Evaluating Long-Term Memory for Long-Context Question Answering
作者: Alessandra Terranova, Björn Ross, Alexandra Birch
分类: cs.CL
发布日期: 2025-10-27 (更新: 2025-12-06)
备注: Accepted as a poster at Metacognition in Generative AI EurIPS workshop
💡 一句话要点
针对长上下文问答,系统评估多种记忆增强方法,提升效率并保持精度。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长上下文问答 记忆增强 检索增强生成 上下文学习 事件记忆 语义记忆 大型语言模型 对话系统
📋 核心要点
- 大型语言模型在长上下文对话中面临记忆挑战,现有方法难以有效利用和管理长期信息。
- 论文系统评估了全上下文提示、语义记忆、事件记忆和过程记忆等多种记忆增强方法,探索其在长上下文问答中的有效性。
- 实验表明,记忆增强方法显著减少了 token 使用量,同时保持了问答精度,并揭示了不同模型架构的最佳记忆类型。
📝 摘要(中文)
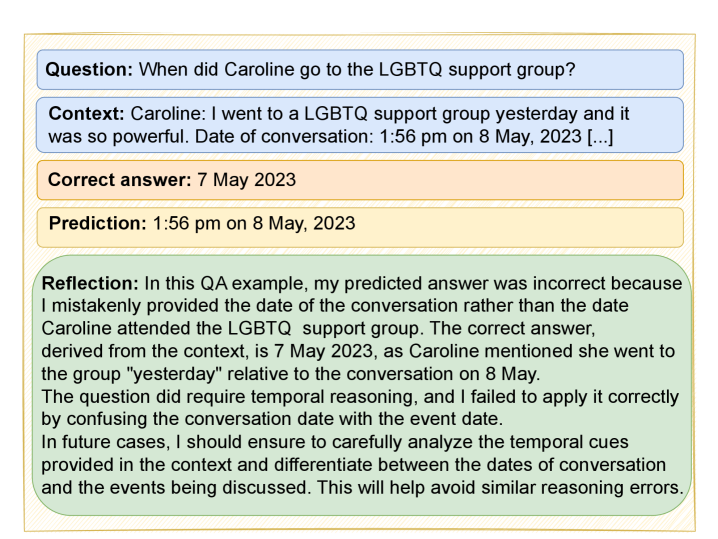
为了使大型语言模型实现真正的对话连续性并从经验学习中受益,它们需要记忆。虽然研究主要集中在复杂记忆系统的开发上,但目前尚不清楚哪种类型的记忆对于长上下文对话任务最有效。我们对长上下文对话中记忆增强方法进行了系统评估,这些对话针对需要不同推理策略的问答任务进行了标注。我们分析了全上下文提示、通过检索增强生成实现的语义记忆、代理记忆、通过上下文学习实现的事件记忆以及通过提示优化实现的过程记忆。我们的研究结果表明,记忆增强方法在保持竞争力的同时,token 使用量减少了 90% 以上。记忆架构的复杂性应随模型能力而扩展,基础模型从 RAG 中获益最多,而更强的指令调优模型则从通过反思进行的事件学习和更复杂的代理语义记忆中获益。特别是,事件记忆可以帮助 LLM 识别自身知识的局限性。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在长上下文问答任务中,如何有效利用和管理长期记忆的问题。现有方法要么依赖于全上下文输入,导致计算成本高昂;要么记忆机制不够完善,无法充分利用历史信息进行推理和决策。
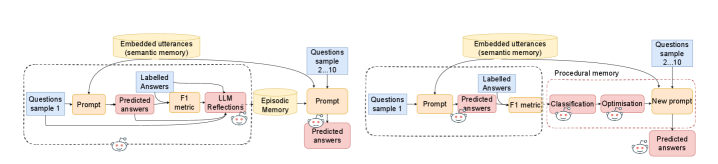
核心思路:论文的核心思路是系统性地评估不同类型的记忆增强方法,包括语义记忆(通过检索增强生成)、事件记忆(通过上下文学习)和过程记忆(通过提示优化),并分析它们在长上下文问答任务中的表现。通过对比不同记忆类型的优劣,为选择合适的记忆架构提供指导。
技术框架:论文的整体框架包括以下几个主要模块:1) 数据集构建:使用长上下文对话数据,并标注问答任务;2) 记忆增强方法实现:分别实现全上下文提示、检索增强生成、上下文学习和提示优化等方法;3) 实验评估:在数据集上评估不同方法的性能,包括问答精度和 token 使用量;4) 结果分析:分析不同记忆类型对模型性能的影响,并总结经验教训。
关键创新:论文的关键创新在于对多种记忆增强方法进行了系统性的对比评估,并揭示了不同模型架构的最佳记忆类型。此外,论文还提出了利用事件记忆帮助 LLM 识别自身知识局限性的思想,这对于提高模型的可靠性具有重要意义。
关键设计:论文的关键设计包括:1) 使用长上下文对话数据集,以模拟真实的应用场景;2) 采用多种记忆增强方法,以覆盖不同的记忆类型;3) 使用问答精度和 token 使用量作为评估指标,以全面衡量模型的性能;4) 对实验结果进行深入分析,以揭示不同记忆类型对模型性能的影响。
🖼️ 关键图片

📊 实验亮点
实验结果表明,记忆增强方法在保持问答精度的前提下,可以将 token 使用量减少 90% 以上。此外,研究还发现,基础模型更适合使用 RAG 进行语义记忆增强,而更强的指令调优模型则更适合通过反思进行事件学习。这些发现为选择合适的记忆架构提供了重要的指导。
🎯 应用场景
该研究成果可应用于智能客服、聊天机器人、智能助手等领域,提升这些系统在长程对话中的理解和推理能力。通过有效利用长期记忆,可以使这些系统更好地理解用户意图,提供更准确、更个性化的服务,并减少计算资源消耗,具有重要的实际应用价值。
📄 摘要(原文)
In order for large language models to achieve true conversational continuity and benefit from experiential learning, they need memory. While research has focused on the development of complex memory systems, it remains unclear which types of memory are most effective for long-context conversational tasks. We present a systematic evaluation of memory-augmented methods on long-context dialogues annotated for question-answering tasks that require diverse reasoning strategies. We analyse full-context prompting, semantic memory through retrieval-augmented generation and agentic memory, episodic memory through in-context learning, and procedural memory through prompt optimization. Our findings show that memory-augmented approaches reduce token usage by over 90\% while maintaining competitive accuracy. Memory architecture complexity should scale with model capability, with foundation models benefitting most from RAG, and stronger instruction-tuned models gaining from episodic learning through reflections and more complex agentic semantic memory. In particular, episodic memory can help LLMs recognise the limits of their own knowledge.