Reinforcement Learning for Long-Horizon Multi-Turn Search Agents
作者: Vivek Kalyan, Martin Andrews
分类: cs.CL
发布日期: 2025-10-28
备注: 4 pages plus references and appendices. Accepted into the First Workshop on Multi-Turn Interactions in Large Language Models at NeurIPS 2025
💡 一句话要点
提出基于强化学习的长程多轮搜索Agent,显著提升法律文档搜索精度。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 大型语言模型 多轮搜索 法律文档检索 Agent 长程交互 策略学习
📋 核心要点
- 现有基于Prompt的LLM Agent在复杂任务中表现良好,但缺乏从经验中学习的能力,性能提升受限。
- 提出使用强化学习训练LLM Agent,使其能够通过与环境交互学习,从而提升解决复杂任务的能力。
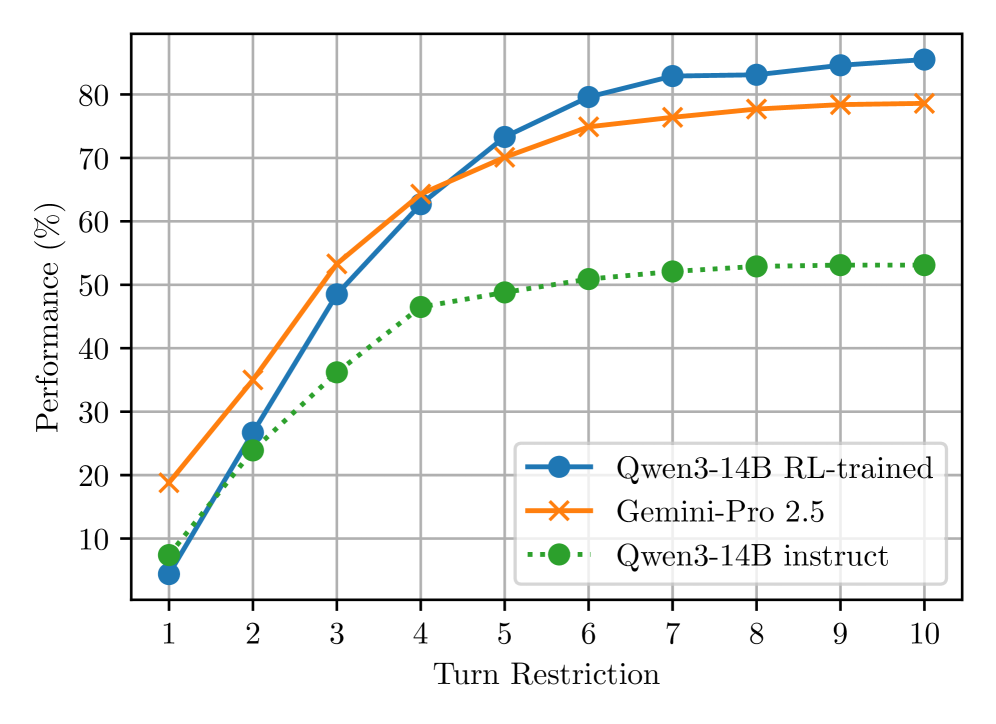
- 实验表明,RL训练的Agent在法律文档搜索任务中显著优于现有模型,尤其是在允许更多交互轮数的情况下。
📝 摘要(中文)
本文研究了如何利用大型语言模型(LLM)Agent通过多轮交互和工具使用来解决复杂任务。虽然基于Prompt的方法已经取得了不错的性能,但本文证明了强化学习(RL)可以通过从经验中学习,进一步显著提升Agent的能力。在法律文档搜索基准测试上的实验表明,经过RL训练的140亿参数模型优于前沿模型(准确率分别为85%和78%)。此外,我们还探索了在训练和测试期间限制交互轮数的机制,结果表明,允许Agent在更长的多轮交互范围内操作可以获得更好的结果。
🔬 方法详解
问题定义:论文旨在解决LLM Agent在长程多轮搜索任务中,如何有效利用经验进行学习,从而提升搜索准确率的问题。现有基于Prompt的方法虽然有效,但缺乏从错误中学习和优化策略的能力,难以达到最优性能。
核心思路:论文的核心思路是利用强化学习(RL)训练LLM Agent,使其能够通过与环境(例如法律文档数据库)的交互,学习到更有效的搜索策略。通过奖励机制,鼓励Agent进行更准确、更高效的搜索。
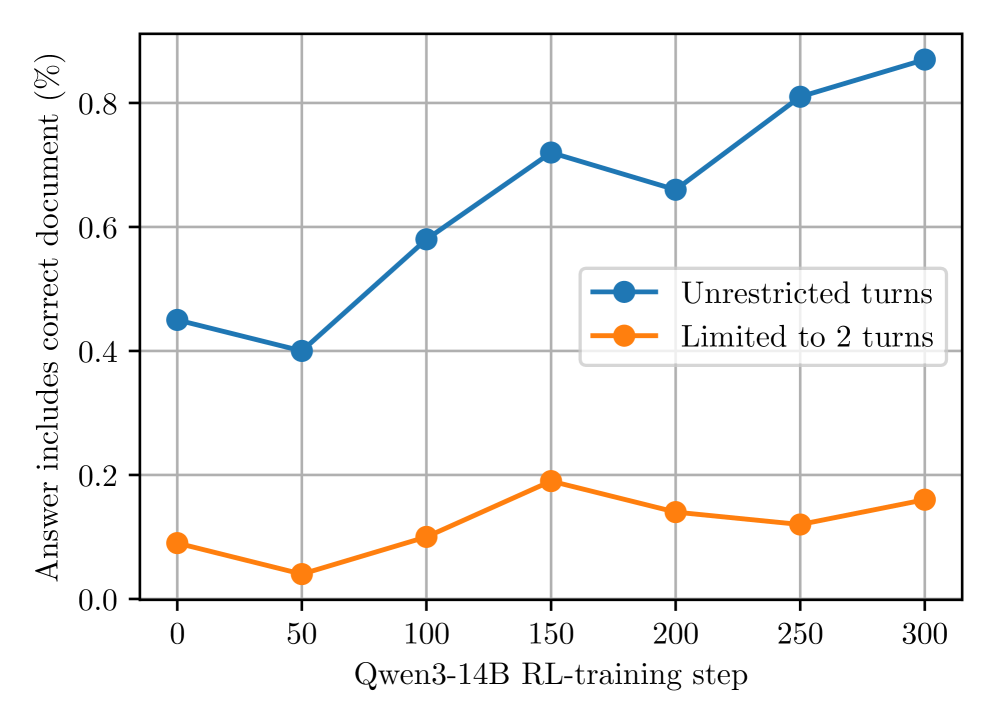
技术框架:整体框架包含一个LLM Agent和一个环境。Agent根据当前状态(例如搜索历史、用户query)选择一个动作(例如搜索关键词、调整搜索策略),环境执行该动作并返回新的状态和奖励。使用RL算法(具体算法未知)训练Agent,使其最大化累积奖励。训练过程中,可以限制交互轮数,以研究不同交互深度对性能的影响。
关键创新:关键创新在于将强化学习引入到LLM Agent的训练中,使其能够从经验中学习,克服了传统Prompt方法的局限性。通过设计合适的奖励函数,引导Agent学习到更优的搜索策略。
关键设计:论文的关键设计包括:1) 如何将法律文档搜索任务建模为马尔可夫决策过程(MDP);2) 如何设计奖励函数,以鼓励准确和高效的搜索;3) 如何选择合适的RL算法进行训练(论文中未明确指出具体算法,属于未知信息);4) 如何设置训练和测试期间的交互轮数限制。
🖼️ 关键图片
📊 实验亮点
实验结果表明,经过RL训练的140亿参数模型在法律文档搜索基准测试中取得了85%的准确率,显著优于前沿模型(78%)。此外,研究还发现,允许Agent在更长的多轮交互范围内操作可以获得更好的结果,表明RL能够有效利用多轮交互信息。
🎯 应用场景
该研究成果可应用于各种需要长程多轮交互的搜索任务,例如法律、医学、金融等领域的文档检索、智能客服、对话式推荐系统等。通过强化学习训练Agent,可以显著提升搜索效率和准确率,为用户提供更优质的信息服务,并降低人工成本。
📄 摘要(原文)
Large Language Model (LLM) agents can leverage multiple turns and tools to solve complex tasks, with prompt-based approaches achieving strong performance. This work demonstrates that Reinforcement Learning (RL) can push capabilities significantly further by learning from experience. Through experiments on a legal document search benchmark, we show that our RL-trained 14 Billion parameter model outperforms frontier class models (85% vs 78% accuracy). In addition, we explore turn-restricted regimes, during training and at test-time, that show these agents achieve better results if allowed to operate over longer multi-turn horizons.