Pie: A Programmable Serving System for Emerging LLM Applications
作者: In Gim, Zhiyao Ma, Seung-seob Lee, Lin Zhong
分类: cs.CL
发布日期: 2025-10-28
备注: SOSP 2025. Source code available at https://github.com/pie-project/pie
💡 一句话要点
Pie:一种可编程的LLM服务系统,为新兴应用提供灵活高效的支持
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM服务系统 可编程性 WebAssembly 代理工作流 推理优化 KV缓存 细粒度服务
📋 核心要点
- 现有LLM服务系统难以满足新兴应用中多样化的推理策略和代理工作流的需求。
- Pie通过将生成循环分解为细粒度的服务处理器,并允许用户自定义inferlet来控制生成过程,实现灵活的服务。
- 实验表明,Pie在标准任务上性能与现有系统相当,但在代理工作流中显著提升了延迟和吞吐量。
📝 摘要(中文)
新兴的大型语言模型(LLM)应用涉及多样化的推理策略和代理工作流,这对现有基于单片token生成循环的服务系统提出了挑战。本文介绍了Pie,一种为灵活性和效率而设计的可编程LLM服务系统。Pie将传统的生成循环分解为细粒度的服务处理器,并通过API暴露,并将生成过程的控制权委托给用户提供的程序,称为inferlet。这使得应用程序能够实现新的KV缓存策略、定制的生成逻辑,并无缝集成计算和I/O,而无需修改服务系统。Pie使用WebAssembly执行inferlet,受益于其轻量级沙箱。评估表明,Pie在标准任务上与最先进的性能相匹配(3-12%的延迟开销),同时通过启用特定于应用程序的优化,显著提高了代理工作流的延迟和吞吐量(提高了1.3倍-3.4倍)。
🔬 方法详解
问题定义:现有的大型语言模型服务系统通常基于单片token生成循环,缺乏灵活性,难以支持新兴LLM应用中复杂多样的推理策略和代理工作流。这些应用需要定制化的KV缓存管理、生成逻辑以及计算和I/O的集成,而现有系统难以满足这些需求,需要频繁修改底层服务系统。
核心思路:Pie的核心思路是将LLM服务系统解耦为细粒度的服务处理器,并通过API暴露这些处理器。用户可以通过编写inferlet(用户提供的程序)来控制生成过程,实现定制化的KV缓存策略、生成逻辑以及计算和I/O的集成。这样,应用程序可以在不修改底层服务系统的情况下,实现特定于应用的优化。
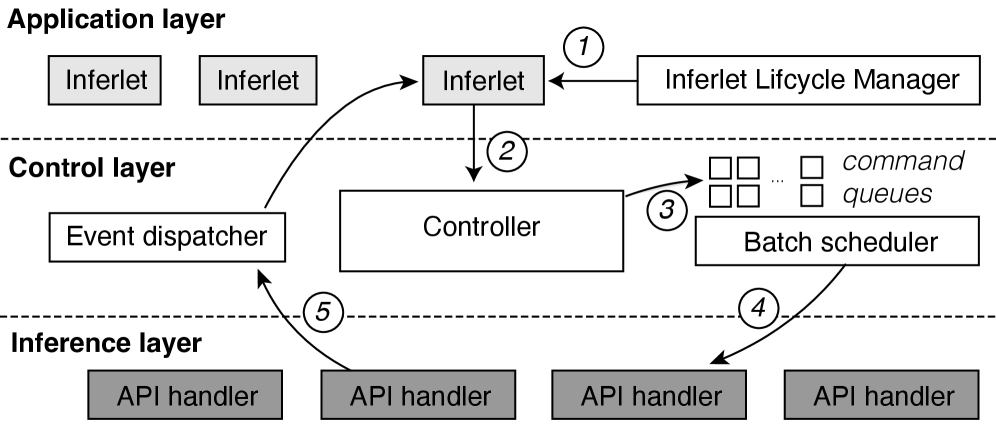
技术框架:Pie的整体架构包括:1) 细粒度的服务处理器,负责执行token生成过程中的各个步骤;2) API,用于暴露服务处理器,允许inferlet调用;3) inferlet执行环境,使用WebAssembly提供轻量级的沙箱环境,保证安全性和隔离性。整个流程是,用户编写inferlet,Pie加载并执行inferlet,inferlet通过API调用服务处理器,完成token生成过程。
关键创新:Pie的关键创新在于其可编程性。与传统的单片LLM服务系统不同,Pie允许用户自定义生成过程,从而实现特定于应用的优化。这种可编程性使得Pie能够支持更广泛的LLM应用,并提高性能。
关键设计:Pie的关键设计包括:1) 细粒度的服务处理器API,需要精心设计,以提供足够的灵活性,同时避免过度复杂性;2) WebAssembly执行环境,需要保证性能和安全性;3) inferlet的调度和资源管理,需要高效地利用系统资源。
🖼️ 关键图片


📊 实验亮点
实验结果表明,Pie在标准任务上与现有最先进的系统相比,只有3-12%的延迟开销。而在代理工作流中,Pie通过启用特定于应用程序的优化,实现了1.3倍-3.4倍的延迟和吞吐量提升。这些结果表明,Pie在提供灵活性的同时,也能够保持甚至提升性能。
🎯 应用场景
Pie可应用于各种需要定制化LLM服务的新兴应用,例如:智能体、对话系统、代码生成、以及需要复杂推理和外部知识集成的任务。通过Pie,开发者可以针对特定应用场景优化LLM的性能和效率,从而提升用户体验,并降低部署成本。Pie的灵活性和可扩展性使其成为构建下一代LLM应用的关键基础设施。
📄 摘要(原文)
Emerging large language model (LLM) applications involve diverse reasoning strategies and agentic workflows, straining the capabilities of existing serving systems built on a monolithic token generation loop. This paper introduces Pie, a programmable LLM serving system designed for flexibility and efficiency. Pie decomposes the traditional generation loop into fine-grained service handlers exposed via an API and delegates control of the generation process to user-provided programs, called inferlets. This enables applications to implement new KV cache strategies, bespoke generation logic, and seamlessly integrate computation and I/O-entirely within the application, without requiring modifications to the serving system. Pie executes inferlets using WebAssembly, benefiting from its lightweight sandboxing. Our evaluation shows Pie matches state-of-the-art performance on standard tasks (3-12% latency overhead) while significantly improving latency and throughput (1.3x-3.4x higher) on agentic workflows by enabling application-specific optimizations.