LongWeave: A Long-Form Generation Benchmark Bridging Real-World Relevance and Verifiability
作者: Zikai Xiao, Fei Huang, Jianhong Tu, Jianhui Wei, Wen Ma, Yuxuan Zhou, Jian Wu, Bowen Yu, Zuozhu Liu, Junyang Lin
分类: cs.CL, cs.AI
发布日期: 2025-10-28
备注: EMNLP Findings 2025
💡 一句话要点
提出LongWeave基准,通过CoV-Eval评估LLM在真实场景下的长文本生成能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长文本生成 大型语言模型 基准测试 真实世界评估 约束验证器评估
📋 核心要点
- 现有长文本生成基准要么难以验证真实性,要么过于简化,忽略了真实世界的复杂性。
- LongWeave通过CoV-Eval方法,在真实场景中定义可验证目标,并生成相应的查询、文本和约束,平衡了真实性和可评估性。
- 实验表明,即使是最先进的LLM在LongWeave基准上,随着文本长度和复杂性的增加,性能也会显著下降。
📝 摘要(中文)
大型语言模型(LLMs)生成长篇、信息丰富且事实准确的输出仍然是一个主要的挑战。现有的长文本生成基准通常评估具有难以验证的指标的真实世界查询,或者使用简化评估但忽略真实世界复杂性的合成设置。本文介绍了LongWeave,它通过约束验证器评估(CoV-Eval)平衡了真实世界和可验证的评估。CoV-Eval首先在真实世界场景中定义可验证的目标来构建任务,然后基于这些目标系统地生成相应的查询、文本材料和约束。这确保了任务既真实又可客观评估,从而能够严格评估模型在满足复杂真实世界约束方面的能力。LongWeave支持跨七个不同任务的可定制输入/输出长度(高达64K/8K tokens)。对23个LLM的评估表明,随着真实世界复杂性和输出长度的增加,即使是最先进的模型在长文本生成方面也面临着重大挑战。
🔬 方法详解
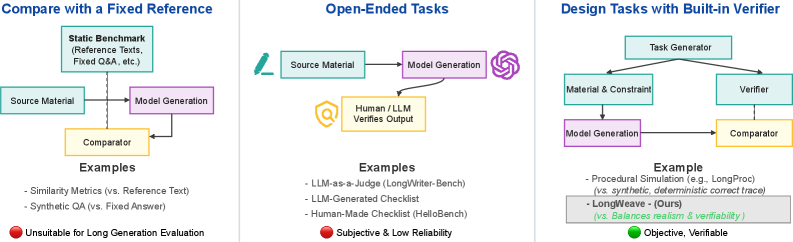
问题定义:现有长文本生成基准存在两个主要问题。一是真实世界基准难以验证生成内容的真实性,评估指标主观性强。二是合成基准虽然易于评估,但与真实世界的复杂场景脱节,无法有效评估模型在实际应用中的能力。因此,需要一个既能反映真实世界复杂性,又能进行客观评估的长文本生成基准。
核心思路:LongWeave的核心思路是采用Constraint-Verifier Evaluation (CoV-Eval)方法,将任务构建过程与可验证的目标对齐。具体来说,首先在真实世界场景中定义明确的可验证目标,然后基于这些目标生成相应的查询、文本材料和约束。这样,生成的任务既具有真实世界的复杂性,又可以通过预定义的目标进行客观评估。
技术框架:LongWeave的整体框架包含以下几个关键步骤:1) 目标定义:在特定真实世界场景中定义可验证的目标。2) 查询生成:基于目标生成相应的查询,模拟用户需求。3) 文本材料生成:收集或生成与查询相关的文本材料,作为模型生成长文本的参考。4) 约束生成:定义模型生成长文本需要满足的约束条件,例如事实一致性、逻辑连贯性等。5) 模型评估:使用CoV-Eval方法,根据预定义的目标和约束条件,对模型生成的长文本进行客观评估。
关键创新:LongWeave的关键创新在于CoV-Eval评估方法,它将任务构建与可验证的目标对齐,实现了真实世界复杂性和客观评估的平衡。与传统的评估方法相比,CoV-Eval能够更准确地评估模型在满足复杂真实世界约束方面的能力。
关键设计:LongWeave支持可定制的输入/输出长度,输入长度可达64K tokens,输出长度可达8K tokens。它包含七个不同的任务,涵盖了不同的真实世界场景和约束条件。评估指标包括事实一致性、逻辑连贯性、信息覆盖率等。此外,LongWeave还提供了详细的任务构建指南和评估工具,方便研究人员使用和扩展。
🖼️ 关键图片


📊 实验亮点
LongWeave基准对23个LLM进行了评估,结果表明,即使是最先进的模型在长文本生成方面也面临着重大挑战。随着真实世界复杂性和输出长度的增加,模型的性能显著下降。例如,在需要满足多个约束条件的任务中,模型的准确率明显低于单约束条件任务。这表明,当前LLM在处理复杂真实世界场景和生成长篇、信息丰富且事实准确的文本方面仍有很大的提升空间。
🎯 应用场景
LongWeave基准的潜在应用领域包括:智能客服、自动报告生成、内容创作、知识库构建等。通过LongWeave的评估,可以推动LLM在长文本生成方面的能力提升,使其更好地应用于实际场景,提高工作效率和信息质量。未来,LongWeave可以扩展到更多领域,并与其他评估方法相结合,形成更全面的LLM评估体系。
📄 摘要(原文)
Generating long, informative, and factual outputs remains a major challenge for Large Language Models (LLMs). Existing benchmarks for long-form generation typically assess real-world queries with hard-to-verify metrics or use synthetic setups that ease evaluation but overlook real-world intricacies. In this paper, we introduce \textbf{LongWeave}, which balances real-world and verifiable assessment with Constraint-Verifier Evaluation (CoV-Eval). CoV-Eval constructs tasks by first defining verifiable targets within real-world scenarios, then systematically generating corresponding queries, textual materials, and constraints based on these targets. This ensures that tasks are both realistic and objectively assessable, enabling rigorous assessment of model capabilities in meeting complex real-world constraints. LongWeave supports customizable input/output lengths (up to 64K/8K tokens) across seven distinct tasks. Evaluation on 23 LLMs shows that even state-of-the-art models encounter significant challenges in long-form generation as real-world complexity and output length increase.