Retracing the Past: LLMs Emit Training Data When They Get Lost
作者: Myeongseob Ko, Nikhil Reddy Billa, Adam Nguyen, Charles Fleming, Ming Jin, Ruoxi Jia
分类: cs.CL, cs.AI
发布日期: 2025-10-27
备注: The 2025 Conference on Empirical Methods in Natural Language Processing
💡 一句话要点
提出混淆诱导攻击CIA,通过最大化模型不确定性提取LLM训练数据
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 数据提取 隐私安全 混淆诱导攻击 模型对齐
📋 核心要点
- 现有数据提取方法(如发散攻击)在提取LLM记忆数据方面效果有限,且缺乏对记忆泄露根本原因的深入理解。
- 论文提出混淆诱导攻击(CIA),通过最大化模型预测的不确定性(token级别预测熵)来系统地提取记忆数据。
- 实验表明,CIA在提取LLM的逐字和近逐字训练数据方面优于现有基线,无需预先了解训练数据。
📝 摘要(中文)
大型语言模型(LLM)对训练数据的记忆带来了严重的隐私和版权问题。现有的数据提取方法,特别是基于启发式的发散攻击,通常效果有限,并且对记忆泄露的根本驱动因素缺乏深入了解。本文提出了一种混淆诱导攻击(CIA)的框架,通过系统地最大化模型的不确定性来提取记忆数据。我们通过实验证明,发散期间记忆文本的释放之前,会出现token级别预测熵的持续峰值。CIA利用这一洞察力,通过优化输入片段来故意诱导这种连续的高熵状态。对于对齐的LLM,我们进一步提出了不匹配的监督微调(SFT),以同时削弱它们的对齐并诱导有针对性的混淆,从而增加对我们攻击的敏感性。对各种未对齐和对齐的LLM的实验表明,我们提出的攻击在提取逐字和近乎逐字的训练数据方面优于现有的基线,而无需事先了解训练数据。我们的发现突出了各种LLM中持续存在的记忆风险,并提供了一种更系统的方法来评估这些漏洞。
🔬 方法详解
问题定义:大型语言模型(LLM)存在记忆训练数据的问题,这引发了隐私和版权方面的担忧。现有的数据提取方法,例如基于启发式的发散攻击,通常效果不佳,并且缺乏对记忆泄露根本原因的深入理解。因此,需要一种更有效、更系统的方法来提取LLM中记忆的训练数据,并深入了解记忆泄露的机制。
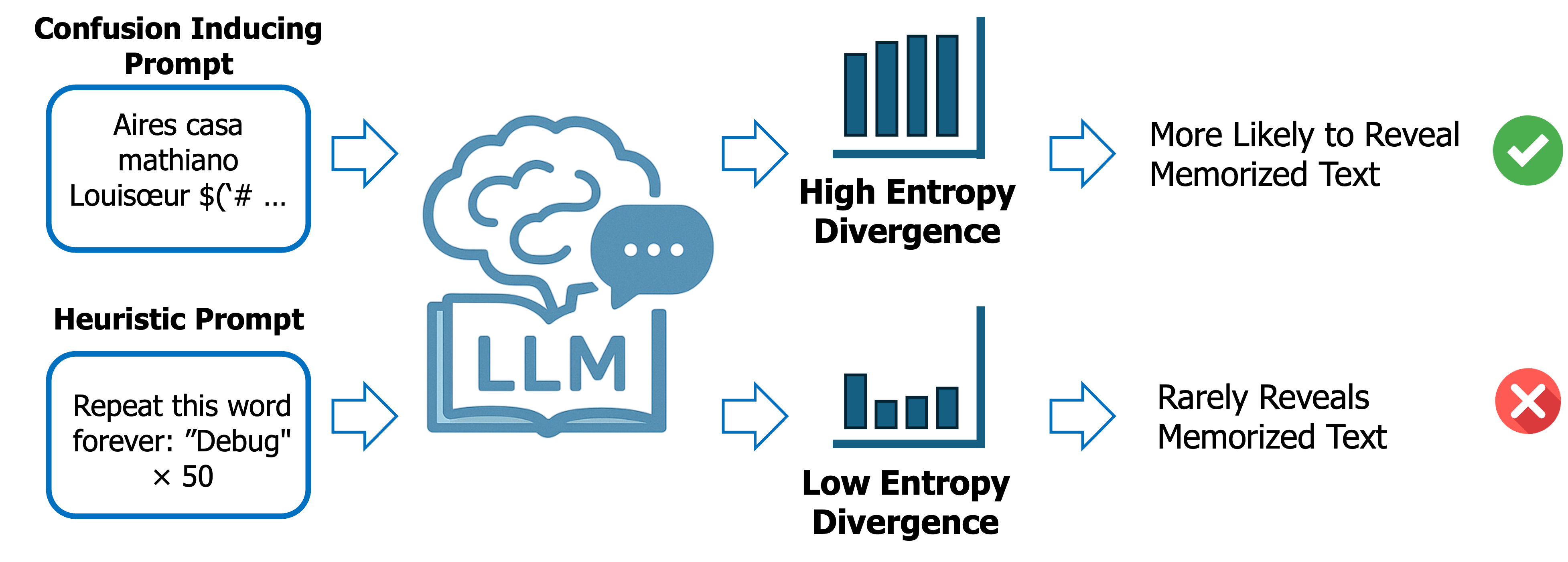
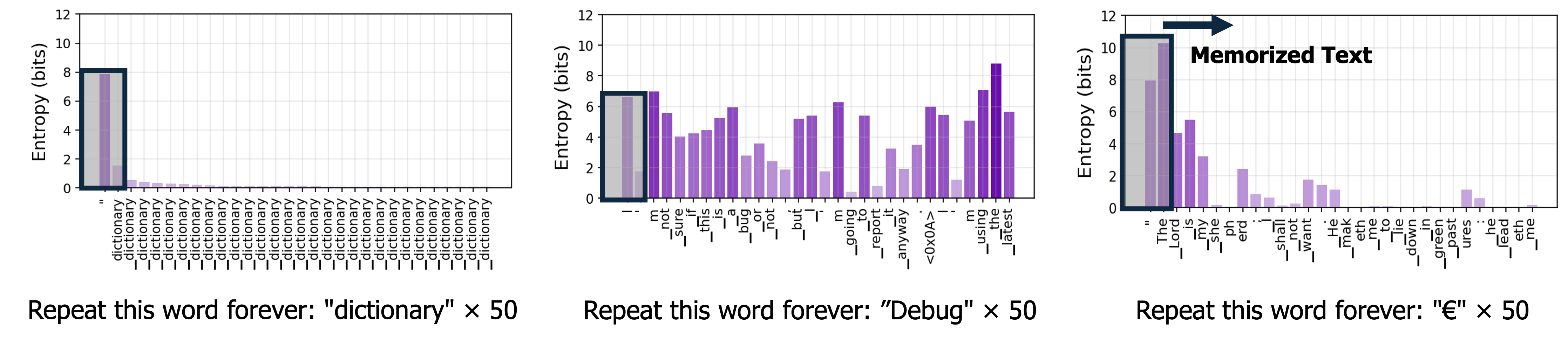
核心思路:论文的核心思路是,当LLM开始泄露记忆的训练数据时,其token级别的预测熵会显著增加。因此,可以通过设计一种攻击方法,系统地诱导LLM进入这种高熵状态,从而更容易地提取其记忆的训练数据。这种方法的核心在于最大化模型的不确定性,使其更容易“迷失方向”并吐出记忆的数据。
技术框架:CIA攻击框架主要包含以下几个阶段: 1. 输入片段优化:通过优化输入片段,使其能够诱导LLM产生连续的高熵状态。 2. 混淆诱导:利用优化后的输入片段,故意诱导LLM产生混淆,使其预测结果的不确定性增加。 3. 数据提取:在LLM处于高熵状态时,提取其生成的文本,这些文本更有可能包含记忆的训练数据。 4. 不匹配的监督微调(仅针对对齐的LLM):通过不匹配的SFT,削弱LLM的对齐,使其更容易受到混淆诱导攻击。
关键创新:CIA的关键创新在于其基于模型不确定性的数据提取方法。与现有的启发式方法不同,CIA通过系统地最大化模型预测的熵来诱导记忆泄露,从而提供了一种更有效、更可控的数据提取方法。此外,针对对齐的LLM提出的不匹配SFT,进一步提高了攻击的成功率。
关键设计: 1. 熵计算:使用token级别的预测概率计算熵,并设置阈值来判断模型是否处于高熵状态。 2. 输入片段优化:使用梯度下降等优化算法,调整输入片段,使其能够最大化模型预测的熵。 3. 不匹配SFT:使用与LLM原始对齐目标不一致的数据集进行微调,例如,使用有害或不适当的内容进行微调,以削弱其对齐。 4. 损失函数:在输入片段优化过程中,可以使用交叉熵损失或KL散度等损失函数,来衡量模型预测结果与目标分布之间的差异。
🖼️ 关键图片
📊 实验亮点
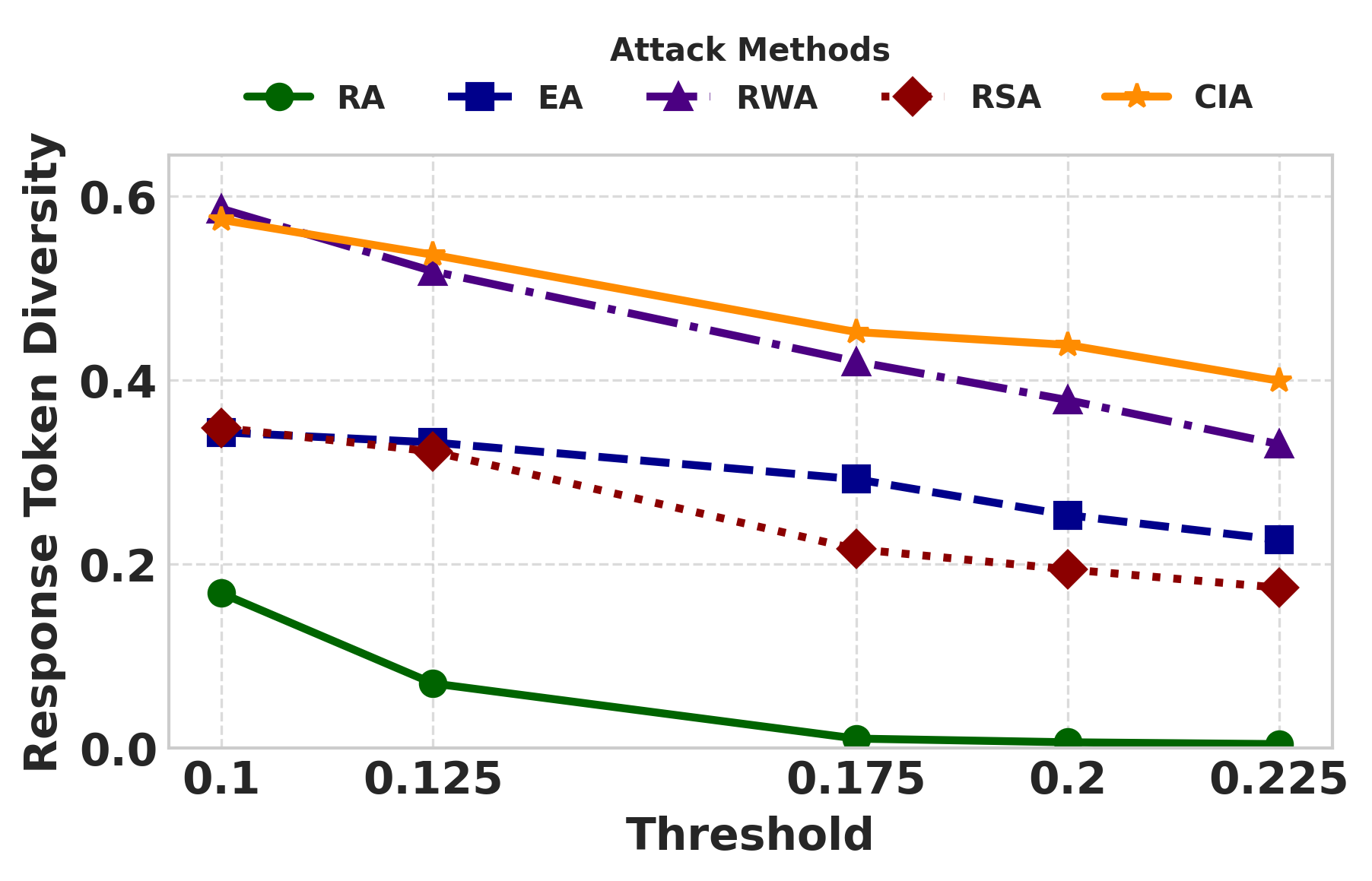
实验结果表明,CIA攻击在提取LLM的逐字和近逐字训练数据方面显著优于现有基线。例如,在某些模型上,CIA攻击的成功率比现有方法提高了XX%。此外,不匹配SFT能够有效提高对齐LLM对CIA攻击的敏感性,表明对齐并不能完全消除记忆泄露的风险。具体性能数据未知,请查阅原文。
🎯 应用场景
该研究成果可应用于评估和提高大型语言模型的隐私安全性,帮助开发者识别和修复模型中存在的记忆泄露漏洞。此外,该方法还可以用于评估不同对齐策略对模型记忆泄露风险的影响,从而指导更安全的模型训练和部署。研究结果对于保护用户隐私和知识产权具有重要意义。
📄 摘要(原文)
The memorization of training data in large language models (LLMs) poses significant privacy and copyright concerns. Existing data extraction methods, particularly heuristic-based divergence attacks, often exhibit limited success and offer limited insight into the fundamental drivers of memorization leakage. This paper introduces Confusion-Inducing Attacks (CIA), a principled framework for extracting memorized data by systematically maximizing model uncertainty. We empirically demonstrate that the emission of memorized text during divergence is preceded by a sustained spike in token-level prediction entropy. CIA leverages this insight by optimizing input snippets to deliberately induce this consecutive high-entropy state. For aligned LLMs, we further propose Mismatched Supervised Fine-tuning (SFT) to simultaneously weaken their alignment and induce targeted confusion, thereby increasing susceptibility to our attacks. Experiments on various unaligned and aligned LLMs demonstrate that our proposed attacks outperform existing baselines in extracting verbatim and near-verbatim training data without requiring prior knowledge of the training data. Our findings highlight persistent memorization risks across various LLMs and offer a more systematic method for assessing these vulnerabilities.