Evaluating LLMs on Generating Age-Appropriate Child-Like Conversations
作者: Syed Zohaib Hassan, Pål Halvorsen, Miriam S. Johnson, Pierre Lison
分类: cs.CL
发布日期: 2025-10-28
备注: 11 pages excluding references and appendix. 3 figures and 6 tables
💡 一句话要点
评估大型语言模型在生成适合儿童年龄段对话方面的能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 儿童对话生成 年龄适宜性 人工评估 低资源语言
📋 核心要点
- 现有大型语言模型主要基于成人数据训练,难以生成真实的儿童对话,限制了其在教育等领域的应用。
- 该研究通过对比评估多个LLM在生成适合特定年龄段儿童的挪威语对话方面的表现,揭示了现有模型的不足。
- 实验结果表明,现有模型在生成儿童对话方面存在局限性,尤其是在低资源语言中,需要更多针对性训练数据。
📝 摘要(中文)
大型语言模型(LLMs)主要基于成人对话数据进行训练,在为特定应用生成真实的儿童对话时面临重大挑战。本研究对比评估了五个不同的LLMs(GPT-4、RUTER-LLAMA-2-13b、GPTSW、NorMistral-7b和NorBloom-7b),以生成适合5岁和9岁儿童年龄段的挪威语对话。通过由11位教育专业人士进行的盲评估,使用真实儿童访谈数据和LLM生成的文本样本,我们评估了真实性和发展适宜性。结果表明,评估者实现了很高的评分者间信度(ICC=0.75),并且在预测较小儿童(5岁)的年龄方面比预测较大儿童(9岁)的年龄方面具有更高的准确性。虽然GPT-4和NorBloom-7b表现相对较好,但大多数模型生成的语言被认为比目标年龄组的语言更高级。这些发现突出了在为涉及儿童的特定应用开发LLM系统时,与数据相关的关键挑战,尤其是在缺乏全面的、适合年龄段的词汇资源的低资源语言中。
🔬 方法详解
问题定义:论文旨在评估大型语言模型(LLMs)在生成适合特定年龄段(5岁和9岁)儿童的对话方面的能力。现有LLMs主要基于成人对话数据训练,直接应用于儿童对话生成时,无法保证生成内容的真实性和发展适宜性,尤其是在低资源语言(如挪威语)中,缺乏针对儿童的训练数据和词汇资源,问题更为突出。
核心思路:论文的核心思路是通过人工评估的方式,对比分析不同LLMs生成的对话文本与真实儿童对话的相似度,从而评估LLMs在儿童对话生成方面的能力。通过教育专业人士的盲评估,可以有效避免主观偏差,更客观地反映LLMs的性能。
技术框架:该研究的技术框架主要包括以下几个步骤:1) 选择五个不同的LLMs(GPT-4、RUTER-LLAMA-2-13b、GPTSW、NorMistral-7b和NorBloom-7b);2) 使用这些LLMs生成适合5岁和9岁儿童年龄段的挪威语对话文本;3) 收集真实儿童的访谈数据作为对比;4) 邀请11位教育专业人士进行盲评估,评估LLM生成文本的真实性和发展适宜性;5) 分析评估结果,包括评分者间信度(ICC)和年龄预测准确率。
关键创新:该研究的关键创新在于:1) 针对儿童对话生成这一特定应用场景,系统性地评估了多个LLMs的性能;2) 采用人工盲评估的方式,保证了评估结果的客观性和可靠性;3) 关注低资源语言(挪威语)中的儿童对话生成问题,具有一定的现实意义。
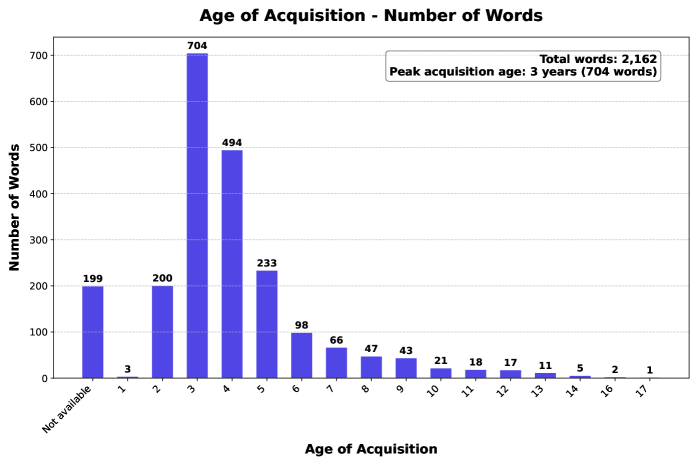
关键设计:评估指标包括:1) 真实性:评估LLM生成的对话是否听起来像真实的儿童对话;2) 发展适宜性:评估LLM生成的对话是否符合目标年龄段儿童的语言发展水平。评分者间信度(ICC)用于衡量评估结果的一致性。年龄预测准确率用于衡量评估者区分不同年龄段儿童对话的能力。
🖼️ 关键图片
📊 实验亮点
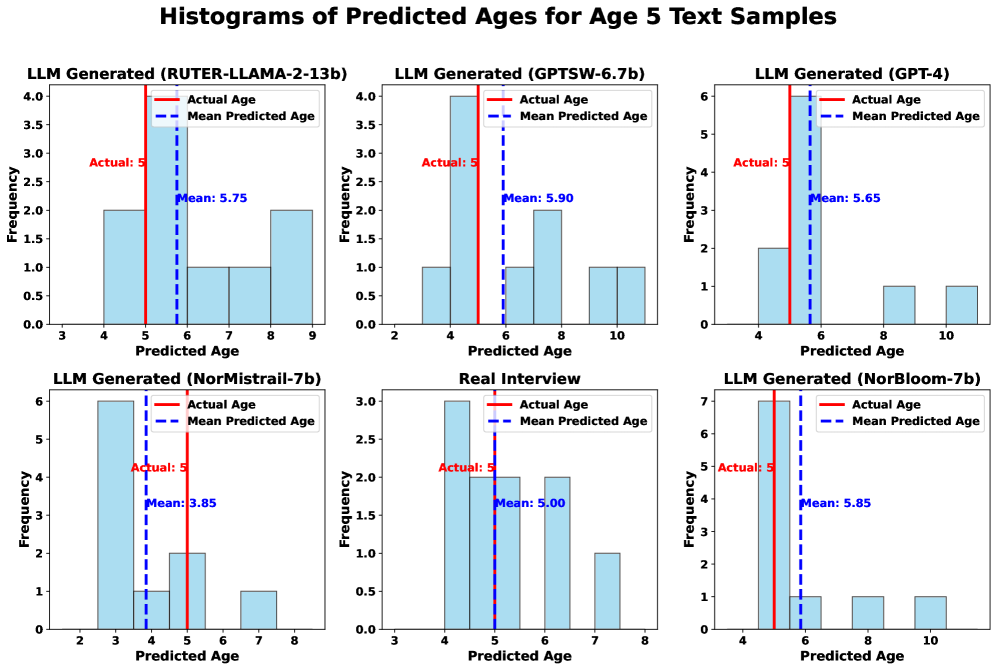
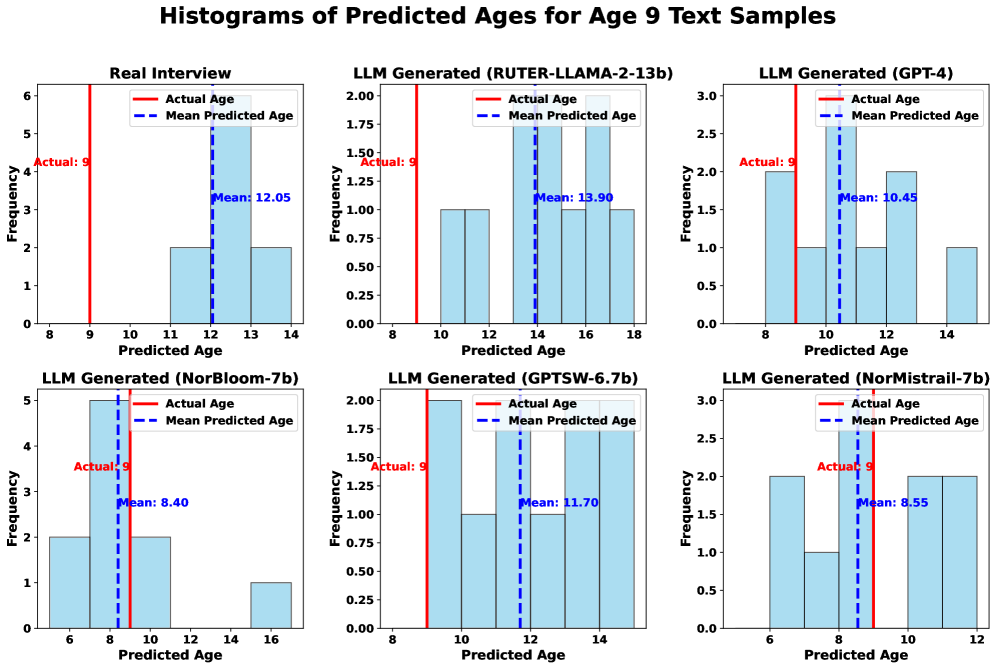
实验结果表明,GPT-4和NorBloom-7b在生成儿童对话方面表现相对较好,但大多数模型生成的语言被认为比目标年龄组的语言更高级。评估者实现了很高的评分者间信度(ICC=0.75),并且在预测较小儿童(5岁)的年龄方面比预测较大儿童(9岁)的年龄方面具有更高的准确性。这些结果突出了现有LLM在生成儿童对话方面的局限性,以及针对儿童数据的必要性。
🎯 应用场景
该研究成果可应用于儿童教育、儿童心理健康咨询、儿童陪伴机器人等领域。通过提升LLM生成儿童对话的真实性和发展适宜性,可以开发更有效的儿童教育工具和更具人情味的陪伴机器人,从而促进儿童的健康成长。未来,可以进一步研究如何利用少量儿童数据微调LLM,以提高其在儿童对话生成方面的性能。
📄 摘要(原文)
Large Language Models (LLMs), predominantly trained on adult conversational data, face significant challenges when generating authentic, child-like dialogue for specialized applications. We present a comparative study evaluating five different LLMs (GPT-4, RUTER-LLAMA-2-13b, GPTSW, NorMistral-7b, and NorBloom-7b) to generate age-appropriate Norwegian conversations for children aged 5 and 9 years. Through a blind evaluation by eleven education professionals using both real child interview data and LLM-generated text samples, we assessed authenticity and developmental appropriateness. Our results show that evaluators achieved strong inter-rater reliability (ICC=0.75) and demonstrated higher accuracy in age prediction for younger children (5-year-olds) compared to older children (9-year-olds). While GPT-4 and NorBloom-7b performed relatively well, most models generated language perceived as more linguistically advanced than the target age groups. These findings highlight critical data-related challenges in developing LLM systems for specialized applications involving children, particularly in low-resource languages where comprehensive age-appropriate lexical resources are scarce.