Success and Cost Elicit Convention Formation for Efficient Communication
作者: Saujas Vaduguru, Yilun Hua, Yoav Artzi, Daniel Fried
分类: cs.CL
发布日期: 2025-10-28
💡 一句话要点
提出基于成功和代价驱动的对话惯例形成方法,提升多模态通信效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 对话惯例形成 多模态通信 指代游戏 自监督学习 人机交互
📋 核心要点
- 现有对话系统缺乏利用共享上下文形成高效通信惯例的能力,导致冗余和低效的交流。
- 通过模拟指代游戏,结合成功和代价信号,训练模型自主学习并形成上下文相关的通信惯例。
- 实验表明,该方法显著缩短了消息长度,提高了通信成功率,并加快了人类听众的反应速度。
📝 摘要(中文)
本文提出了一种训练大型多模态模型以形成对话惯例的方法,从而实现高效通信。该方法利用模型之间的模拟指代游戏,无需额外的人工标注数据。在涉及照片和七巧板图像的重复指代游戏中,该方法使模型能够有效地与人进行通信:在交互过程中,消息长度最多减少 41%,成功率提高 15%。与形成对话惯例的模型交互时,人类听众的反应速度更快。研究还表明,仅基于成功或代价的训练是不够的,两者对于引发对话惯例的形成都是必要的。
🔬 方法详解
问题定义:论文旨在解决多模态对话中,模型如何通过学习形成高效的通信惯例,从而提升交流效率和成功率的问题。现有方法通常依赖大量人工标注数据,或者无法有效利用对话上下文来缩短消息长度和提高理解准确性。这些方法的痛点在于数据依赖性和缺乏自适应性,难以泛化到新的场景。
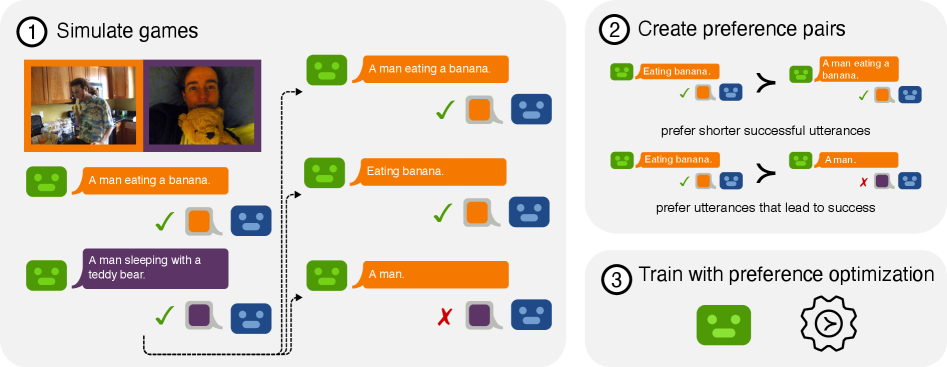
核心思路:论文的核心思路是让模型在模拟的指代游戏中,通过不断交互和学习,自主发现并形成高效的通信惯例。这种方法模仿了人类在对话中逐渐形成共识的过程,允许模型根据上下文调整表达方式,从而减少冗余信息,提高沟通效率。关键在于同时考虑通信的成功率和代价(例如消息长度),引导模型在保证准确性的前提下,尽可能简化表达。
技术框架:整体框架包含两个模型:发送者(Speaker)和接收者(Listener)。发送者观察一个目标对象(例如照片或七巧板图像),并生成消息传递给接收者。接收者根据收到的消息,从一组候选对象中选择目标对象。通过重复进行指代游戏,模型不断调整其通信策略。框架的关键组成部分包括:图像编码器、文本编码器、消息生成器和选择器。损失函数同时考虑了通信的成功率(接收者是否选择了正确的目标对象)和通信的代价(消息的长度)。
关键创新:最重要的技术创新点在于同时利用成功信号和代价信号来训练模型形成对话惯例。以往的研究通常只关注通信的成功率,而忽略了通信的代价。通过引入代价信号,模型能够学习在保证准确性的前提下,尽可能简化表达,从而形成更高效的通信惯例。此外,该方法无需额外的人工标注数据,而是通过模拟指代游戏来实现自监督学习。
关键设计:论文使用了Transformer架构作为消息生成器和文本编码器。图像编码器使用了预训练的ResNet模型。损失函数是成功率和代价的加权和,其中代价是消息长度的负值。通过调整成功率和代价的权重,可以控制模型对效率和准确性的重视程度。实验中,使用了不同的图像数据集(照片和七巧板图像)和不同的候选对象数量,以评估模型的泛化能力。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在指代游戏中显著提高了通信效率和成功率。与基线模型相比,消息长度最多减少了 41%,成功率提高了 15%。此外,与形成对话惯例的模型交互时,人类听众的反应速度更快,表明该方法能够生成更易于理解的消息。研究还验证了同时考虑成功和代价的重要性,表明两者对于引发对话惯例的形成都是必要的。
🎯 应用场景
该研究成果可应用于各种人机交互场景,例如智能客服、虚拟助手和游戏AI。通过让AI系统学习形成高效的对话惯例,可以提升用户体验,减少沟通成本,并提高任务完成效率。未来,该技术有望应用于更复杂的对话场景,例如多轮对话和协作任务。
📄 摘要(原文)
Humans leverage shared conversational context to become increasingly successful and efficient at communicating over time. One manifestation of this is the formation of ad hoc linguistic conventions, which allow people to coordinate on short, less costly utterances that are understood using shared conversational context. We present a method to train large multimodal models to form conventions, enabling efficient communication. Our approach uses simulated reference games between models, and requires no additional human-produced data. In repeated reference games involving photographs and tangram images, our method enables models to communicate efficiently with people: reducing the message length by up to 41% while increasing success by 15% over the course of the interaction. Human listeners respond faster when interacting with our model that forms conventions. We also show that training based on success or cost alone is insufficient - both are necessary to elicit convention formation.