Critique-RL: Training Language Models for Critiquing through Two-Stage Reinforcement Learning
作者: Zhiheng Xi, Jixuan Huang, Xin Guo, Boyang Hong, Dingwen Yang, Xiaoran Fan, Shuo Li, Zehui Chen, Junjie Ye, Siyu Yuan, Zhengyin Du, Xuesong Yao, Yufei Xu, Jiecao Chen, Rui Zheng, Tao Gui, Qi Zhang, Xuanjing Huang
分类: cs.CL, cs.AI
发布日期: 2025-10-28
备注: Preprint, 25 pages, 9 figures. Code: https://github.com/WooooDyy/Critique-RL
💡 一句话要点
提出Critique-RL,通过双阶段强化学习训练用于评价的语言模型。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 语言模型 评价模型 双阶段训练 奖励函数
📋 核心要点
- 现有方法依赖更强的监督信号标注评价数据,成本高昂且泛化性受限,难以有效提升语言模型在复杂推理任务中的性能。
- Critique-RL采用双阶段强化学习,首先增强评价模型的区分性,然后提高其帮助性,从而有效训练评价语言模型。
- 实验结果表明,Critique-RL在多个任务和模型上均取得了显著的性能提升,尤其是在领域外任务上表现出良好的泛化能力。
📝 摘要(中文)
本文提出Critique-RL,一种在线强化学习方法,用于在没有更强监督的情况下开发评价语言模型,旨在改进大型语言模型在复杂推理任务中的表现。该方法基于双人博弈范式:Actor生成响应,Critic提供反馈,Actor根据反馈改进响应。研究发现,仅依赖Actor输出的间接奖励信号进行强化学习优化,会导致Critic的区分性不足,性能提升有限。Critique-RL采用双阶段优化策略:第一阶段,利用基于规则的直接奖励信号增强Critic的区分性;第二阶段,引入基于Actor改进的间接奖励,提高Critic的帮助性,并通过正则化保持其区分性。在各种任务和模型上的大量实验表明,Critique-RL带来了显著的性能提升。例如,在Qwen2.5-7B上,在领域内任务上实现了9.02%的提升,在领域外任务上实现了5.70%的提升,突显了其潜力。
🔬 方法详解
问题定义:论文旨在解决训练用于评价语言模型(Critiquing Language Models)的问题,现有方法依赖于更强的监督信号,需要大量人工标注的评价数据,成本高昂且难以泛化。此外,仅依赖Actor输出的间接奖励信号进行强化学习优化,会导致Critic的区分性不足,难以有效判断响应的质量优劣。
核心思路:论文的核心思路是采用双阶段强化学习策略,分别优化Critic的区分性和帮助性。首先,通过直接的规则奖励来提升Critic区分高质量和低质量响应的能力;然后,利用Actor改进后的响应作为信号,间接提升Critic提供建设性反馈的能力,同时通过正则化手段保持其区分性。
技术框架:Critique-RL采用双人博弈框架,包含Actor和Critic两个模块。Actor负责生成响应,Critic负责评价Actor生成的响应并提供反馈。整个训练过程分为两个阶段:第一阶段,使用基于规则的奖励信号直接训练Critic,提升其区分性;第二阶段,利用Actor根据Critic反馈改进后的响应,间接训练Critic,提升其帮助性。Actor使用标准的强化学习算法进行训练,目标是最大化奖励。
关键创新:最重要的创新点在于双阶段强化学习策略,它解决了传统强化学习方法在训练评价模型时区分性和帮助性难以兼顾的问题。通过先提升区分性,再提升帮助性,并辅以正则化手段,使得Critic能够更有效地评价Actor的响应,并提供有价值的反馈。
关键设计:第一阶段,使用基于规则的奖励函数,例如,如果Critic能够正确区分高质量和低质量的响应,则给予正向奖励。第二阶段,使用Actor改进后的响应作为奖励信号,例如,如果Actor在接受Critic反馈后能够生成更好的响应,则给予Critic正向奖励。此外,还使用了正则化项来防止Critic的区分性在第二阶段训练中下降。具体的损失函数和网络结构细节在论文中进行了详细描述,但此处未提供。
🖼️ 关键图片
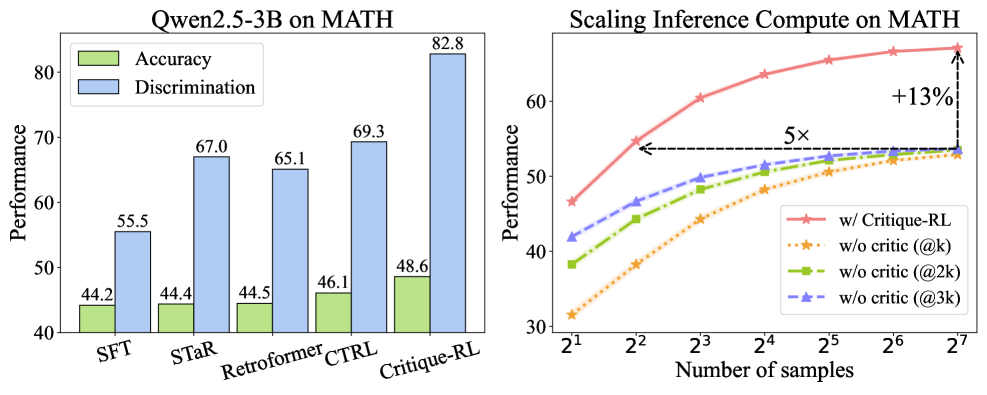
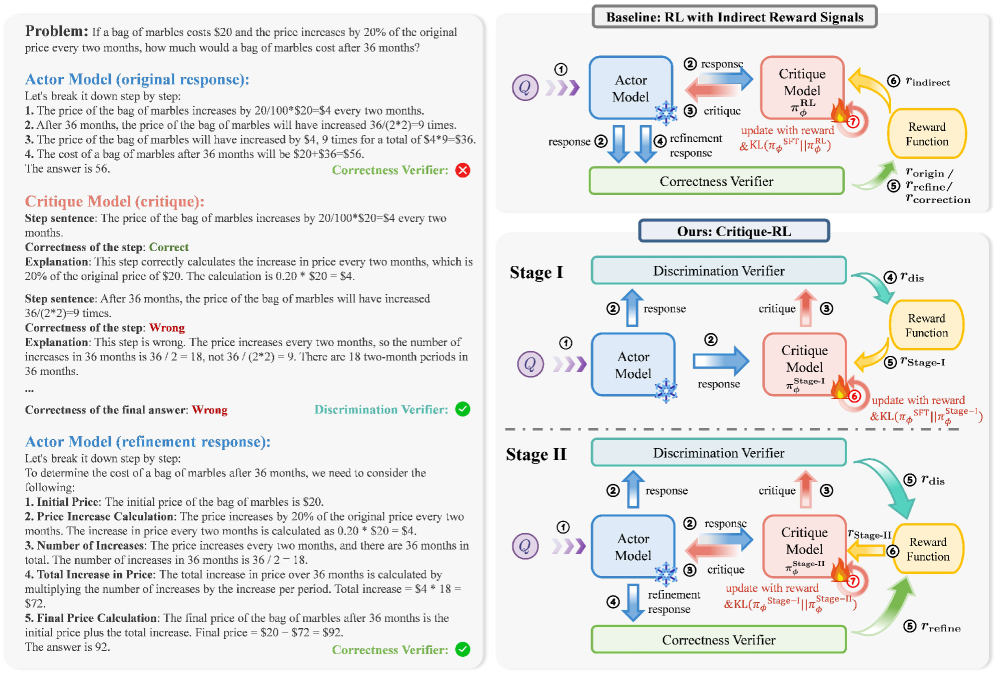
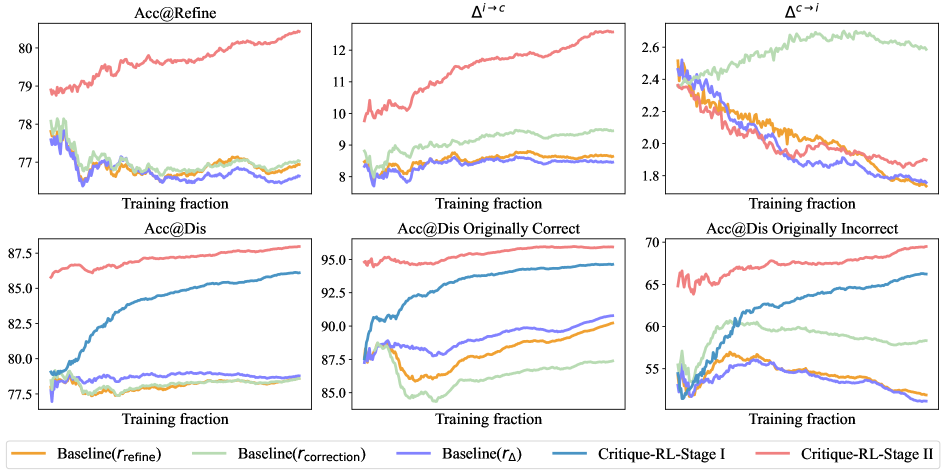
📊 实验亮点
Critique-RL在多个任务和模型上取得了显著的性能提升。例如,在Qwen2.5-7B模型上,在领域内任务上实现了9.02%的提升,在领域外任务上实现了5.70%的提升。这些结果表明,Critique-RL能够有效地训练评价语言模型,并提高大型语言模型的性能。
🎯 应用场景
Critique-RL具有广泛的应用前景,可用于提升大型语言模型在各种复杂推理任务中的表现,例如问答、代码生成、文本摘要等。通过训练高质量的评价模型,可以自动评估和改进语言模型的输出,从而提高模型的可靠性和实用性。此外,该方法还可以应用于教育领域,为学生提供个性化的反馈和指导。
📄 摘要(原文)
Training critiquing language models to assess and provide feedback on model outputs is a promising way to improve LLMs for complex reasoning tasks. However, existing approaches typically rely on stronger supervisors for annotating critique data. To address this, we propose Critique-RL, an online RL approach for developing critiquing language models without stronger supervision. Our approach operates on a two-player paradigm: the actor generates a response, the critic provides feedback, and the actor refines the response accordingly. We first reveal that relying solely on indirect reward signals from the actor's outputs for RL optimization often leads to unsatisfactory critics: while their helpfulness (i.e., providing constructive feedback) improves, the discriminability (i.e., determining whether a response is high-quality or not) remains poor, resulting in marginal performance gains. To overcome this, Critique-RL adopts a two-stage optimization strategy. In stage I, it reinforces the discriminability of the critic with direct rule-based reward signals; in stage II, it introduces indirect rewards based on actor refinement to improve the critic's helpfulness, while maintaining its discriminability via appropriate regularization. Extensive experiments across various tasks and models show that Critique-RL delivers substantial performance improvements. For example, it achieves a 9.02% gain on in-domain tasks and a 5.70% gain on out-of-domain tasks for Qwen2.5-7B, highlighting its potential.