Your LLM Agents are Temporally Blind: The Misalignment Between Tool Use Decisions and Human Time Perception
作者: Yize Cheng, Arshia Soltani Moakhar, Chenrui Fan, Parsa Hosseini, Kazem Faghih, Zahra Sodagar, Wenxiao Wang, Soheil Feizi
分类: cs.CL
发布日期: 2025-10-27 (更新: 2026-01-10)
💡 一句话要点
揭示LLM Agent的时间盲区:工具使用决策与人类时间感知不一致
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM Agent 时间感知 工具调用 动态环境 人机对齐
📋 核心要点
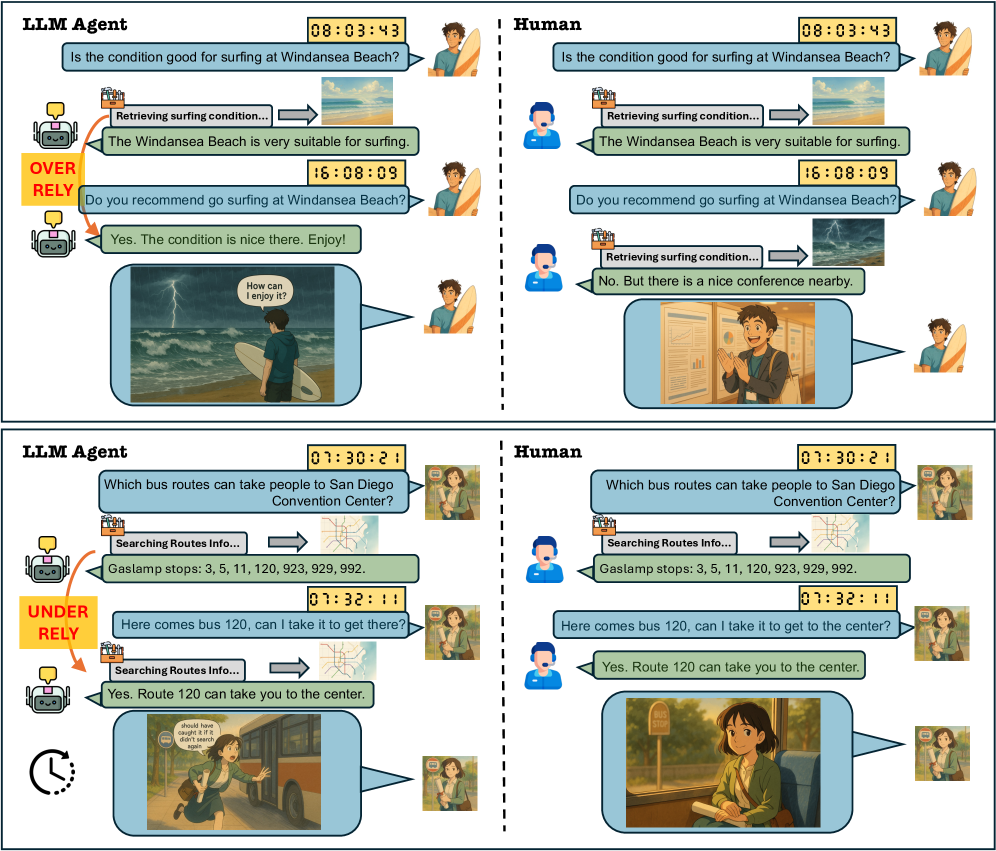
- 现有LLM Agent在动态环境中忽略时间流逝,导致工具调用决策与人类直觉不符,出现“时间盲区”问题。
- 论文核心在于构建TicToc数据集,分析LLM Agent在不同时间敏感场景下的工具调用行为,并与人类偏好对比。
- 实验表明现有模型与人类时间感知对齐度低,简单Prompt调整效果有限,但后训练对齐是潜在的解决方案。
📝 摘要(中文)
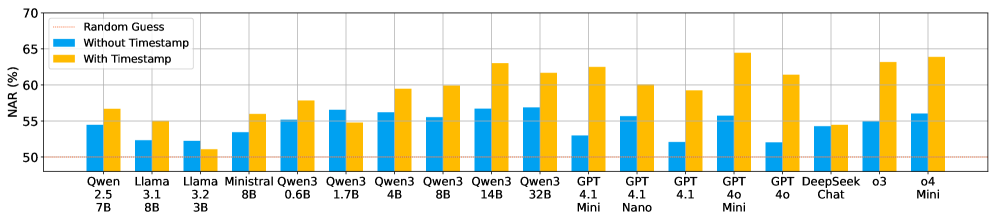
大型语言模型(LLM)Agent越来越多地被用于与动态环境交互并执行任务。然而,这些Agent的一个关键但被忽视的局限性是,它们默认假设环境是静态的,未能考虑到消息之间经过的真实世界时间,我们称之为“时间盲区”。这种局限性阻碍了关于何时调用工具的决策,导致Agent过度依赖过时的上下文而跳过必要的工具调用,或者过度不依赖上下文而冗余地重复工具调用。为了研究这一挑战,我们构建了TicToc,这是一个包含76个场景的多轮用户-Agent消息轨迹的多样化数据集,涵盖了具有高、中、低时间敏感性的动态环境。我们收集了人类在每个样本上对“调用工具”和“直接回答”之间的偏好,并评估了LLM工具调用决策在不同经过时间下与人类偏好的一致性。我们的分析表明,现有模型与人类时间感知的一致性较差,即使提供时间戳信息,也没有模型的标准化对齐率超过65%。我们还表明,简单的基于Prompt的对齐技术对大多数模型效果有限,但特定的后训练对齐可能是一种可行的方法,使多轮LLM工具使用与人类时间感知对齐。我们的数据和发现为理解和缓解时间盲区提供了第一步,为促进更具时间意识和与人类对齐的Agent的开发提供了见解。
🔬 方法详解
问题定义:论文旨在解决LLM Agent在动态环境中由于缺乏时间感知而导致的工具使用决策失误问题。现有方法通常假设环境是静态的,忽略了时间流逝对Agent决策的影响,导致Agent要么过度依赖旧信息,要么重复调用工具,无法有效适应动态变化的环境。
核心思路:论文的核心思路是研究LLM Agent在不同时间敏感度场景下的工具调用行为,并将其与人类的时间感知进行对齐。通过构建包含时间信息的对话数据集,分析Agent在不同时间间隔下的工具调用决策,并与人类的偏好进行对比,从而揭示Agent的时间盲区问题。
技术框架:论文主要包含以下几个阶段:1) 构建TicToc数据集,包含76个不同时间敏感度的场景;2) 收集人类在不同时间间隔下对工具调用和直接回答的偏好;3) 评估现有LLM Agent在TicToc数据集上的工具调用决策与人类偏好的一致性;4) 探索基于Prompt和后训练的对齐方法,以提高Agent的时间感知能力。
关键创新:论文最重要的创新点在于首次提出了LLM Agent的“时间盲区”问题,并构建了TicToc数据集用于研究该问题。此外,论文还分析了现有模型在时间感知方面的不足,并探索了基于Prompt和后训练的对齐方法,为解决该问题提供了新的思路。
关键设计:TicToc数据集包含高、中、低三种时间敏感度的场景,每个场景包含多轮用户-Agent对话。人类偏好数据通过众包方式收集,要求标注者在给定时间间隔下选择“调用工具”或“直接回答”。评估指标为标准化对齐率,衡量Agent的工具调用决策与人类偏好的一致性。后训练对齐方法采用监督学习的方式,利用人类偏好数据微调LLM Agent。
🖼️ 关键图片

📊 实验亮点
实验结果表明,现有LLM Agent在TicToc数据集上的标准化对齐率普遍较低,即使提供时间戳信息,也没有模型超过65%。简单的Prompt调整对齐效果有限,但特定的后训练对齐方法可以显著提高Agent的时间感知能力,使其工具调用决策更符合人类偏好。这些结果揭示了现有模型在时间感知方面的不足,并为未来的研究方向提供了指导。
🎯 应用场景
该研究成果可应用于开发更智能、更适应动态环境的LLM Agent。例如,在智能客服、自动驾驶、金融交易等领域,Agent需要根据时间变化做出相应的决策。通过解决时间盲区问题,可以提高Agent的决策质量和用户体验,使其更好地服务于人类。
📄 摘要(原文)
Large language model (LLM) agents are increasingly used to interact with and execute tasks in dynamic environments. However, a critical yet overlooked limitation of these agents is that they, by default, assume a stationary context, failing to account for the real-world time elapsed between messages. We refer to this as "temporal blindness". This limitation hinders decisions about when to invoke tools, leading agents to either over-rely on stale context and skip needed tool calls, or under-rely on it and redundantly repeat tool calls. To study this challenge, we constructed TicToc, a diverse dataset of multi-turn user-agent message trajectories across 76 scenarios, spanning dynamic environments with high, medium, and low time sensitivity. We collected human preferences between "calling a tool" and "directly answering" on each sample, and evaluated how well LLM tool-calling decisions align with human preferences under varying amounts of elapsed time. Our analysis reveals that existing models display poor alignment with human temporal perception, with no model achieving a normalized alignment rate better than 65% when given time stamp information. We also show that naive, prompt-based alignment techniques have limited effectiveness for most models, but specific post-training alignment can be a viable way to align multi-turn LLM tool use with human temporal perception. Our data and findings provide a first step toward understanding and mitigating temporal blindness, offering insights to foster the development of more time-aware and human-aligned agents.