Can LLMs Translate Human Instructions into a Reinforcement Learning Agent's Internal Emergent Symbolic Representation?
作者: Ziqi Ma, Sao Mai Nguyen, Philippe Xu
分类: cs.CL, cs.RO
发布日期: 2025-10-28
💡 一句话要点
研究LLM能否将人类指令翻译为强化学习Agent的内部符号表征
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 强化学习 符号表征 人机交互 表征对齐
📋 核心要点
- 现有强化学习Agent难以有效规划和泛化,内部符号表征的涌现是关键,但如何与人类指令对齐是挑战。
- 本文探索LLM能否将人类自然语言指令转化为强化学习Agent的内部符号表征,实现语言与Agent认知的桥梁。
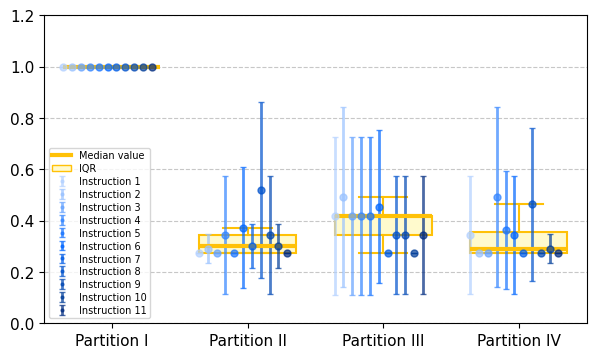
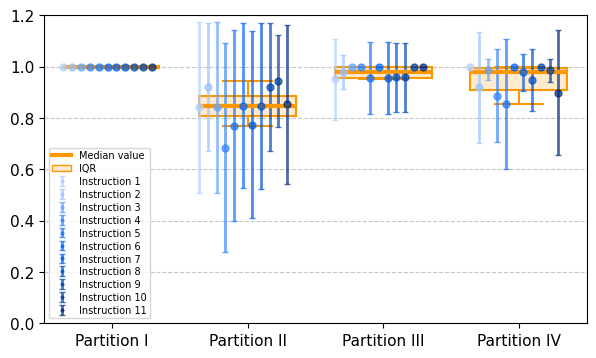
- 实验表明,LLM具备一定的翻译能力,但性能受环境复杂度影响,揭示了当前LLM在表征对齐方面的不足。
📝 摘要(中文)
本文研究大型语言模型(LLM)是否能够将人类自然语言指令翻译成层级强化学习中涌现的内部符号表征,这对于发展型学习Agent规划和泛化至关重要。我们采用结构化评估框架,测量了常见LLM(GPT、Claude、Deepseek和Grok)在Ant Maze和Ant Fall环境中,针对层级强化学习算法生成的不同内部符号划分的翻译性能。结果表明,尽管LLM在将自然语言翻译成环境动态的符号表征方面表现出一定的能力,但其性能对划分粒度和任务复杂度高度敏感。这些结果揭示了当前LLM在表征对齐方面的局限性,强调了未来需要进一步研究语言和Agent内部表征之间的鲁棒对齐。
🔬 方法详解
问题定义:论文旨在解决如何将人类的自然语言指令有效地转化为强化学习Agent能够理解和利用的内部符号表征的问题。现有方法缺乏有效的机制来实现人类意图与Agent内部状态的对齐,导致Agent难以理解复杂指令,限制了其在复杂环境中的规划和泛化能力。
核心思路:论文的核心思路是利用大型语言模型(LLM)强大的自然语言理解和生成能力,将其作为人类指令和Agent内部符号表征之间的翻译器。通过训练LLM,使其能够将人类指令映射到Agent在层级强化学习过程中涌现的符号表征,从而实现语言与Agent认知的对齐。
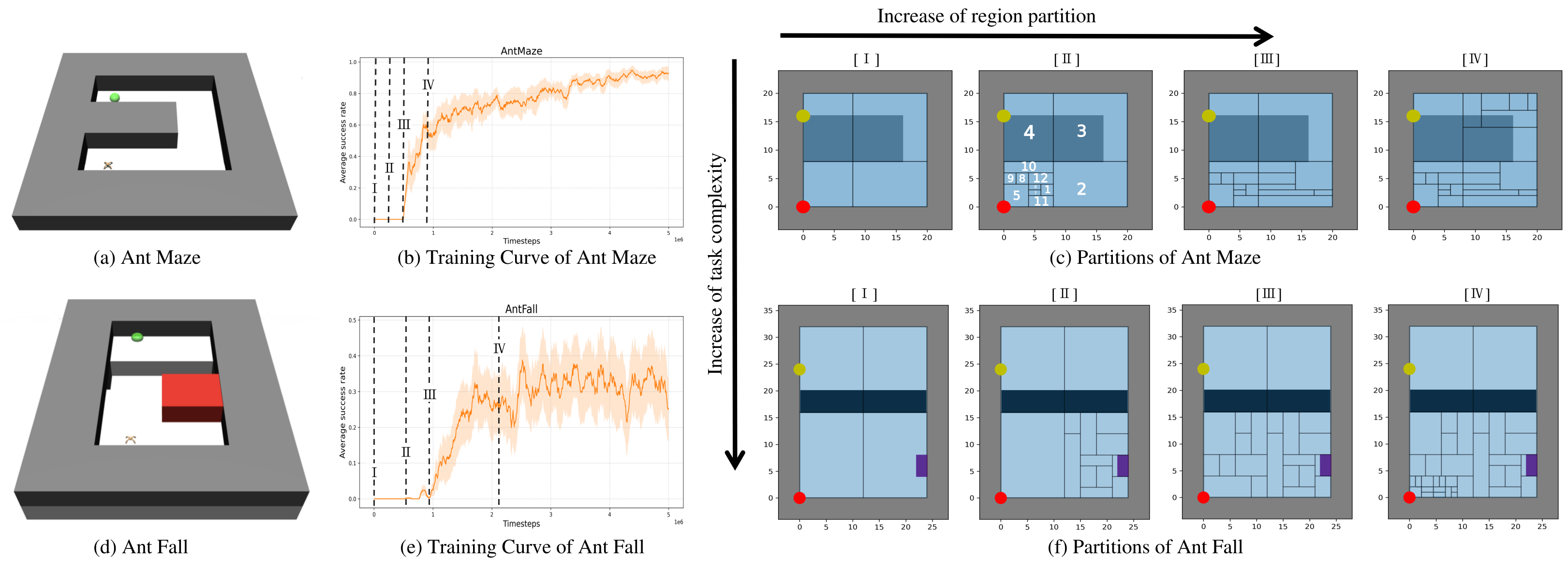
技术框架:整体框架包括三个主要部分:首先,使用层级强化学习算法训练Agent,使其在特定环境中学习并涌现出内部符号表征;其次,构建一个结构化的评估框架,用于测量LLM将自然语言指令翻译成这些内部符号表征的性能;最后,使用不同的LLM(如GPT、Claude、Deepseek和Grok)进行实验,并分析其翻译性能与环境复杂度、符号划分粒度等因素之间的关系。
关键创新:最重要的技术创新点在于探索了利用LLM作为桥梁,实现人类指令与强化学习Agent内部符号表征的对齐。与传统方法相比,该方法无需手动设计复杂的符号表征,而是利用LLM的强大能力自动学习和翻译,从而提高了Agent的灵活性和适应性。
关键设计:论文的关键设计包括:1)使用Ant Maze和Ant Fall等复杂环境,以测试LLM在不同任务复杂度下的翻译性能;2)采用不同的符号划分粒度,以评估LLM对不同抽象层次的表征的理解能力;3)构建结构化的评估框架,包括准确率、召回率等指标,以量化LLM的翻译性能。
🖼️ 关键图片
📊 实验亮点
实验结果表明,LLM在将自然语言翻译成环境动态的符号表征方面表现出一定的能力,但其性能对划分粒度和任务复杂度高度敏感。例如,在简单的Ant Maze环境中,LLM的翻译准确率较高,但在复杂的Ant Fall环境中,性能显著下降。这表明当前LLM在表征对齐方面仍存在局限性,需要进一步研究。
🎯 应用场景
该研究成果可应用于人机协作机器人、智能游戏Agent、自动驾驶等领域。通过将人类指令转化为Agent可理解的内部表征,可以显著提升Agent的智能化水平和人机交互体验,使其能够更好地理解人类意图并完成复杂任务。未来,该技术有望推动通用人工智能的发展。
📄 摘要(原文)
Emergent symbolic representations are critical for enabling developmental learning agents to plan and generalize across tasks. In this work, we investigate whether large language models (LLMs) can translate human natural language instructions into the internal symbolic representations that emerge during hierarchical reinforcement learning. We apply a structured evaluation framework to measure the translation performance of commonly seen LLMs -- GPT, Claude, Deepseek and Grok -- across different internal symbolic partitions generated by a hierarchical reinforcement learning algorithm in the Ant Maze and Ant Fall environments. Our findings reveal that although LLMs demonstrate some ability to translate natural language into a symbolic representation of the environment dynamics, their performance is highly sensitive to partition granularity and task complexity. The results expose limitations in current LLMs capacity for representation alignment, highlighting the need for further research on robust alignment between language and internal agent representations.