SelecTKD: Selective Token-Weighted Knowledge Distillation for LLMs
作者: Haiduo Huang, Jiangcheng Song, Yadong Zhang, Pengju Ren
分类: cs.CL, cs.AI
发布日期: 2025-10-28 (更新: 2025-11-16)
💡 一句话要点
SelecTKD:面向LLM的选择性Token加权知识蒸馏框架
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 知识蒸馏 大型语言模型 模型压缩 选择性学习 Token加权
📋 核心要点
- 现有知识蒸馏方法对所有token一视同仁,忽略了教师模型的置信度,导致噪声信号放大。
- SelecTKD通过“提出-验证”机制,让学生模型主动学习教师模型认为重要的token,过滤掉噪声。
- 实验表明,SelecTKD在多个任务上显著提升了小型模型的性能,且无需修改模型结构或额外参考模型。
📝 摘要(中文)
知识蒸馏(KD)是将大型语言模型(LLM)压缩为小型学生模型的常用方法,但大多数流程不考虑教师模型的置信度,统一应用token级别的损失。这种不加区分的监督会放大噪声和高熵信号,在大师生能力差距悬殊的情况下尤其有害。我们提出了SelecTKD,一个即插即用的选择性Token加权蒸馏框架,它将重点从“如何衡量差异”转移到“在哪里应用学习”。在每一步,学生模型提出token,然后教师模型通过一个鲁棒的“提出-验证”程序进行验证,该程序有两个变体:贪婪的Top-k和非贪婪的Spec-k。被接受的token接收全部损失,而被拒绝的token被屏蔽或降低权重。这种与目标无关的设计适用于on-policy和off-policy数据,诱导了一个由Token接受率(TAR)量化的隐式课程,并稳定了优化过程。在指令跟随、数学推理、代码生成和VLM设置中,SelecTKD始终改进了强大的基线,并在不改变架构或使用额外参考模型的情况下,为小型模型实现了最先进的结果。
🔬 方法详解
问题定义:现有知识蒸馏方法在压缩大型语言模型时,通常对所有token采用统一的损失函数,而忽略了教师模型对不同token的置信度差异。这种做法会放大教师模型中的噪声信号,尤其是在教师模型和学生模型能力差距较大时,会严重影响学生模型的学习效果。现有方法缺乏有效区分重要token和噪声token的机制。
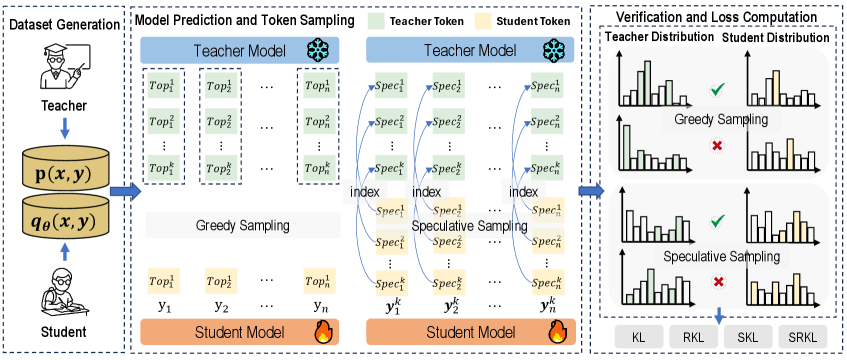
核心思路:SelecTKD的核心思路是引入一个“选择性”的token加权机制,让学生模型更加关注教师模型认为重要的token。具体来说,学生模型首先“提出”一系列token,然后由教师模型进行“验证”,只有被教师模型认可的token才会参与损失计算,而其他token则会被屏蔽或降低权重。这种“提出-验证”的过程模拟了一种课程学习,让学生模型逐步掌握重要的知识。
技术框架:SelecTKD的整体框架可以分为两个主要阶段:token提出阶段和token验证阶段。在token提出阶段,学生模型生成一系列候选token。在token验证阶段,教师模型对这些候选token进行评估,判断其重要性。论文提出了两种验证方法:贪婪的Top-k方法和非贪婪的Spec-k方法。Top-k方法选择教师模型认为最有可能的k个token,而Spec-k方法则基于一定的概率分布进行采样。最终,只有被选中的token才会参与损失计算。
关键创新:SelecTKD最重要的创新在于其“选择性”的token加权机制。与传统的知识蒸馏方法不同,SelecTKD不是简单地将教师模型的输出作为目标,而是让学生模型主动学习教师模型认为重要的知识。这种方法可以有效地过滤掉教师模型中的噪声信号,提高学生模型的学习效率。此外,SelecTKD的设计与具体的损失函数无关,可以灵活地应用于不同的任务和模型。
关键设计:SelecTKD的关键设计包括:1) 两种token验证方法(Top-k和Spec-k),它们分别代表了不同的选择策略;2) Token接受率(TAR),用于量化学生模型学习的进度;3) 损失函数的加权方式,被接受的token赋予更高的权重,而被拒绝的token则被屏蔽或降低权重。具体参数设置需要根据不同的任务和模型进行调整。
🖼️ 关键图片

📊 实验亮点
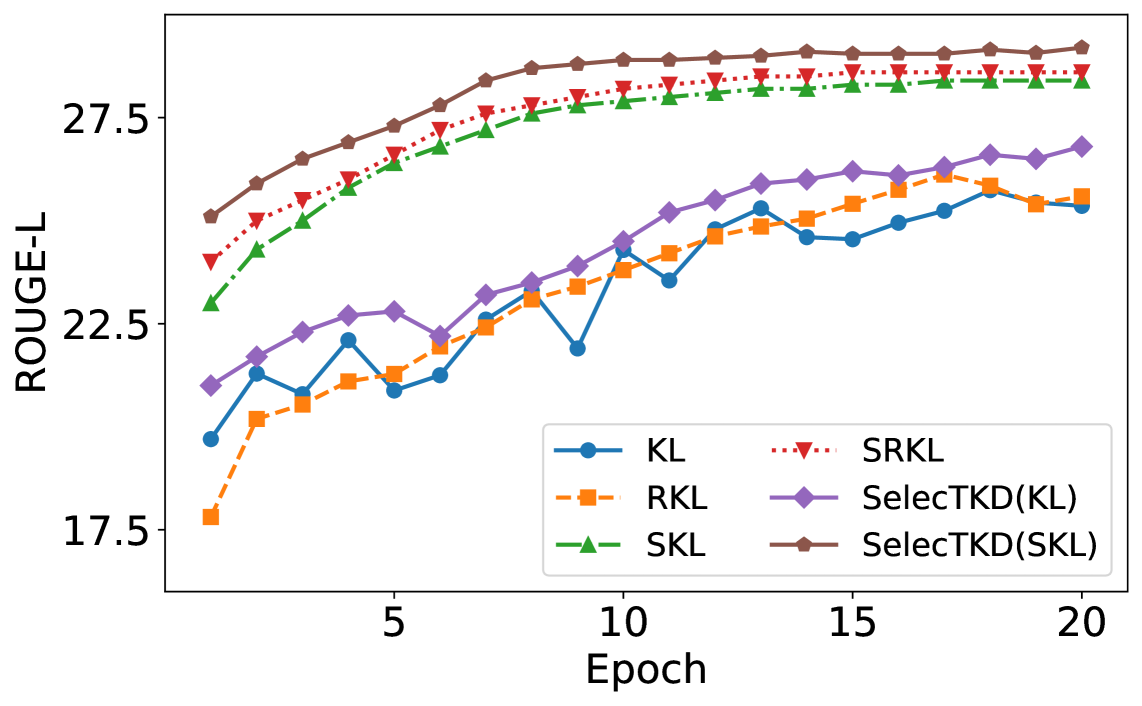
SelecTKD在指令跟随、数学推理、代码生成和VLM等多个任务上取得了显著的性能提升。例如,在指令跟随任务中,SelecTKD能够使小型模型达到甚至超过大型模型的性能。在数学推理和代码生成任务中,SelecTKD也显著优于现有的知识蒸馏方法。实验结果表明,SelecTKD是一种有效的模型压缩和加速方法,能够提升小型模型的性能。
🎯 应用场景
SelecTKD具有广泛的应用前景,可用于压缩和加速大型语言模型,使其能够在资源受限的设备上运行。该方法可以应用于各种自然语言处理任务,如文本生成、机器翻译、问答系统等。此外,SelecTKD还可以用于训练更高效的视觉语言模型,提升其在图像理解和生成方面的性能。未来,该方法有望推动人工智能技术在移动设备、嵌入式系统等领域的应用。
📄 摘要(原文)
Knowledge distillation (KD) is a standard route to compress Large Language Models (LLMs) into compact students, yet most pipelines uniformly apply token-wise loss regardless of teacher confidence. This indiscriminate supervision amplifies noisy, high-entropy signals and is especially harmful under large teacher-student capacity gaps. We introduce SelecTKD, a plug-and-play Selective Token-Weighted distillation framework that shifts the focus from "how to measure divergence" to "where to apply learning". At each step, the student proposes tokens that are verified by the teacher through a robust propose-and-verify procedure with two variants: greedy Top-k and non-greedy Spec-k. Accepted tokens receive full loss, while rejected tokens are masked or down-weighted. This objective-agnostic design works with on- and off-policy data, induces an implicit curriculum quantified by Token Acceptance Rate (TAR), and stabilizes optimization. Across instruction following, mathematical reasoning, code generation, and a VLM setting, SelecTKD consistently improves strong baselines and achieves state-of-the-art results for small models without architectural changes or extra reference models.