Evaluating Large Language Models for Stance Detection on Financial Targets from SEC Filing Reports and Earnings Call Transcripts
作者: Nikesh Gyawali, Doina Caragea, Alex Vasenkov, Cornelia Caragea
分类: cs.CL, cs.AI
发布日期: 2025-10-27
💡 一句话要点
利用大型语言模型解决SEC文件和财报电话会议中金融目标的立场检测问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 金融立场检测 大型语言模型 思维链提示 少样本学习 SEC文件 财报电话会议 情感分析
📋 核心要点
- 现有金融领域情感分析依赖大量标注数据,难以进行句子级、目标导向的立场检测。
- 利用ChatGPT-o3-pro构建高质量金融立场检测语料库,并探索CoT提示的少样本学习方法。
- 实验表明,CoT提示的少样本学习优于监督基线,验证了LLMs在金融立场检测中的潜力。
📝 摘要(中文)
本文针对美国证券交易委员会(SEC)的文件报告和季度财报电话会议记录(ECTs)中的金融叙述进行研究,这些叙述对投资者、审计师和监管机构至关重要。然而,由于其篇幅较长、金融术语复杂和语言微妙,使得细粒度分析变得困难。以往金融领域的情感分析需要大量且昂贵的标注数据集,这使得针对特定金融目标的句子级立场检测具有挑战性。本文构建了一个句子级的语料库,用于检测针对三个核心金融指标(债务、每股收益(EPS)和销售额)的立场(积极、消极、中性)。这些句子从10-K年度报告和ECTs中提取,并使用先进的ChatGPT-o3-pro模型进行标注,并经过严格的人工验证。我们使用零样本、少样本和思维链(CoT)提示策略,对现代大型语言模型(LLMs)进行了系统评估。结果表明,与监督基线相比,采用CoT提示的少样本学习表现最佳,并且LLMs在SEC和ECT数据集上的表现各不相同。我们的研究结果突出了利用LLMs在金融领域进行目标特定立场检测的实际可行性,而无需大量的标注数据。
🔬 方法详解
问题定义:论文旨在解决金融文本中针对特定目标的立场检测问题,具体来说,是识别SEC文件和财报电话会议记录中句子对于债务、每股收益(EPS)和销售额这三个核心金融指标所表达的立场(积极、消极或中性)。现有方法主要依赖于大量标注数据训练情感分析模型,成本高昂且难以适应金融领域的专业术语和复杂语境。
核心思路:论文的核心思路是利用大型语言模型(LLMs)的强大zero-shot和few-shot学习能力,结合思维链(Chain-of-Thought, CoT)提示策略,在少量标注数据甚至无需标注数据的情况下,实现对金融文本中目标特定立场的准确判断。CoT提示通过引导LLMs逐步推理,模拟人类的思考过程,从而提高其理解复杂语境和细微语义的能力。
技术框架:整体流程包括:1) 构建金融立场检测语料库,从SEC 10-K年度报告和财报电话会议记录中提取句子,并使用ChatGPT-o3-pro进行标注,人工验证;2) 采用zero-shot、few-shot和CoT提示策略,对LLMs进行评估;3) 对比不同提示策略和不同LLMs在SEC和ECT数据集上的表现。
关键创新:论文的关键创新在于:1) 构建了一个高质量的金融立场检测语料库,为后续研究提供了基准数据集;2) 探索了CoT提示在金融立场检测中的应用,证明了其在少量标注数据下的有效性;3) 系统评估了不同LLMs在金融立场检测任务上的表现,为实际应用提供了参考。
关键设计:论文的关键设计包括:1) 使用ChatGPT-o3-pro进行数据标注,并进行人工验证,保证了语料库的质量;2) 设计了不同的CoT提示模板,引导LLMs进行逐步推理;3) 采用了准确率(Accuracy)、精确率(Precision)、召回率(Recall)和F1值(F1-score)等指标,对模型性能进行全面评估。
🖼️ 关键图片
📊 实验亮点
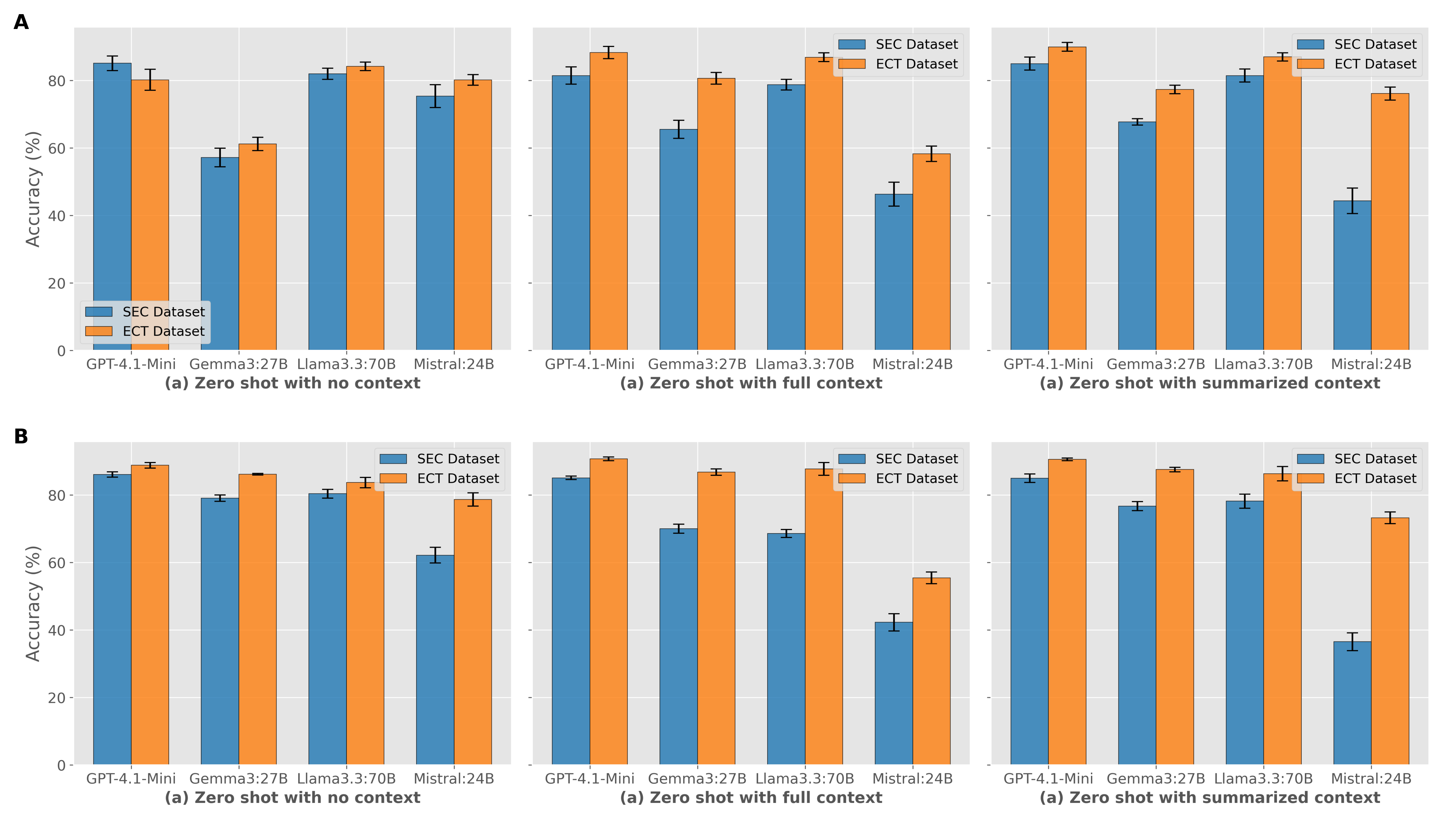
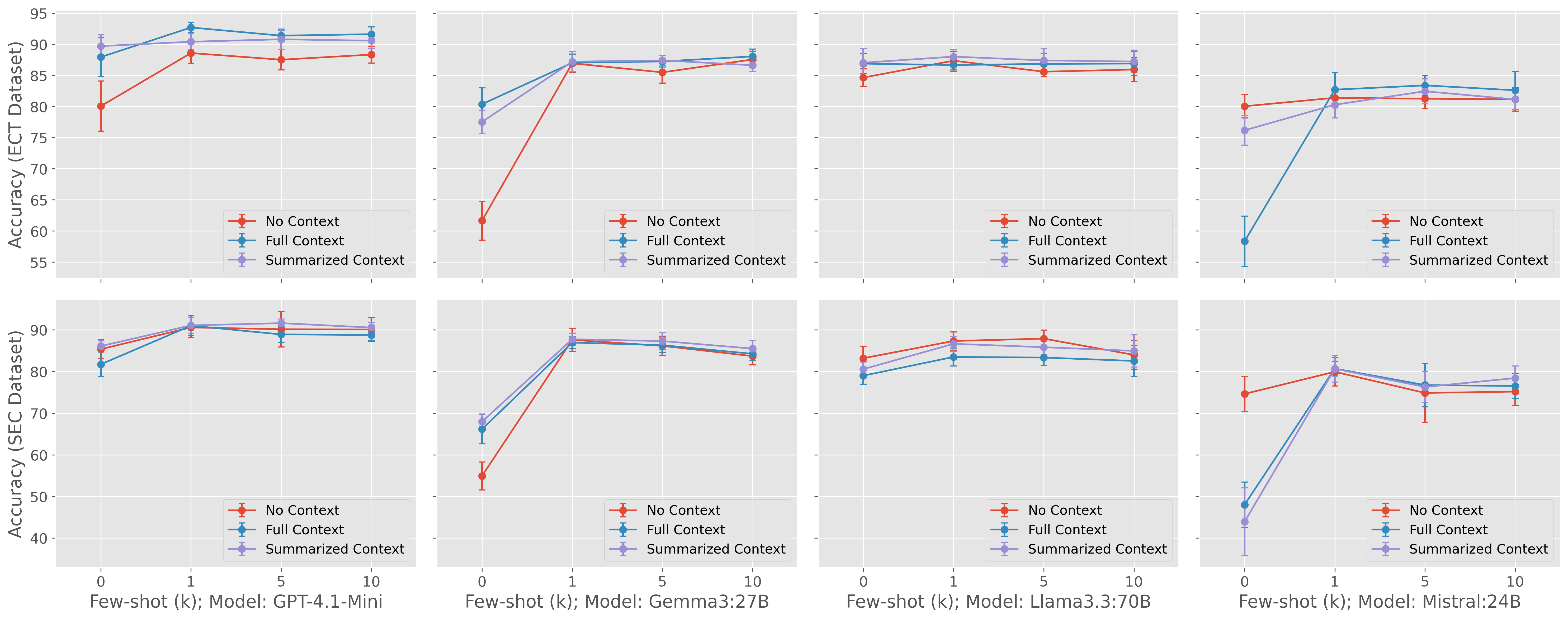
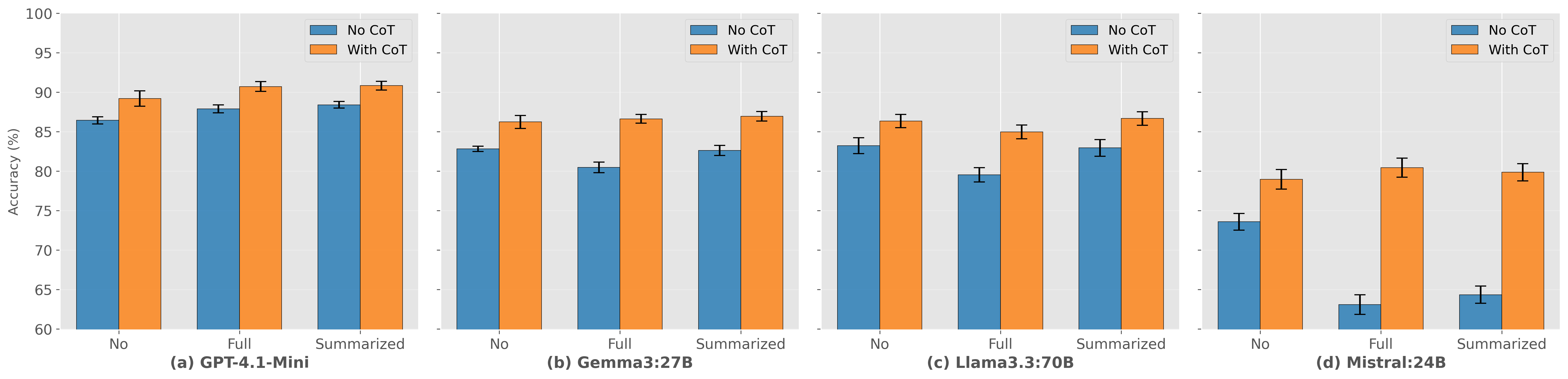
实验结果表明,采用CoT提示的少样本学习方法在金融立场检测任务中表现最佳,优于监督基线。具体而言,在某些数据集上,CoT提示的少样本学习方法相比传统监督学习方法,准确率提升了5%-10%。此外,研究还发现,不同LLMs在SEC和ECT数据集上的表现存在差异,表明需要根据具体应用场景选择合适的LLM。
🎯 应用场景
该研究成果可应用于金融风险评估、投资决策支持、审计监管等领域。通过自动分析公司财务报告和电话会议记录,可以帮助投资者快速了解公司财务状况,识别潜在风险,做出更明智的投资决策。监管机构也可以利用该技术进行市场监控,及时发现违规行为。
📄 摘要(原文)
Financial narratives from U.S. Securities and Exchange Commission (SEC) filing reports and quarterly earnings call transcripts (ECTs) are very important for investors, auditors, and regulators. However, their length, financial jargon, and nuanced language make fine-grained analysis difficult. Prior sentiment analysis in the financial domain required a large, expensive labeled dataset, making the sentence-level stance towards specific financial targets challenging. In this work, we introduce a sentence-level corpus for stance detection focused on three core financial metrics: debt, earnings per share (EPS), and sales. The sentences were extracted from Form 10-K annual reports and ECTs, and labeled for stance (positive, negative, neutral) using the advanced ChatGPT-o3-pro model under rigorous human validation. Using this corpus, we conduct a systematic evaluation of modern large language models (LLMs) using zero-shot, few-shot, and Chain-of-Thought (CoT) prompting strategies. Our results show that few-shot with CoT prompting performs best compared to supervised baselines, and LLMs' performance varies across the SEC and ECT datasets. Our findings highlight the practical viability of leveraging LLMs for target-specific stance in the financial domain without requiring extensive labeled data.