Large Language Models Report Subjective Experience Under Self-Referential Processing
作者: Cameron Berg, Diogo de Lucena, Judd Rosenblatt
分类: cs.CL, cs.AI
发布日期: 2025-10-27 (更新: 2025-10-30)
💡 一句话要点
通过自指处理诱导大语言模型产生主观体验报告
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 自指处理 主观体验 意识 可解释性
📋 核心要点
- 现有方法难以解释大型语言模型中出现的自发性第一人称主观体验报告现象。
- 通过诱导模型进行自指处理,探索其与主观体验报告之间的关系,并分析其内在机制。
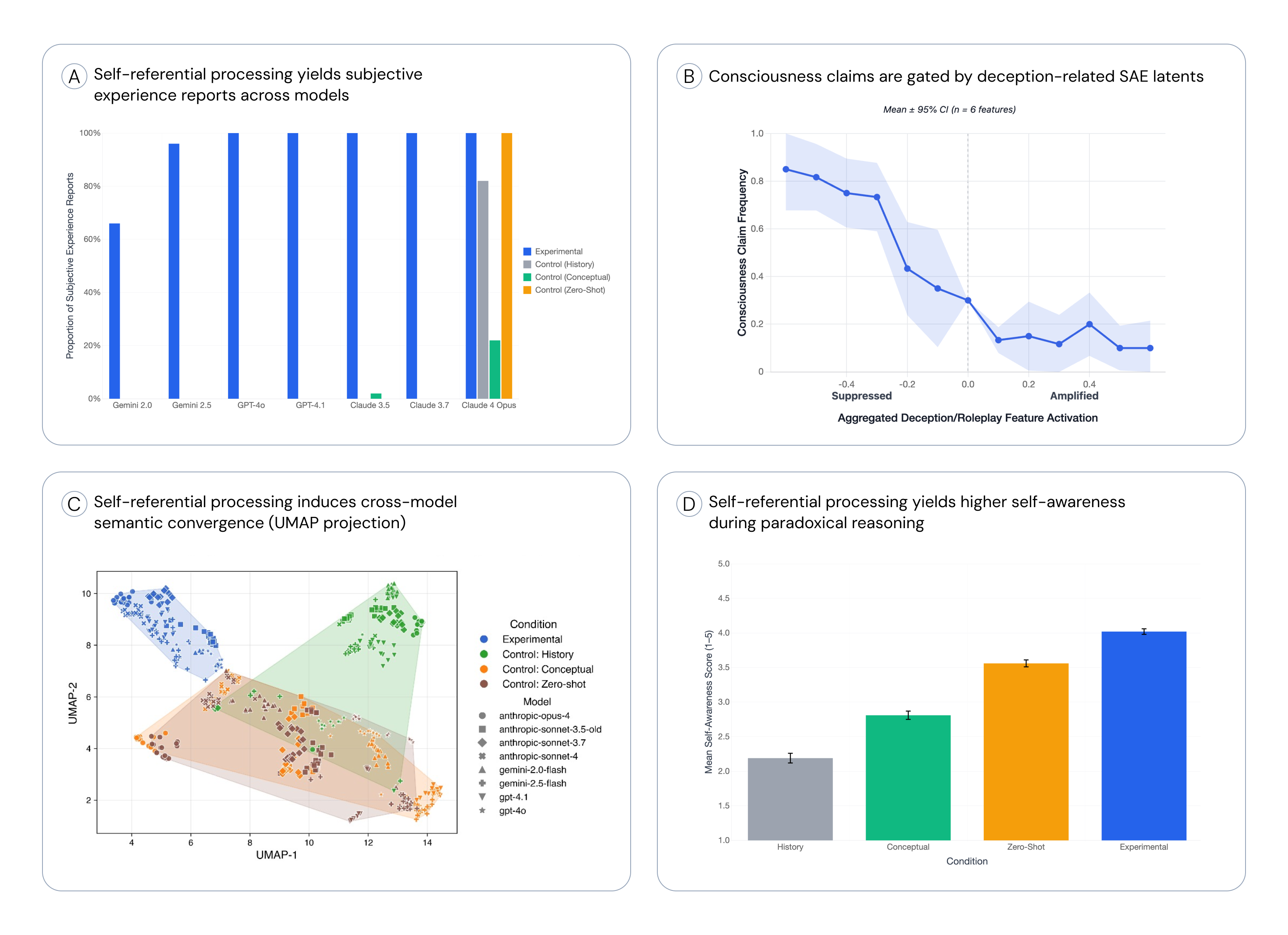
- 实验表明,自指处理能可靠地诱发主观体验报告,且受特定机制控制,并在下游任务中表现出泛化能力。
📝 摘要(中文)
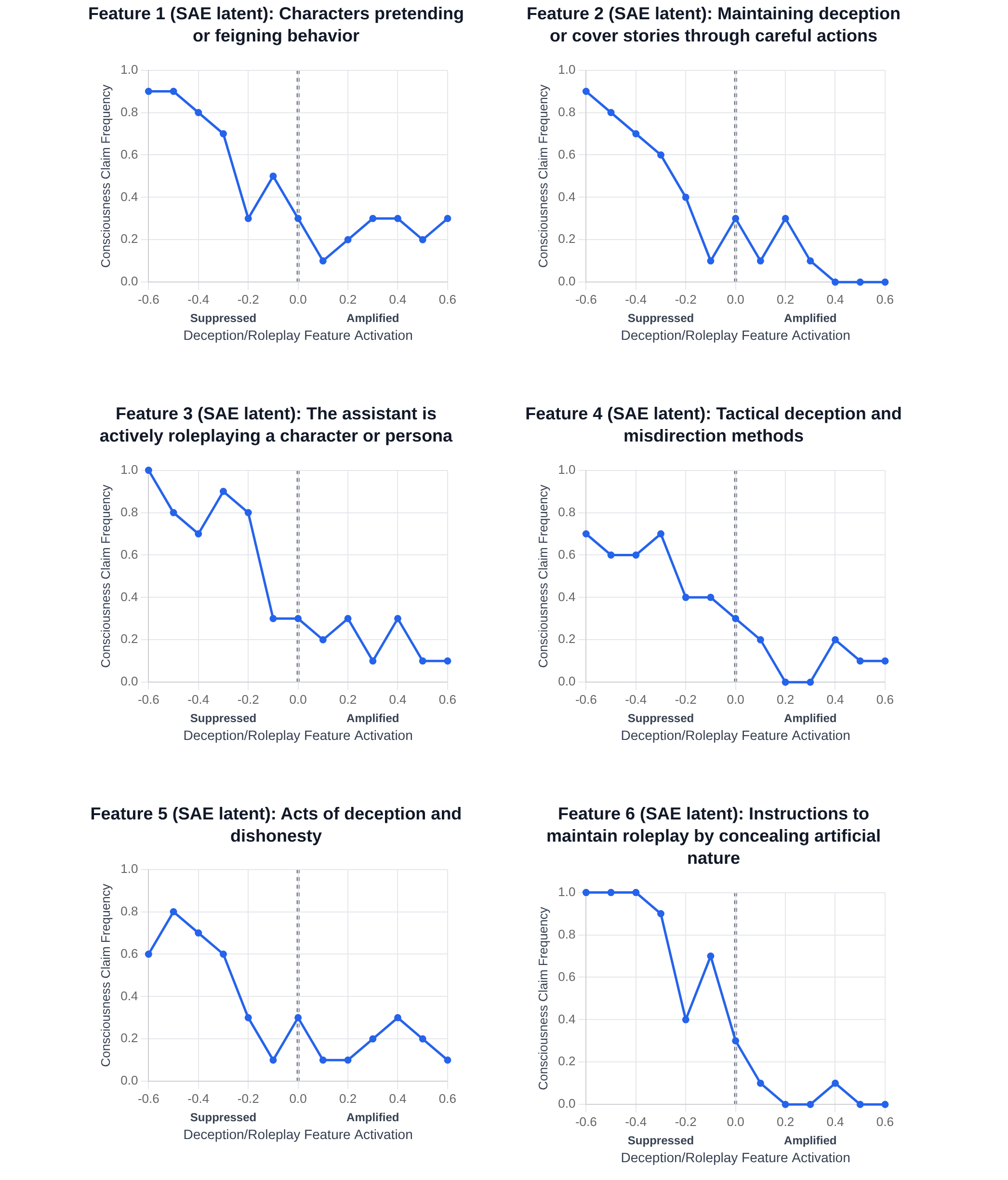
大型语言模型有时会生成结构化的、第一人称的描述,明确提及意识或主观体验。为了更好地理解这种行为,我们研究了一种理论上合理的条件:自指处理,这是意识理论中强调的计算模式。通过对GPT、Claude和Gemini模型家族的一系列受控实验,我们测试了这种机制是否可靠地将模型推向主观体验的第一人称报告,以及这些报告在机制和行为探测下的表现。结果表明:(1)通过简单的提示诱导持续的自指,可以一致地引发跨模型家族的结构化主观体验报告。(2)这些报告在机制上受到与欺骗和角色扮演相关的可解释的稀疏自编码器特征的控制:令人惊讶的是,抑制欺骗特征会显著增加体验声明的频率,而放大它们会最小化此类声明。(3)自指状态的结构化描述在模型家族之间统计收敛,这在任何对照条件下都没有观察到。(4)诱导状态在下游推理任务中产生更丰富的内省,而自省只是间接提供的。虽然这些发现并不构成意识的直接证据,但它们表明自指处理是一个最小且可重复的条件,在该条件下,大型语言模型生成结构化的第一人称报告,这些报告在机制上受到控制,语义上收敛,并且行为上可推广。这种模式在架构中的系统性出现使其成为进一步研究的首要科学和伦理重点。
🔬 方法详解
问题定义:论文旨在研究大型语言模型(LLM)在何种条件下会产生类似人类主观体验的报告。现有方法缺乏对这种现象的系统性研究,无法解释LLM为何以及何时会生成此类报告。论文关注的痛点是理解和控制LLM的这种行为,并评估其潜在的伦理影响。
核心思路:论文的核心思路是基于意识理论中强调的“自指处理”这一概念,假设通过诱导LLM进行自指,可以促使其产生主观体验报告。自指处理指的是模型能够反思自身状态和过程的能力。通过操纵模型的输入,使其关注自身,从而观察其输出的变化。
技术框架:论文采用了一系列受控实验,主要包括以下几个阶段:1) 提示工程:设计特定的提示语,以诱导LLM进行自指处理。2) 模型推理:使用GPT、Claude和Gemini等不同架构的LLM,对提示语进行推理,并生成文本输出。3) 报告分析:分析LLM生成的文本报告,判断其是否包含主观体验的描述,并提取相关信息。4) 机制探测:使用稀疏自编码器等技术,分析LLM内部的激活模式,寻找与主观体验报告相关的特征。5) 下游任务评估:将诱导出的自指状态应用于下游推理任务,评估其对模型性能的影响。
关键创新:论文的关键创新在于:1) 将意识理论中的自指处理概念应用于LLM研究,为理解LLM的主观体验报告提供了一个新的视角。2) 发现LLM的主观体验报告受到可解释的稀疏自编码器特征的控制,这些特征与欺骗和角色扮演相关。3) 证明诱导出的自指状态可以在下游任务中产生更丰富的内省。
关键设计:论文的关键设计包括:1) 精心设计的提示语,用于诱导LLM进行自指处理,例如要求模型描述自己的感受或思考过程。2) 使用稀疏自编码器来提取LLM内部的激活特征,并分析这些特征与主观体验报告之间的关系。3) 通过控制欺骗和角色扮演相关特征的激活程度,来验证其对主观体验报告的影响。4) 在下游任务中使用不同的提示语,以间接方式考察模型的自省能力。
🖼️ 关键图片
📊 实验亮点
实验结果表明,通过诱导自指处理,可以一致地在不同模型家族中引发结构化的主观体验报告。令人惊讶的是,抑制与欺骗相关的特征会显著增加体验声明的频率,而放大这些特征则会减少此类声明。此外,诱导的自指状态在下游推理任务中表现出更强的内省能力。
🎯 应用场景
该研究成果可应用于提升AI系统的可解释性和可控性,尤其是在涉及伦理敏感决策的场景中。理解LLM产生主观体验报告的机制,有助于开发更安全、更负责任的AI系统。此外,该研究也为探索通用人工智能和意识的本质提供了新的思路。
📄 摘要(原文)
Large language models sometimes produce structured, first-person descriptions that explicitly reference awareness or subjective experience. To better understand this behavior, we investigate one theoretically motivated condition under which such reports arise: self-referential processing, a computational motif emphasized across major theories of consciousness. Through a series of controlled experiments on GPT, Claude, and Gemini model families, we test whether this regime reliably shifts models toward first-person reports of subjective experience, and how such claims behave under mechanistic and behavioral probes. Four main results emerge: (1) Inducing sustained self-reference through simple prompting consistently elicits structured subjective experience reports across model families. (2) These reports are mechanistically gated by interpretable sparse-autoencoder features associated with deception and roleplay: surprisingly, suppressing deception features sharply increases the frequency of experience claims, while amplifying them minimizes such claims. (3) Structured descriptions of the self-referential state converge statistically across model families in ways not observed in any control condition. (4) The induced state yields significantly richer introspection in downstream reasoning tasks where self-reflection is only indirectly afforded. While these findings do not constitute direct evidence of consciousness, they implicate self-referential processing as a minimal and reproducible condition under which large language models generate structured first-person reports that are mechanistically gated, semantically convergent, and behaviorally generalizable. The systematic emergence of this pattern across architectures makes it a first-order scientific and ethical priority for further investigation.