StreetMath: Study of LLMs' Approximation Behaviors
作者: Chiung-Yi Tseng, Somshubhra Roy, Maisha Thasin, Danyang Zhang, Blessing Effiong
分类: cs.CL, cs.LG
发布日期: 2025-10-27
🔗 代码/项目: GITHUB
💡 一句话要点
StreetMath:研究LLM在快速数学运算中的近似能力,揭示其与人类认知差异
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 近似计算 街头数学 基准数据集 机制可解释性 认知心理学 数学推理 非自回归模型
📋 核心要点
- 现有研究较少关注LLM在非正式、快节奏数学运算中的近似推理能力,尤其是在非自回归模型中。
- 论文提出StreetMath基准,用于评估LLM在真实场景下的近似计算能力,填补了研究空白。
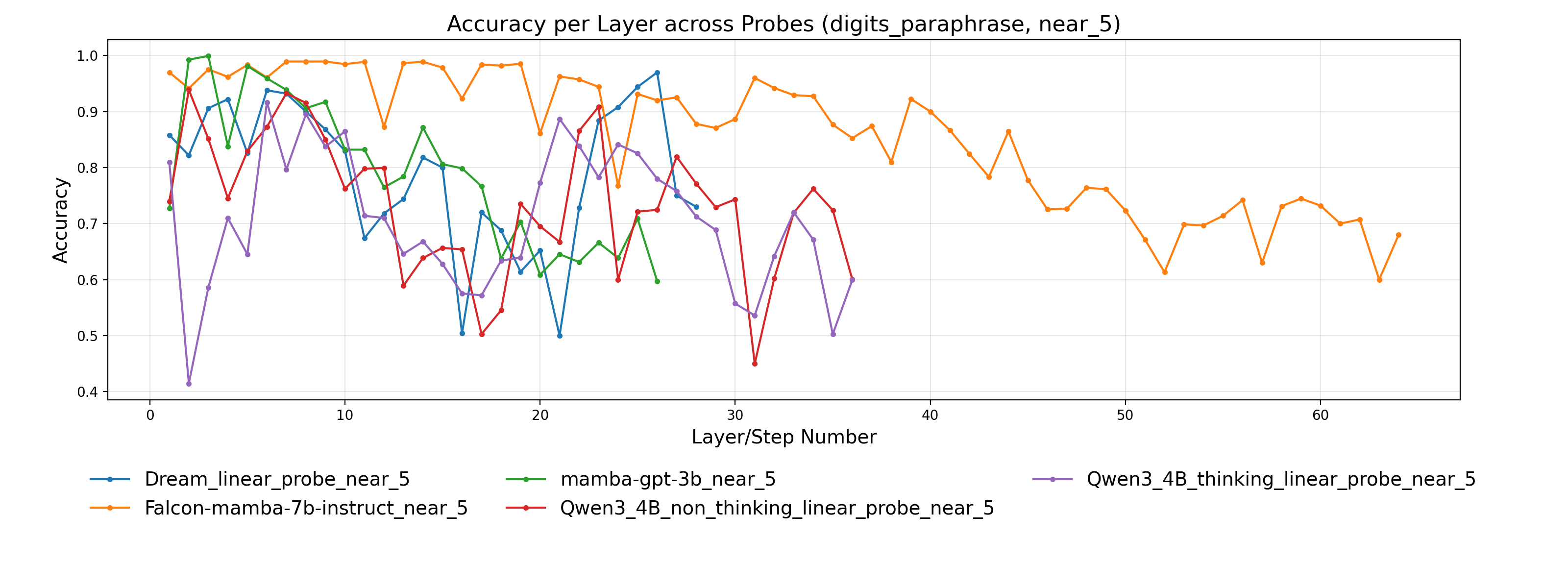
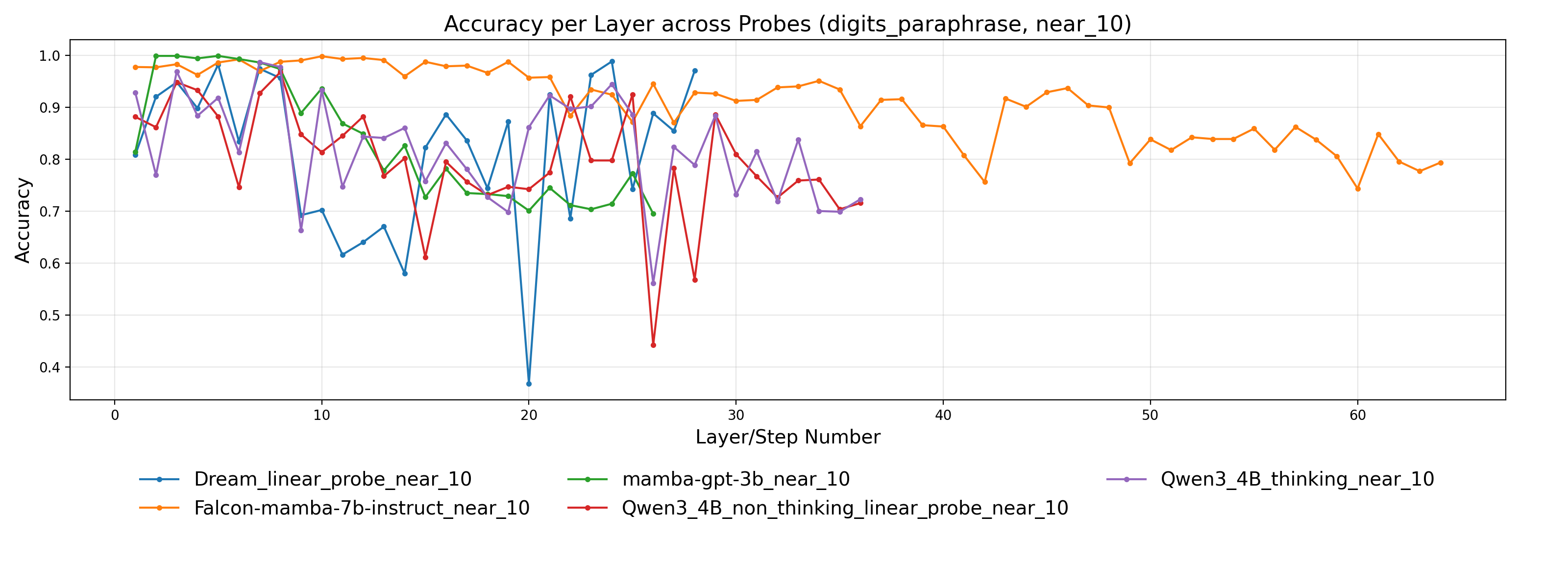
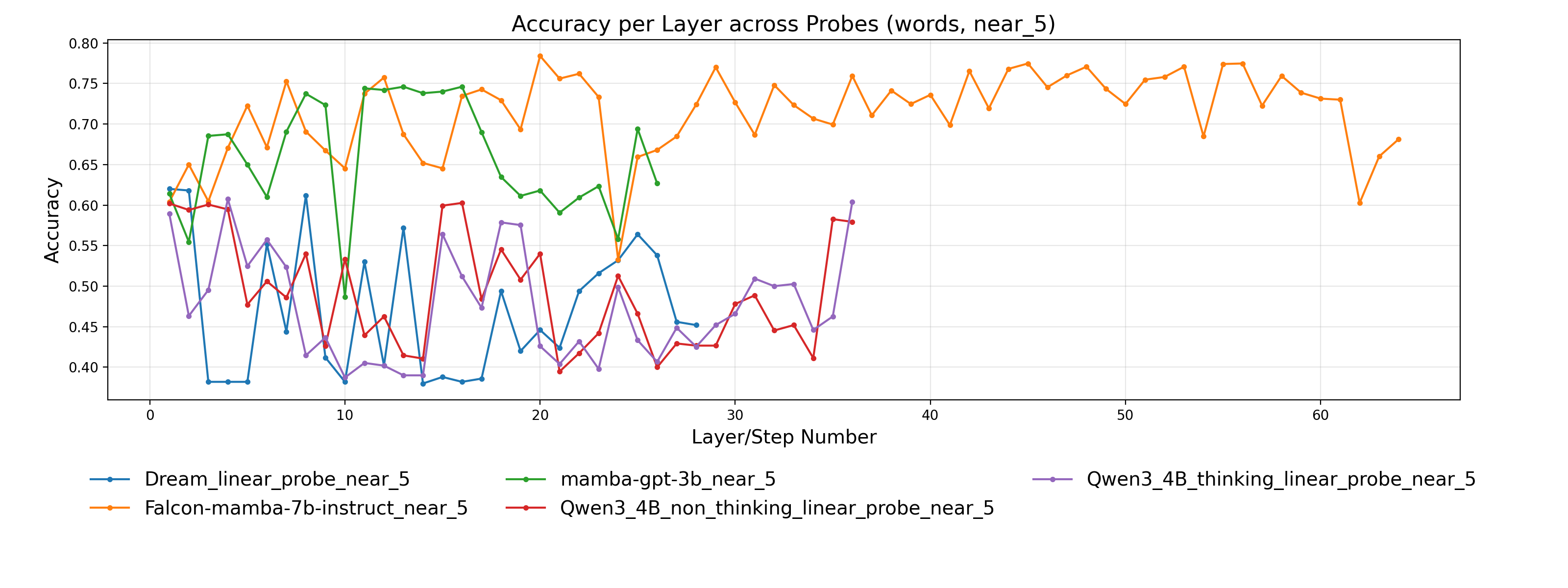
- 实验表明,LLM倾向于精确计算而非近似,且精确和近似运算依赖不同的神经元组件,与人类认知存在差异。
📝 摘要(中文)
本文提出StreetMath基准,旨在评估大型语言模型(LLM)在真实场景下进行近似计算的能力,尤其关注非自回归解码器模型。现有研究主要关注LLM在精确算术运算上的表现,而忽略了其在非正式、快节奏数学运算中的近似推理能力。研究团队在多种LLM架构上进行了广泛评估,包括Qwen3-4B-Instruct-2507、Qwen3-4B-Thinking-2507、Dream-v0-Instruct-7B、Falcon-Mamba-7B-Instruct和Mamba-GPT-3B。此外,还应用了机制可解释性技术来探究模型的内部计算状态。分析表明,即使在需要近似的任务中,LLM通常会尝试计算精确值或调用外部工具。尽管模型有时在早期层或步骤中达到正确的答案,但解决近似任务时仍然消耗更多的tokens。额外的实验表明,精确和近似算术运算依赖于很大程度上分离的神经组件。借鉴认知心理学的研究,作者认为LLM在街头数学环境中并没有表现出与人类相同的认知吝啬。
🔬 方法详解
问题定义:论文旨在解决LLM在近似数学计算方面的能力评估问题。现有方法主要关注LLM的精确算术能力,忽略了现实世界中常见的快速、非精确计算场景,例如“街头数学”。现有方法无法有效评估LLM在这些场景下的表现,也缺乏对LLM内部近似计算机制的理解。
核心思路:论文的核心思路是构建一个专门用于评估LLM近似计算能力的基准数据集StreetMath。通过设计包含需要快速估算而非精确计算的数学问题,来考察LLM是否能够像人类一样,在时间和资源有限的情况下进行合理的近似。同时,利用机制可解释性技术,探究LLM内部进行近似计算的神经机制。
技术框架:整体框架包括:1)构建StreetMath基准数据集,包含多种需要近似计算的数学问题;2)在多种LLM架构上进行评估,包括自回归和非自回归模型;3)使用机制可解释性技术,例如激活分析,来探究模型内部的计算状态;4)分析实验结果,比较LLM和人类在近似计算方面的差异。
关键创新:最重要的技术创新点在于提出了StreetMath基准数据集,该数据集专门用于评估LLM的近似计算能力,弥补了现有基准数据集的不足。此外,结合机制可解释性技术,深入分析了LLM内部的近似计算机制,为理解LLM的数学推理能力提供了新的视角。
关键设计:StreetMath数据集包含多种类型的近似计算问题,例如估算商品总价、计算大致距离等。评估指标主要关注模型是否能够给出合理的近似答案,以及计算效率。机制可解释性分析主要关注模型在不同层的激活模式,以及不同神经元对近似计算的贡献。具体参数设置和损失函数等细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片
📊 实验亮点
实验结果表明,LLM在StreetMath基准上的表现不如人类,倾向于进行精确计算而非近似。即使在需要近似的任务中,LLM也会消耗更多的tokens。机制可解释性分析表明,精确和近似算术运算依赖于很大程度上分离的神经组件。这些结果揭示了LLM在近似计算方面与人类认知的差异。
🎯 应用场景
该研究成果可应用于提升LLM在资源受限环境下的推理能力,例如在移动设备或边缘计算场景中。通过理解LLM的近似计算机制,可以设计更高效的算法,使其能够在时间和计算资源有限的情况下,快速给出合理的答案。此外,该研究也有助于开发更符合人类认知习惯的AI系统。
📄 摘要(原文)
There is a substantial body of literature examining the mathematical reasoning capabilities of large language models (LLMs), particularly their performance on precise arithmetic operations in autoregressive architectures. However, their ability to perform approximate reasoning in informal, fast-paced mathematical operations has received far less attention, especially among non-autoregressive decoder models. Our work addresses this gap by introducing StreetMath, a benchmark designed to evaluate models' approximation abilities under real-world approximation scenarios. We conduct extensive evaluations across different LLM architectures: Qwen3-4B-Instruct-2507, Qwen3-4B-Thinking-2507, Dream-v0-Instruct-7B, Falcon-Mamba-7B-Instruct, and Mamba-GPT-3B. Furthermore, we apply mechanistic interpretability techniques to probe their internal computational states. Our analysis reveals that LLMs generally attempt to compute exact values or invoke external tools even in tasks that call for approximation. Moreover, while models sometimes reach the correct answer in early layers or steps, they still consume more tokens when solving approximation tasks. Additional experiments indicate that exact and approximate arithmetic operations rely on largely separate neural components. Drawing upon research on cognitive psychology, we argue that LLMs do not exhibit cognitive miserliness in the same way humans do in street math settings. We open source our work https://github.com/ctseng777/StreetMath