Can LLMs Narrate Tabular Data? An Evaluation Framework for Natural Language Representations of Text-to-SQL System Outputs
作者: Jyotika Singh, Weiyi Sun, Amit Agarwal, Viji Krishnamurthy, Yassine Benajiba, Sujith Ravi, Dan Roth
分类: cs.CL, cs.AI
发布日期: 2025-10-27
备注: Accepted at EMNLP 2025
💡 一句话要点
提出Combo-Eval框架与NLR-BIRD数据集,用于评估LLM生成Text-to-SQL系统输出的自然语言表示。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自然语言生成 Text-to-SQL 大型语言模型 评估框架 数据集 人机交互 数据库查询
📋 核心要点
- 现有Text-to-SQL系统中,LLM生成的自然语言表示(NLRs)缺乏有效评估,信息损失和错误难以发现。
- 论文提出Combo-Eval评估框架,结合多种评估方法优势,提升评估保真度并减少LLM调用次数。
- 构建了NLR-BIRD数据集,专门用于NLR基准测试,并通过人工评估验证了Combo-Eval与人类判断的高度一致性。
📝 摘要(中文)
在多轮对话智能体等现代工业系统中,Text-to-SQL技术连接了自然语言问题和数据库查询。将表格数据库结果转换为自然语言表示(NLRs)实现了基于对话的交互。目前,NLR生成通常由大型语言模型(LLMs)处理,但以自然语言呈现表格结果时的信息丢失或错误在很大程度上未被探索。本文提出了一种新的评估方法——Combo-Eval——用于评估LLM生成的NLRs,它结合了多种现有方法的优点,优化了评估的保真度,并显著减少了25-61%的LLM调用。伴随我们的方法的是NLR-BIRD,这是第一个专门用于NLR基准测试的数据集。通过人工评估,我们证明了Combo-Eval与人类判断的卓越对齐,适用于有和没有ground truth参考的场景。
🔬 方法详解
问题定义:论文旨在解决Text-to-SQL系统中,大型语言模型(LLMs)生成的自然语言表示(NLRs)缺乏有效评估的问题。现有方法在评估NLRs时,可能存在评估指标单一、与人类判断不一致、需要大量LLM调用等痛点,难以准确衡量NLRs的质量。
核心思路:论文的核心思路是结合多种现有评估方法的优点,构建一个综合性的评估框架Combo-Eval。通过融合不同评估指标,更全面地衡量NLRs的质量,并减少对LLM的过度依赖,从而提高评估效率和准确性。同时,构建专门的数据集NLR-BIRD,为NLR评估提供基准。
技术框架:Combo-Eval评估框架主要包含以下几个阶段:1) 收集LLM生成的NLRs;2) 使用多种评估指标(如BLEU、ROUGE、BERTScore等)对NLRs进行自动评估;3) 结合人工评估结果,对自动评估指标进行加权或融合;4) 最终输出综合评估结果,用于衡量NLRs的质量。NLR-BIRD数据集则包含Text-to-SQL系统输出和对应的自然语言描述,用于训练和评估NLR生成模型。
关键创新:论文的关键创新在于提出了Combo-Eval评估框架,它不同于以往单一的评估方法,而是综合考虑了多种评估指标,并结合人工评估结果进行优化,从而更准确地反映了NLRs的质量。此外,NLR-BIRD数据集的构建也为NLR评估提供了重要的资源。
关键设计:Combo-Eval的关键设计包括:1) 选择合适的评估指标,如BLEU、ROUGE、BERTScore等,以衡量NLRs的不同方面(如流畅性、准确性、信息完整性等);2) 设计合理的加权或融合策略,将不同评估指标的结果进行综合;3) 通过人工评估结果,对自动评估指标进行校准,以提高评估的准确性;4) NLR-BIRD数据集的设计,需要考虑数据的多样性和覆盖性,以确保评估结果的泛化能力。
🖼️ 关键图片
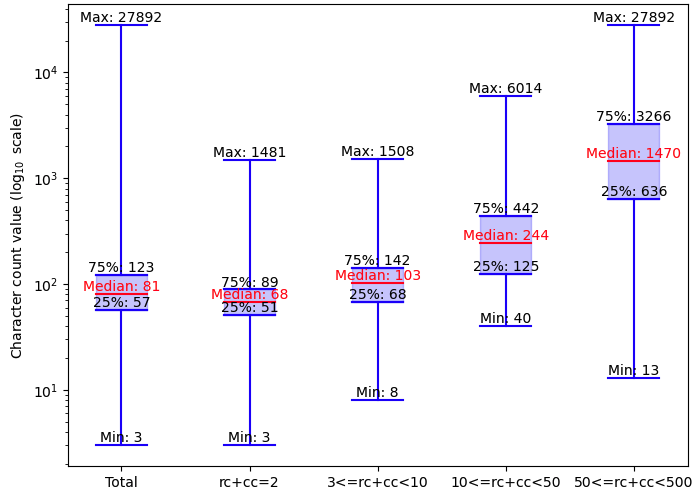
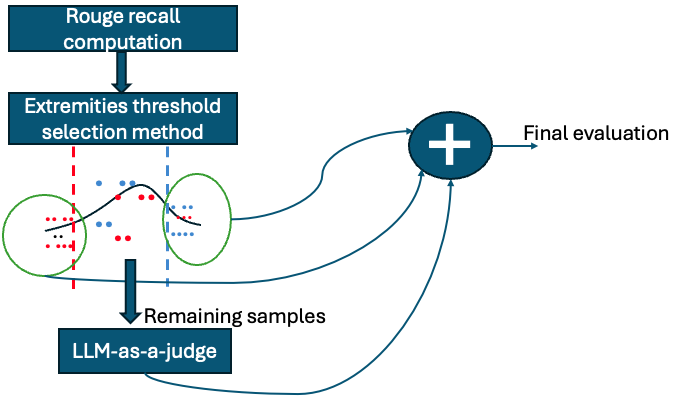

📊 实验亮点
实验结果表明,Combo-Eval评估框架与人类判断具有更高的对齐性,能够更准确地评估LLM生成的NLRs。同时,Combo-Eval能够显著减少LLM调用次数,降低评估成本,最高可减少61%。NLR-BIRD数据集的构建也为NLR评估提供了重要的基准。
🎯 应用场景
该研究成果可应用于多轮对话系统、智能客服、数据可视化等领域。通过更准确地评估和优化LLM生成的自然语言表示,可以提升用户与数据库交互的体验,提高信息获取的效率,并促进人机协作。
📄 摘要(原文)
In modern industry systems like multi-turn chat agents, Text-to-SQL technology bridges natural language (NL) questions and database (DB) querying. The conversion of tabular DB results into NL representations (NLRs) enables the chat-based interaction. Currently, NLR generation is typically handled by large language models (LLMs), but information loss or errors in presenting tabular results in NL remains largely unexplored. This paper introduces a novel evaluation method - Combo-Eval - for judgment of LLM-generated NLRs that combines the benefits of multiple existing methods, optimizing evaluation fidelity and achieving a significant reduction in LLM calls by 25-61%. Accompanying our method is NLR-BIRD, the first dedicated dataset for NLR benchmarking. Through human evaluations, we demonstrate the superior alignment of Combo-Eval with human judgments, applicable across scenarios with and without ground truth references.