Beyond Neural Incompatibility: Easing Cross-Scale Knowledge Transfer in Large Language Models through Latent Semantic Alignment
作者: Jian Gu, Aldeida Aleti, Chunyang Chen, Hongyu Zhang
分类: cs.CL, cs.LG
发布日期: 2025-10-28
备注: an early-stage version
💡 一句话要点
提出基于潜在语义对齐的跨尺度知识迁移方法,提升大语言模型性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 知识迁移 跨尺度学习 语义对齐 模型压缩
📋 核心要点
- 现有跨尺度知识迁移方法受限于神经不兼容性,直接重用参数效果不佳。
- 该论文提出基于潜在语义对齐的知识迁移方法,利用激活作为媒介。
- 实验表明,该方法优于现有方法,并在多个基准测试中取得了显著提升。
📝 摘要(中文)
大型语言模型(LLM)在其庞大的参数中编码了大量的知识,这些知识可以被定位、追踪和分析。尽管神经可解释性方面取得了进展,但如何以细粒度的方式转移知识,即参数化知识转移(PKT),仍然不清楚。一个关键问题是实现跨不同尺度LLM之间有效且高效的知识转移,这对于在LLM之间转移知识时实现更大的灵活性和更广泛的适用性至关重要。由于神经不兼容性,即不同尺度的LLM之间的架构和参数差异,直接重用层参数的现有方法受到严重限制。本文认为潜在空间中的语义对齐是LLM跨尺度知识转移的根本前提。我们的方法不直接使用层参数,而是将激活作为层间知识转移的媒介。利用潜在空间中的语义,我们的方法简单且优于先前的工作,更好地对齐了不同尺度的模型行为。在四个基准上的评估证明了我们方法的有效性。进一步的分析揭示了促进跨尺度知识转移的关键因素,并提供了对潜在语义对齐本质的见解。
🔬 方法详解
问题定义:现有的大语言模型知识迁移方法,尤其是跨尺度迁移,面临着“神经不兼容性”的挑战。不同规模的模型在架构和参数上存在差异,直接复用参数会导致性能下降。因此,如何克服这种不兼容性,实现有效且高效的跨尺度知识迁移是亟待解决的问题。现有方法往往难以在保证迁移效率的同时,维持或提升目标模型的性能。
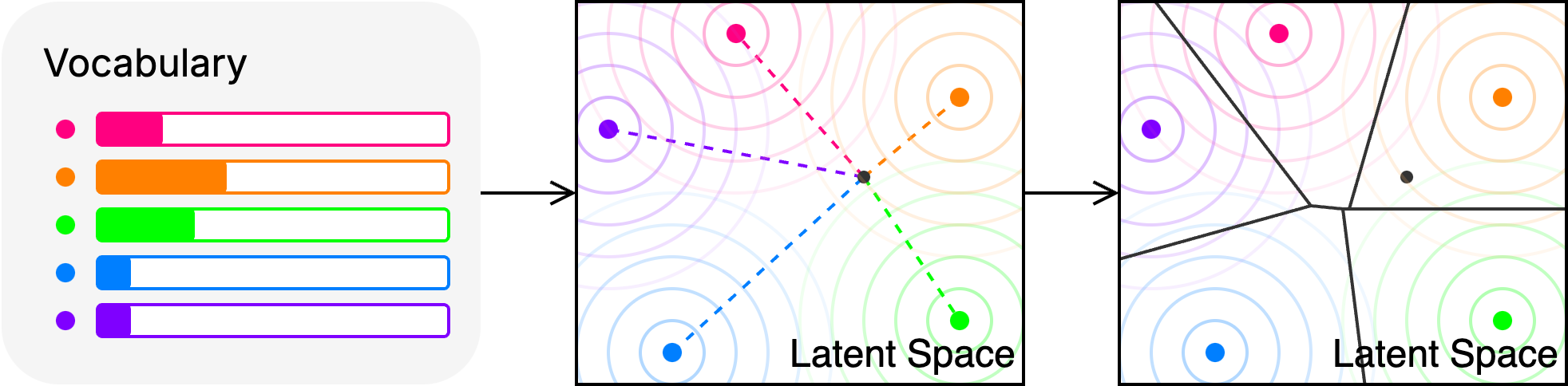
核心思路:该论文的核心思路是,将潜在空间中的语义对齐作为跨尺度知识迁移的关键。作者认为,与其直接迁移参数,不如关注模型在各层激活中蕴含的语义信息。通过对齐不同尺度模型在潜在空间中的语义表示,可以克服神经不兼容性带来的问题,从而实现更有效的知识迁移。这种方法的核心在于,语义信息比具体的参数更能代表模型的知识。
技术框架:该方法主要包含以下几个阶段:1) 选择源模型和目标模型,二者尺度不同;2) 对于源模型和目标模型的每一层,提取其激活值作为知识转移的媒介;3) 设计一种对齐机制,使得源模型和目标模型在对应层的激活空间中具有相似的语义表示;4) 利用对齐后的激活空间,将知识从源模型迁移到目标模型。具体而言,该方法通过最小化源模型和目标模型在潜在空间中的距离来实现语义对齐。
关键创新:该论文最重要的创新点在于,它将潜在语义对齐作为跨尺度知识迁移的根本前提。与直接迁移参数的传统方法不同,该方法关注模型在激活空间中的语义表示,从而克服了神经不兼容性带来的问题。这种基于语义的迁移方法更加灵活,可以更好地适应不同尺度的模型。此外,该方法还提供了一种新的视角来理解大语言模型中的知识表示和迁移。
关键设计:该方法的关键设计包括:1) 如何选择合适的激活作为知识转移的媒介;2) 如何设计有效的对齐机制,使得源模型和目标模型在潜在空间中具有相似的语义表示;3) 如何衡量源模型和目标模型在潜在空间中的距离,例如可以使用余弦相似度或KL散度等指标;4) 如何将对齐后的激活空间用于知识迁移,例如可以通过微调目标模型来实现。
🖼️ 关键图片


📊 实验亮点
该方法在四个基准测试中均取得了优于现有方法的性能。实验结果表明,该方法能够有效地对齐不同尺度模型之间的语义表示,从而实现更有效的知识迁移。具体的性能提升数据需要在论文中查找,但总体趋势是显著优于现有方法。
🎯 应用场景
该研究成果可应用于大语言模型的压缩与加速、模型蒸馏、终身学习等领域。通过将大型模型的知识迁移到小型模型,可以在资源受限的设备上部署高性能的语言模型。此外,该方法还可以用于构建更加灵活和可扩展的语言模型系统,实现知识的持续积累和迁移。
📄 摘要(原文)
Large Language Models (LLMs) encode vast amounts of knowledge in their massive parameters, which is accessible to locate, trace, and analyze. Despite advances in neural interpretability, it is still not clear how to transfer knowledge in a fine-grained manner, namely parametric knowledge transfer (PKT). A key problem is enabling effective and efficient knowledge transfer across LLMs of different scales, which is essential for achieving greater flexibility and broader applicability in transferring knowledge between LLMs. Due to neural incompatibility, referring to the architectural and parametric differences between LLMs of varying scales, existing methods that directly reuse layer parameters are severely limited. In this paper, we identify the semantic alignment in latent space as the fundamental prerequisite for LLM cross-scale knowledge transfer. Instead of directly using the layer parameters, our approach takes activations as the medium of layer-wise knowledge transfer. Leveraging the semantics in latent space, our approach is simple and outperforms prior work, better aligning model behaviors across varying scales. Evaluations on four benchmarks demonstrate the efficacy of our method. Further analysis reveals the key factors easing cross-scale knowledge transfer and provides insights into the nature of latent semantic alignment.