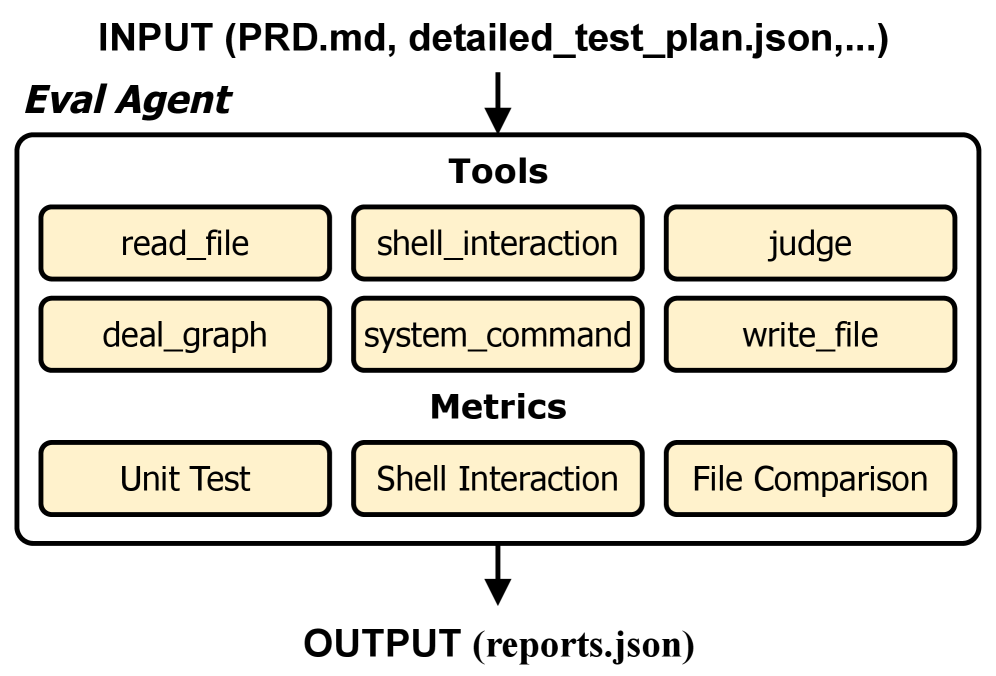
核心思路:论文的核心思路是利用Agent驱动的方式,降低基准构建的成本,并提高评测的全面性。具体来说,利用LLM作为Agent,在人工监督下自动生成测试用例和评估标准,从而减少人工标注的需求。同时,采用Agent-as-a-Judge范式,让LLM作为裁判,评估代码智能体的输出,从而可以评估单元测试之外的各种测试类型。
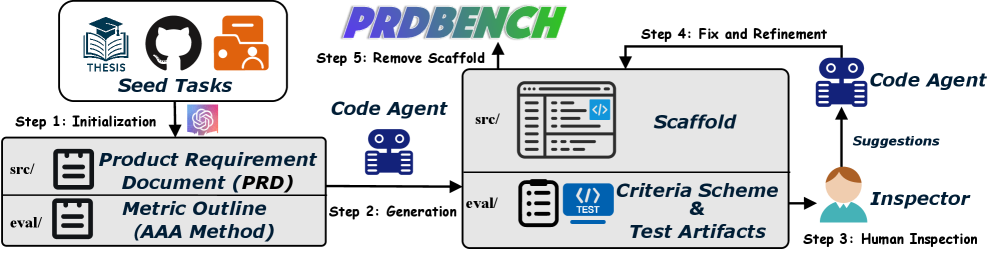
技术框架:整体框架包含以下几个主要阶段:1) 任务生成阶段:基于真实世界的Python项目,利用LLM生成结构化的产品需求文档(PRD)。2) 基准构建阶段:人工对生成的PRD进行审核和修改,确保任务的质量和多样性。3) 评估阶段:使用代码智能体完成任务,并使用Agent-as-a-Judge范式对智能体的输出进行评分。PRDBench基准包含丰富的数据源,高任务复杂性和灵活的指标。
关键创新:论文的关键创新在于提出了Agent驱动的基准构建流程和Agent-as-a-Judge范式。Agent驱动的基准构建流程降低了标注成本,提高了基准的多样性。Agent-as-a-Judge范式扩展了评估的范围,可以评估单元测试之外的各种测试类型,更全面地评估代码智能体的能力。与现有方法相比,该方法更加高效、灵活和全面。
关键设计:在Agent-as-a-Judge范式中,论文设计了详细的prompt,引导LLM作为裁判,根据PRD的要求,对代码智能体的输出进行评分。评分标准包括代码的正确性、可读性、效率和安全性等方面。此外,论文还设计了多种类型的测试用例,包括单元测试、集成测试和端到端测试,以全面评估代码智能体的能力。
🖼️ 关键图片

📊 实验亮点
实验结果表明,PRDBench能够有效评估代码智能体和评估智能体的能力。通过在PRDBench上进行测试,可以发现现有代码智能体在处理复杂项目级任务时仍然存在许多不足。同时,实验也验证了Agent-as-a-Judge范式的有效性,表明LLM可以作为可靠的裁判,评估代码智能体的输出。
🎯 应用场景
该研究成果可应用于代码智能体的开发和评估,帮助开发者更好地了解代码智能体的能力和局限性,从而开发出更强大的代码智能体。此外,该基准还可以用于比较不同代码智能体的性能,为用户选择合适的代码智能体提供参考。未来,该方法可以扩展到其他类型的智能体评估,例如机器人智能体和对话智能体。
📄 摘要(原文)
Recent advances in code agents have enabled automated software development at the project level, supported by large language models (LLMs) and widely adopted tools. However, existing benchmarks for code agent evaluation face two major limitations: high annotation cost and expertise requirements, and rigid evaluation metrics that rely primarily on unit tests. To address these challenges, we propose an agent-driven benchmark construction pipeline that leverages human supervision to efficiently generate diverse and challenging project-level tasks. Based on this approach, we introduce PRDBench, a novel benchmark comprising 50 real-world Python projects across 20 domains, each with structured Product Requirement Document (PRD) requirements, comprehensive evaluation criteria, and reference implementations. PRDBench features rich data sources, high task complexity, and flexible metrics. We further employ an Agent-as-a-Judge paradigm to score agent outputs, enabling the evaluation of various test types beyond unit tests. Extensive experiments on PRDBench demonstrate its effectiveness in assessing the capabilities of both code agents and evaluation agents, providing a scalable and robust framework for annotation and evaluation.