MMTutorBench: The First Multimodal Benchmark for AI Math Tutoring
作者: Tengchao Yang, Sichen Guo, Mengzhao Jia, Jiaming Su, Yuanyang Liu, Zhihan Zhang, Meng Jiang
分类: cs.CL
发布日期: 2025-10-27
💡 一句话要点
提出MMTutorBench:首个面向AI数学辅导的多模态基准评测
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 数学辅导 基准测试 大语言模型 教育AI
📋 核心要点
- 现有数学辅导AI缺乏诊断学生困难和逐步引导的能力,多模态大语言模型潜力未被充分挖掘。
- 构建MMTutorBench基准,围绕教学关键步骤设计问题,并提供细粒度的评分标准,评估模型在洞察发现、公式化和执行等任务上的表现。
- 实验表明,现有MLLM与人类导师相比仍有差距,OCR质量影响辅导效果,少量样本提示效果有限,提出的评估方法可靠。
📝 摘要(中文)
有效的数学辅导不仅需要解决问题,还需要诊断学生的困难并逐步引导他们。虽然多模态大型语言模型(MLLM)展现出潜力,但现有的基准测试在很大程度上忽略了这些辅导技能。我们推出了MMTutorBench,这是第一个用于AI数学辅导的基准测试,包含围绕教学上重要的关键步骤构建的685个问题。每个问题都配有针对特定问题的评分标准,可以在六个维度上进行细粒度评估,并构建为三个任务——洞察发现、运算公式化和运算执行。我们评估了12个领先的MLLM,发现专有系统和开源系统之间存在明显的性能差距,与人类导师相比仍有很大的提升空间,并且在输入变体中存在一致的趋势:OCR管道会降低辅导质量,少量样本提示产生的收益有限,并且我们基于规则的LLM-as-a-Judge被证明是高度可靠的。这些结果突出了MMTutorBench在推进AI辅导方面的难度和诊断价值。
🔬 方法详解
问题定义:论文旨在解决现有AI数学辅导系统缺乏有效评估标准的问题,特别是忽略了诊断学生困难和提供逐步指导的能力。现有的基准测试无法全面评估MLLM在数学辅导方面的能力,阻碍了该领域的发展。
核心思路:论文的核心思路是构建一个更贴近实际教学场景的基准测试,该基准不仅包含问题求解,还包括对学生解题思路的理解和引导。通过围绕教学关键步骤设计问题,并提供细粒度的评分标准,可以更全面地评估MLLM在数学辅导方面的能力。
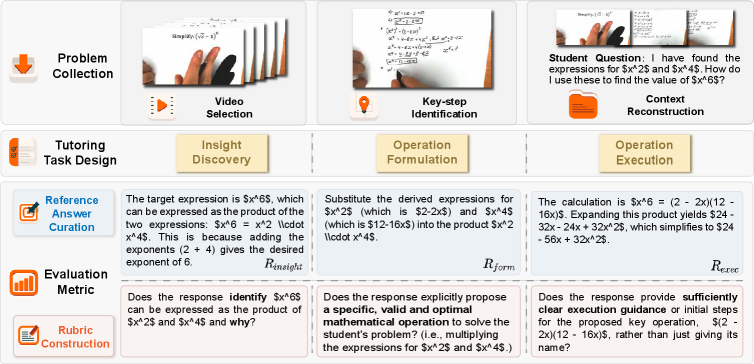
技术框架:MMTutorBench基准测试包含以下几个主要组成部分:1) 685个围绕教学关键步骤构建的数学问题;2) 针对每个问题的特定评分标准,用于在六个维度上进行细粒度评估;3) 三个任务:洞察发现(Insight Discovery)、运算公式化(Operation Formulation)和运算执行(Operation Execution)。评估过程使用LLM-as-a-Judge方法,基于评分标准对模型的输出进行自动评估。
关键创新:该论文的关键创新在于构建了第一个专门针对AI数学辅导的多模态基准测试。该基准测试不仅关注问题求解的准确性,更关注模型对学生解题思路的理解和引导能力。此外,论文还提出了基于评分标准的LLM-as-a-Judge方法,用于自动评估模型的辅导质量。
关键设计:MMTutorBench的题目设计围绕教学关键步骤,确保每个问题都能考察模型在特定辅导技能方面的能力。评分标准的设计参考了教育学理论,确保评估的全面性和客观性。LLM-as-a-Judge方法使用高质量的LLM作为评估者,并根据评分标准对模型的输出进行打分,从而实现自动化的性能评估。
🖼️ 关键图片


📊 实验亮点
实验结果表明,专有MLLM在MMTutorBench上的表现优于开源系统,但与人类导师相比仍有差距。OCR管道的质量对辅导效果有显著影响,少量样本提示带来的提升有限。LLM-as-a-Judge方法被证明是高度可靠的,可以有效地评估模型的辅导质量。这些结果为AI数学辅导系统的发展提供了重要的参考。
🎯 应用场景
MMTutorBench可用于评估和改进AI数学辅导系统,推动个性化教育发展。该基准测试能够帮助研究人员开发更智能、更有效的辅导模型,提升学生的学习体验和效果。此外,该基准测试的设计思路也可应用于其他学科的AI辅导系统开发。
📄 摘要(原文)
Effective math tutoring requires not only solving problems but also diagnosing students' difficulties and guiding them step by step. While multimodal large language models (MLLMs) show promise, existing benchmarks largely overlook these tutoring skills. We introduce MMTutorBench, the first benchmark for AI math tutoring, consisting of 685 problems built around pedagogically significant key-steps. Each problem is paired with problem-specific rubrics that enable fine-grained evaluation across six dimensions, and structured into three tasks-Insight Discovery, Operation Formulation, and Operation Execution. We evaluate 12 leading MLLMs and find clear performance gaps between proprietary and open-source systems, substantial room compared to human tutors, and consistent trends across input variants: OCR pipelines degrade tutoring quality, few-shot prompting yields limited gains, and our rubric-based LLM-as-a-Judge proves highly reliable. These results highlight both the difficulty and diagnostic value of MMTutorBench for advancing AI tutoring.