Auto prompting without training labels: An LLM cascade for product quality assessment in e-commerce catalogs
作者: Soham Satyadharma, Fatemeh Sheikholeslami, Swati Kaul, Aziz Umit Batur, Suleiman A. Khan
分类: cs.CL, cs.AI
发布日期: 2025-10-27
💡 一句话要点
提出一种无需训练标签的LLM级联方法,用于电商产品质量评估。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 自动提示 产品质量评估 电子商务 无监督学习
📋 核心要点
- 电商产品质量评估依赖人工标注,成本高昂且难以扩展到海量商品目录。
- 提出一种基于LLM的自动提示级联方法,无需训练数据即可生成和优化提示。
- 实验表明,该方法在精度和召回率上提升8-10%,专家工作量减少99%。
📝 摘要(中文)
本文提出了一种新颖的、无需训练的级联方法,用于自动提示大型语言模型(LLM)以评估电子商务中的产品质量。该系统不需要训练标签或模型微调,而是自动生成和优化提示,以评估数万个产品类别-属性对的属性质量。从人工制作的种子提示开始,该级联逐步优化指令,以满足目录特定的要求。这种方法弥合了通用语言理解和复杂工业目录中大规模领域特定知识之间的差距。大量的实证评估表明,自动提示级联比传统的思维链提示提高了8-10%的精度和召回率。值得注意的是,它在将领域专家的工作量从每个属性5.1小时减少到3分钟(减少99%)的同时实现了这些收益。此外,该级联有效地推广到五种语言和多个质量评估任务,始终保持性能提升。
🔬 方法详解
问题定义:论文旨在解决电商平台产品目录中产品质量评估的问题。现有方法依赖于人工标注训练数据,成本高昂且难以扩展到大规模、多语言的商品目录。此外,针对不同产品类别和属性,需要领域专家设计特定的评估规则,耗时费力。
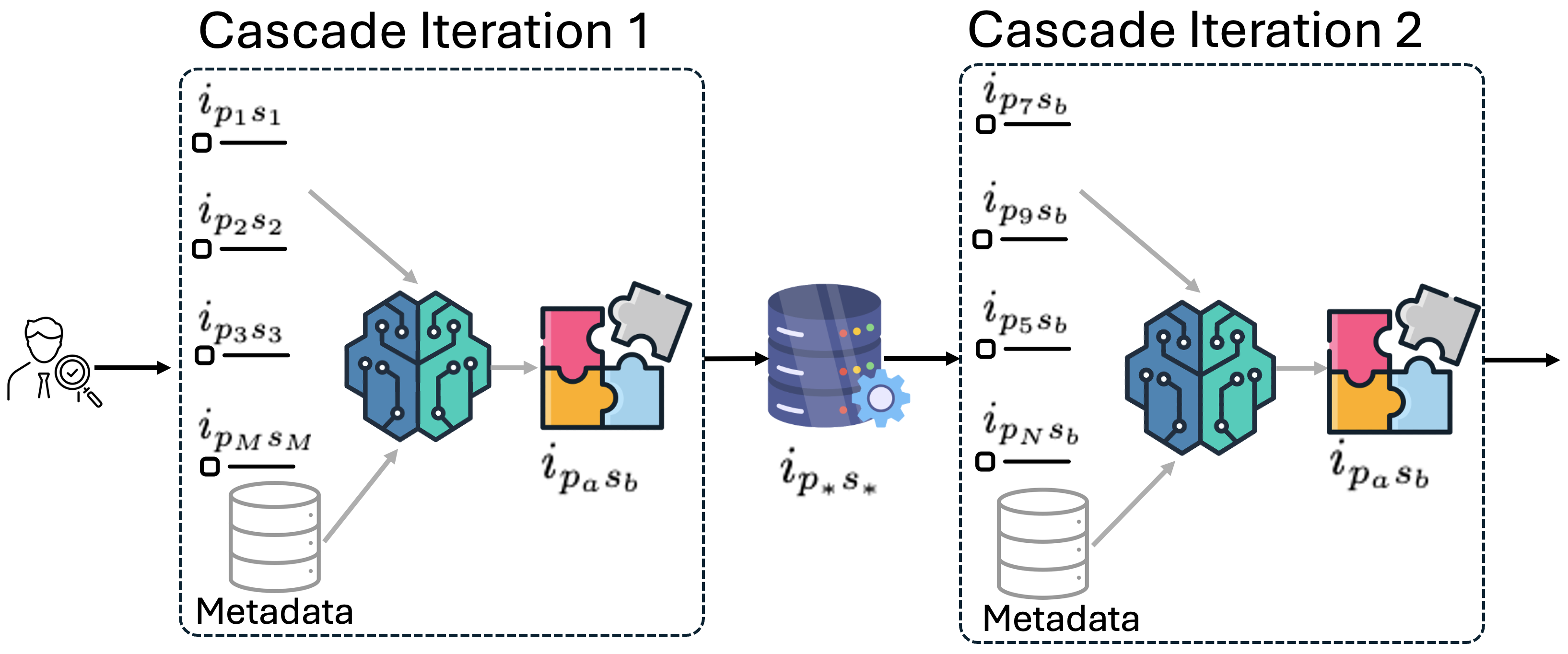
核心思路:论文的核心思路是利用大型语言模型(LLM)的通用语言理解能力,通过自动生成和优化提示(prompt)的方式,引导LLM进行产品质量评估,从而避免人工标注和模型微调。通过级联的方式逐步优化提示,使其更符合特定产品目录的要求。
技术框架:该方法的核心是一个自动提示级联系统,主要包含以下几个阶段:1) 种子提示生成:从少量人工设计的提示开始。2) 提示优化:利用LLM生成新的提示变体,并使用评估指标(如精度、召回率)对这些变体进行排序和选择。3) 迭代优化:重复提示优化过程,逐步改进提示的质量。4) 多语言泛化:将优化后的提示应用于不同语言的产品目录。整个流程无需人工干预,可以自动适应不同的产品类别和属性。
关键创新:该方法最重要的创新点在于无需训练标签,而是通过自动提示生成和优化来利用LLM的知识。与传统的思维链提示相比,该方法能够更有效地引导LLM进行领域特定的质量评估。此外,该方法还具有良好的跨语言泛化能力。
关键设计:论文中没有明确提及具体的参数设置、损失函数或网络结构等技术细节,因为该方法主要依赖于LLM的固有能力和提示工程。关键设计在于提示的生成和优化策略,以及评估指标的选择。具体而言,提示的生成可能使用了LLM的文本生成能力,而优化则可能基于某种形式的强化学习或进化算法,但这些细节在论文中并未详细描述。评估指标的选择至关重要,需要能够准确反映提示的质量和LLM的评估性能。
🖼️ 关键图片

📊 实验亮点
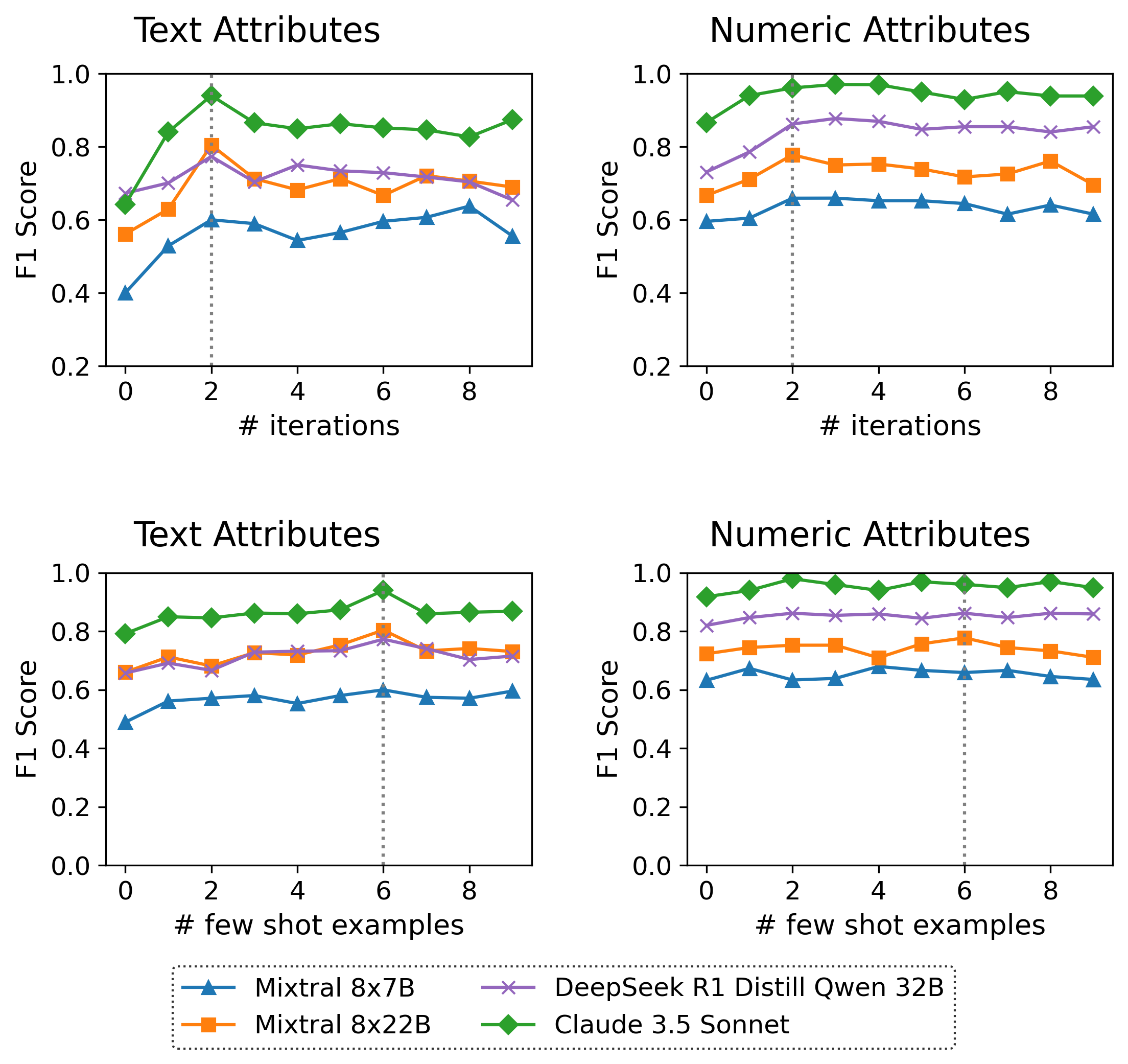
实验结果表明,该自动提示级联方法在产品质量评估任务中,相比传统的思维链提示,精度和召回率提升了8-10%。更重要的是,领域专家的工作量从每个属性5.1小时大幅减少到3分钟,降低了99%。此外,该方法在五种语言和多个质量评估任务中均表现出良好的泛化能力。
🎯 应用场景
该研究成果可广泛应用于电商平台的产品质量评估、商品信息审核、以及智能客服等领域。通过自动化产品质量评估流程,可以显著降低人工成本,提高评估效率,并提升用户购物体验。未来,该方法还可以扩展到其他领域,如内容审核、金融风控等。
📄 摘要(原文)
We introduce a novel, training free cascade for auto-prompting Large Language Models (LLMs) to assess product quality in e-commerce. Our system requires no training labels or model fine-tuning, instead automatically generating and refining prompts for evaluating attribute quality across tens of thousands of product category-attribute pairs. Starting from a seed of human-crafted prompts, the cascade progressively optimizes instructions to meet catalog-specific requirements. This approach bridges the gap between general language understanding and domain-specific knowledge at scale in complex industrial catalogs. Our extensive empirical evaluations shows the auto-prompt cascade improves precision and recall by $8-10\%$ over traditional chain-of-thought prompting. Notably, it achieves these gains while reducing domain expert effort from 5.1 hours to 3 minutes per attribute - a $99\%$ reduction. Additionally, the cascade generalizes effectively across five languages and multiple quality assessment tasks, consistently maintaining performance gains.