TimeStampEval: A Simple LLM Eval and a Little Fuzzy Matching Trick to Improve Search Accuracy
作者: James McCammon
分类: cs.CL, cs.AI
发布日期: 2025-10-27
💡 一句话要点
提出TimeStampEval基准与Assisted Fuzzy方法,提升LLM在含噪声文本中时间戳检索的准确性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 时间戳检索 模糊匹配 大型语言模型 文本对齐 信息检索
📋 核心要点
- 现有模糊匹配算法在处理语义相同但语法不同的文本时效果不佳,尤其是在对齐语音转录和书面记录时。
- 提出Assisted Fuzzy方法,利用RapidFuzz进行预过滤,然后使用LLM对候选片段进行验证,提高检索精度并降低计算成本。
- 实验表明,该方法在长文本记录上实现了高准确率,并且对文本长度、领域变化和词汇漂移具有鲁棒性。
📝 摘要(中文)
本文介绍了一个名为TimeStampEval的基准,用于评估大型语言模型(LLM)从长文本记录中检索精确到毫秒级时间戳的能力,尤其是在面对非完全一致的引用时。传统模糊匹配在处理语义相同但语法不同的文本时表现不佳,这在对齐官方记录和语音转录文本时很常见。本文提出的两阶段方法显著提高了检索准确率,同时降低了超过90%的推理成本。该方法的核心是利用RapidFuzz预过滤,然后使用LLM验证短文本片段,称为“Assisted Fuzzy”。在包含2800个句子(12万token)的文本记录上的评估表明,提示设计比模型选择更重要,并且适度的推理预算可以显著提高准确率。在十个不同长度和领域的文本记录上的扩展测试证实了该方法的鲁棒性。
🔬 方法详解
问题定义:论文旨在解决从长文本记录中检索与给定引用相对应的时间戳的问题,尤其是在引用与原始文本存在转录或编辑差异的情况下。现有模糊匹配算法在处理这种非完全一致的文本时,准确率较低,无法满足实际应用需求。
核心思路:核心思路是结合快速的模糊匹配算法和LLM的语义理解能力。首先使用RapidFuzz等算法快速筛选出候选文本片段,然后利用LLM对这些候选片段进行精细的语义匹配和时间戳定位。这种两阶段方法既保证了检索速度,又提高了检索精度。
技术框架:该方法主要包含两个阶段:1) 预过滤阶段:使用RapidFuzz等模糊匹配算法,在整个文本记录中快速搜索与目标引用相似的文本片段,并提取其对应的时间戳。2) 验证阶段:将预过滤阶段得到的候选文本片段和目标引用输入LLM,利用LLM的语义理解能力判断候选片段是否与目标引用语义一致,并输出精确的时间戳。
关键创新:关键创新在于“Assisted Fuzzy”的思想,即利用快速模糊匹配算法进行初步筛选,然后利用LLM进行精细验证。这种方法充分利用了两种技术的优势,避免了LLM直接处理长文本带来的计算成本问题,同时提高了模糊匹配的准确率。
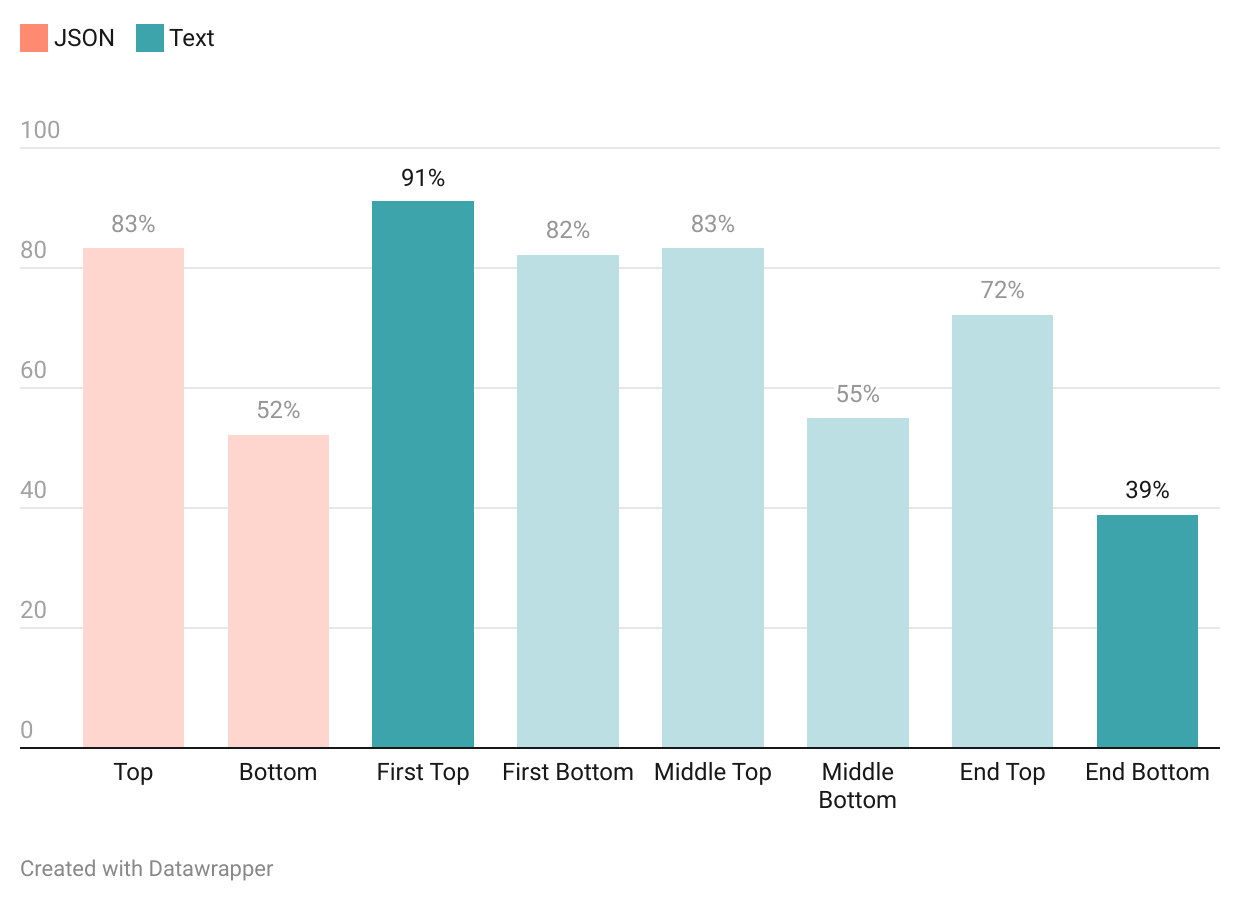
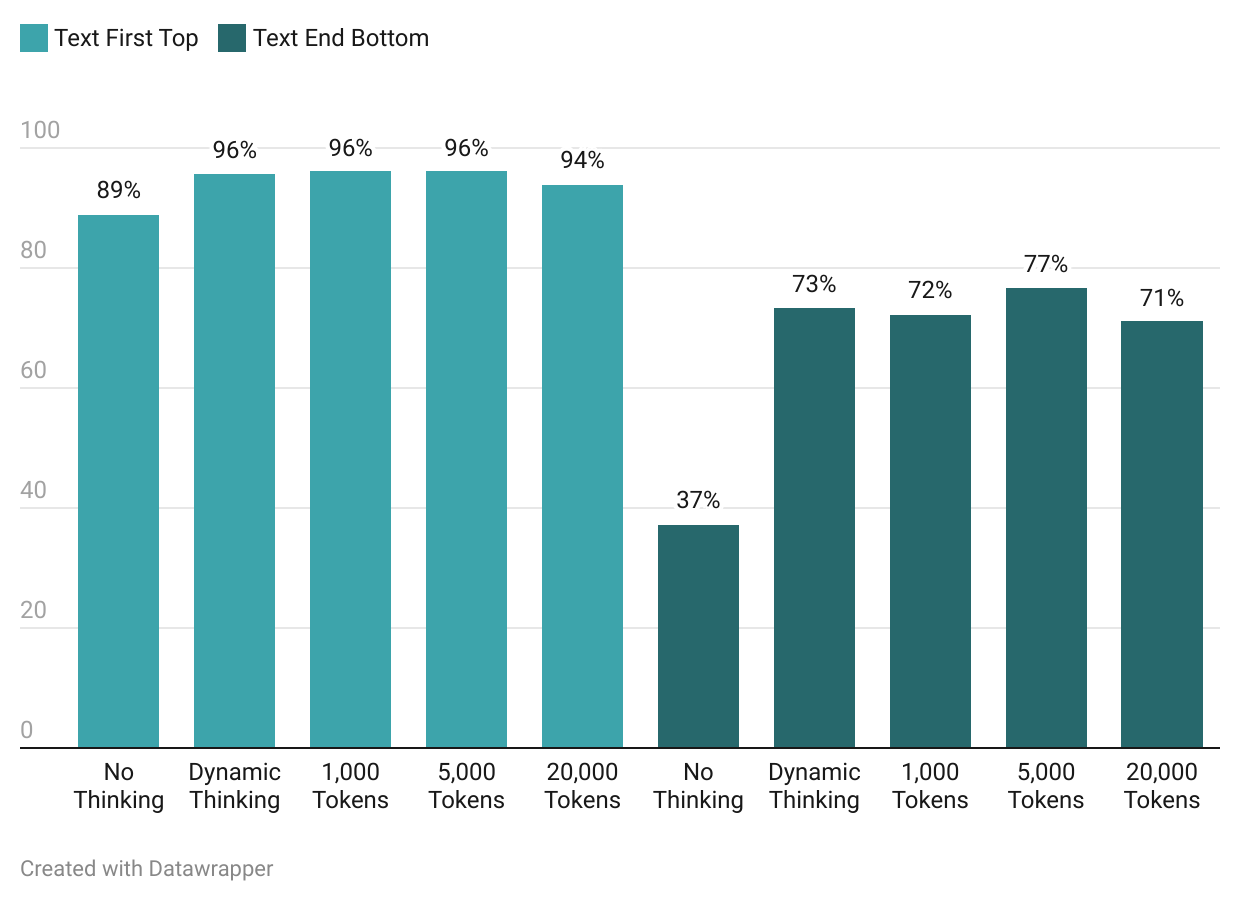
关键设计:在提示设计方面,论文发现将查询放在文本记录之前,并使用紧凑的格式可以提高准确率并减少token数量。此外,论文还发现,为LLM提供适度的推理预算(600-850 tokens)可以显著提高准确率。RapidFuzz的参数设置也需要根据具体应用场景进行调整,以平衡检索速度和召回率。
🖼️ 关键图片
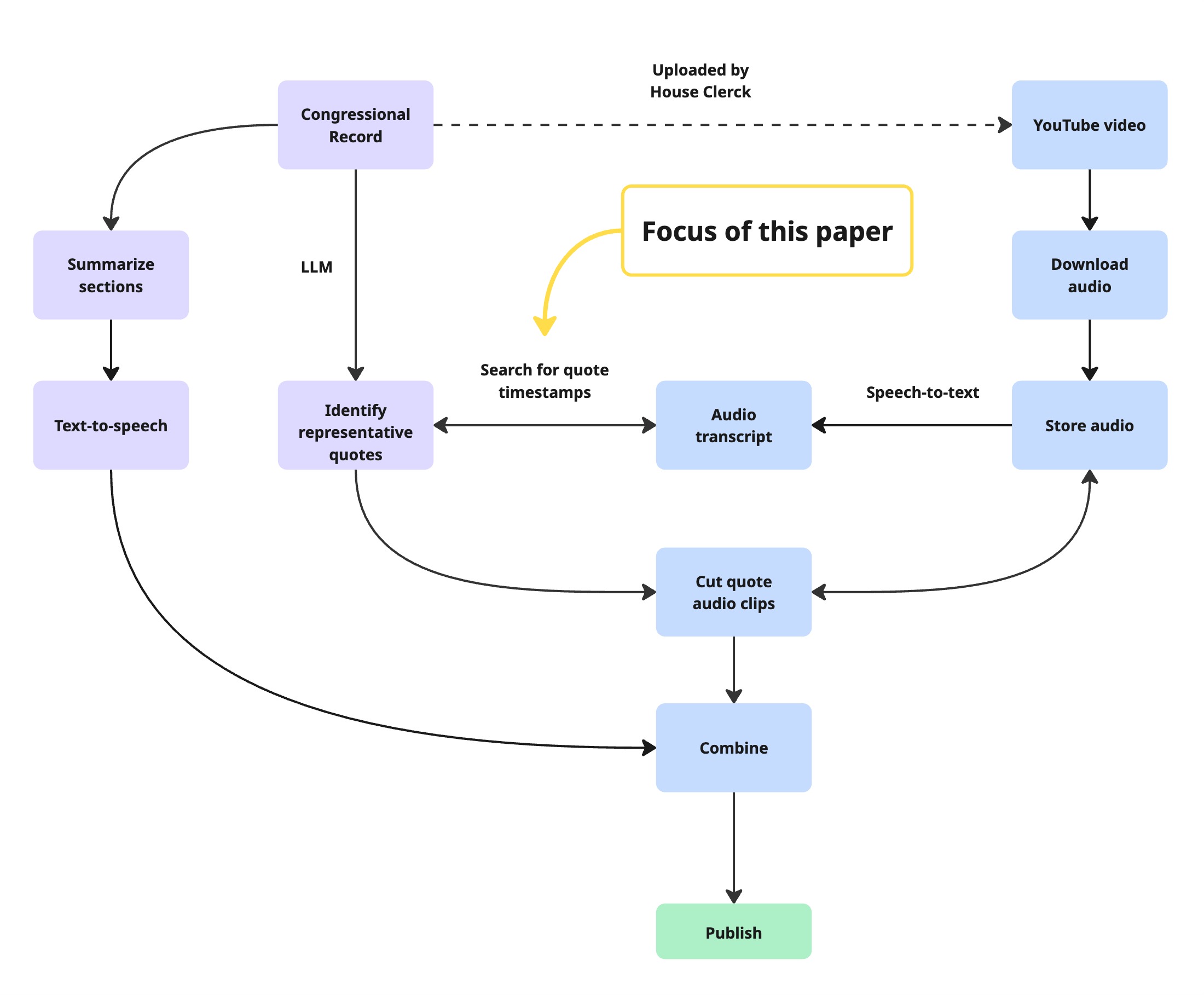
📊 实验亮点
实验结果表明,Assisted Fuzzy方法可以将模糊匹配的准确率提高高达50个百分点,同时将延迟降低一半,并将每次正确结果的成本降低高达96%。在包含1989-2025年间文本记录的扩展测试中,该方法对文本长度、词汇漂移和领域变化表现出鲁棒性,对不存在的目标保持95-100%的拒绝准确率。
🎯 应用场景
该研究成果可应用于自动生成长篇播客、视频字幕对齐、法律文件检索等领域。通过自动检索和对齐语音转录和书面记录,可以提高信息检索效率,降低人工成本,并为用户提供更准确的信息。
📄 摘要(原文)
Traditional fuzzy matching often fails when searching for quotes that are semantically identical but syntactically different across documents-a common issue when aligning official written records with speech-to-text transcripts. We introduce TimeStampEval, a benchmark for retrieving precise millisecond timestamps from long transcripts given non-verbatim quotes. Our simple two-stage method dramatically improves retrieval accuracy while cutting inference costs by over 90%. The motivating use case is an automated long-form podcast that assembles Congressional Record clips into AI-hosted narration. The technical challenge: given a sentence-timestamped transcript and a target quote that may differ due to transcription or editorial drift, return exact start and end boundaries. Standard algorithms handle verbatim text but break under fuzzier variants. Evaluating six modern LLMs on a 2,800-sentence (120k-token) transcript revealed four key findings. (1) Prompt design matters more than model choice: placing the query before the transcript and using compact formatting improved accuracy by 3-20 points while reducing token count by 30-40%. (2) Off-by-one errors form a distinct category, showing models understand the task but misplace boundaries. (3) A modest reasoning budget (600-850 tokens) raises accuracy from 37% to 77% for weak setups and to above 90% for strong ones. (4) Our "Assisted Fuzzy" approach-RapidFuzz pre-filtering followed by LLM verification on short snippets-improves fuzzy match accuracy by up to 50 points while halving latency and reducing cost per correct result by up to 96%. Extended tests on ten transcripts (50k-900k tokens, 1989-2025) confirm robustness to transcript length, vocabulary drift, and domain change, maintaining 95-100% rejection accuracy for absent targets.