MuSaG: A Multimodal German Sarcasm Dataset with Full-Modal Annotations
作者: Aaron Scott, Maike Züfle, Jan Niehues
分类: cs.CL, cs.AI
发布日期: 2025-10-28
💡 一句话要点
提出MuSaG:一个带完整模态标注的德语多模态讽刺数据集,用于提升讽刺检测模型性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态讽刺检测 德语数据集 自然语言理解 情感分析 人机交互 音频模态 视频模态
📋 核心要点
- 讽刺检测是自然语言理解的难点,现有方法难以有效融合多模态信息,尤其是在德语等资源较少的语种。
- MuSaG数据集通过人工标注对齐的文本、音频和视频模态,为德语多模态讽刺检测提供了高质量的训练和评估资源。
- 实验表明,现有模型在文本模态上表现最佳,但在音频模态上与人类表现存在差距,揭示了多模态融合的挑战。
📝 摘要(中文)
讽刺是一种复杂的比喻语言形式,其意图与字面意义相反。它在社交媒体和流行文化中的普遍存在对自然语言理解、情感分析和内容审核提出了持续的挑战。随着多模态大型语言模型的出现,讽刺检测超越了文本,需要整合来自音频和视觉的线索。我们提出了MuSaG,这是第一个德语多模态讽刺检测数据集,包含从德国电视节目中手动选择和人工标注的33分钟的陈述。每个实例都提供对齐的文本、音频和视频模态,并由人工分别标注,从而可以在单模态和多模态设置中进行评估。我们对九个开源和商业模型进行了基准测试,涵盖文本、音频、视觉和多模态架构,并将它们的性能与人工标注进行了比较。结果表明,虽然人类在对话环境中严重依赖音频,但模型在文本上的表现最佳。这突出了当前多模态模型中的差距,并促使使用MuSaG来开发更适合真实场景的模型。我们公开发布MuSaG,以支持未来对多模态讽刺检测和人机对齐的研究。
🔬 方法详解
问题定义:论文旨在解决德语多模态讽刺检测中缺乏高质量数据集的问题。现有方法在处理讽刺时,往往只关注文本信息,忽略了音频和视觉信息的重要性,导致检测精度不高。此外,现有的多模态讽刺检测数据集大多是英语的,缺乏其他语种的数据集,限制了多语种讽刺检测的研究。
核心思路:论文的核心思路是构建一个包含文本、音频和视频三种模态的德语讽刺数据集,并对每个模态进行人工标注。通过提供高质量的多模态数据,可以促进多模态讽刺检测模型的发展,提高讽刺检测的准确率。
技术框架:MuSaG数据集的构建流程主要包括以下几个步骤:1) 从德国电视节目中手动选择包含讽刺的片段;2) 对每个片段进行人工标注,包括文本、音频和视频三种模态;3) 对标注数据进行清洗和整理,确保数据的质量;4) 将数据集公开发布,供研究人员使用。数据集包含33分钟的音频和视频数据,以及相应的文本标注。
关键创新:MuSaG数据集的主要创新点在于:1) 它是第一个德语多模态讽刺检测数据集;2) 它包含了文本、音频和视频三种模态的信息,可以用于研究多模态讽刺检测;3) 它经过人工标注,具有较高的质量。与现有数据集相比,MuSaG数据集更加全面和准确,可以更好地支持多模态讽刺检测的研究。
关键设计:数据集的标注由人工完成,以保证标注的准确性。每个实例都包含对齐的文本、音频和视频模态。论文还对九个开源和商业模型进行了基准测试,涵盖文本、音频、视觉和多模态架构,为未来的研究提供了参考。
🖼️ 关键图片
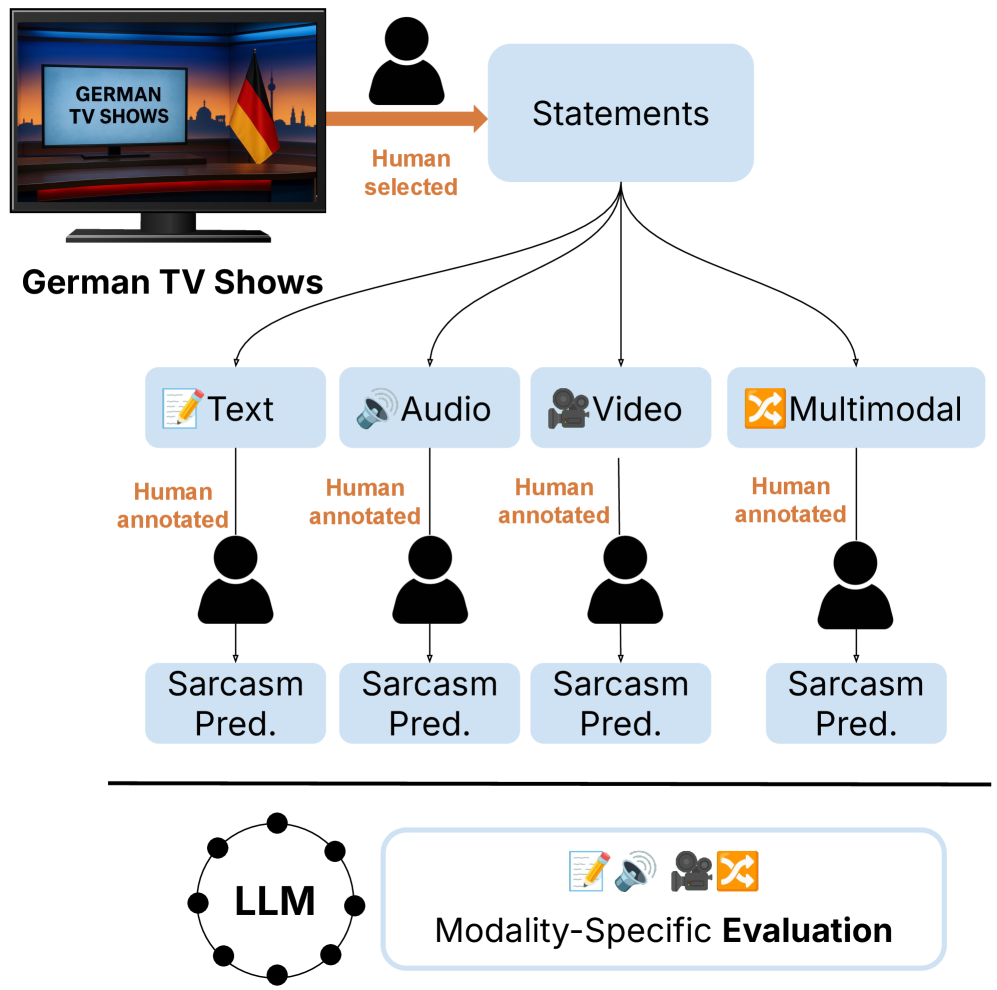

📊 实验亮点
实验结果表明,现有模型在文本模态上的表现最佳,但在音频模态上的表现与人类存在较大差距。例如,人类在对话环境中严重依赖音频进行讽刺判断,但模型在音频模态上的性能远低于文本模态。这表明当前的多模态模型在融合不同模态信息方面仍存在不足,需要进一步改进。
🎯 应用场景
该研究成果可应用于社交媒体内容审核、情感分析、人机对话等领域。通过提高讽刺检测的准确率,可以更有效地过滤不良信息,提升用户体验,并使AI系统能够更好地理解人类语言的复杂性,从而实现更自然的人机交互。
📄 摘要(原文)
Sarcasm is a complex form of figurative language in which the intended meaning contradicts the literal one. Its prevalence in social media and popular culture poses persistent challenges for natural language understanding, sentiment analysis, and content moderation. With the emergence of multimodal large language models, sarcasm detection extends beyond text and requires integrating cues from audio and vision. We present MuSaG, the first German multimodal sarcasm detection dataset, consisting of 33 minutes of manually selected and human-annotated statements from German television shows. Each instance provides aligned text, audio, and video modalities, annotated separately by humans, enabling evaluation in unimodal and multimodal settings. We benchmark nine open-source and commercial models, spanning text, audio, vision, and multimodal architectures, and compare their performance to human annotations. Our results show that while humans rely heavily on audio in conversational settings, models perform best on text. This highlights a gap in current multimodal models and motivates the use of MuSaG for developing models better suited to realistic scenarios. We release MuSaG publicly to support future research on multimodal sarcasm detection and human-model alignment.