EMTSF:Extraordinary Mixture of SOTA Models for Time Series Forecasting
作者: Musleh Alharthi, Kaleel Mahmood, Sarosh Patel, Ausif Mahmood
分类: cs.CL, cs.AI
发布日期: 2025-10-27
💡 一句话要点
提出EMTSF,一种结合SOTA模型的混合专家时间序列预测框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 时间序列预测 混合专家模型 Transformer 深度学习 模型融合
📋 核心要点
- 时间序列预测模型效果不稳定,易受数据特性和突发事件影响,缺乏通用性。
- 提出混合专家(MoE)框架EMTSF,融合多种SOTA模型,利用Transformer进行门控。
- EMTSF在标准benchmark上超越现有TSF模型,包括最新的MoE方法,效果显著。
📝 摘要(中文)
Transformer架构在自然语言处理领域的巨大成功推动了其在时间序列预测(TSF)中的应用,并展现出卓越的性能。然而,最近的一项重要研究质疑了它们的有效性,表明一个简单的单层线性模型优于基于Transformer的模型。随后,PatchTST模型证明了Transformer并非无效。最近,TimeLLM通过重新利用大型语言模型(LLM)在TSF领域取得了更好的结果。然而,后续研究表明,移除LLM组件或将其替换为基本注意力层实际上可以产生更好的性能。预测的挑战之一是TSF数据偏向于最近的过去,并且有时会受到不可预测事件的影响。基于这些最新的TSF见解,我们提出了一个强大的混合专家(MoE)框架。我们的方法结合了最先进(SOTA)的模型,包括xLSTM、增强线性模型、PatchTST和minGRU等。这些互补且多样化的TSF模型集成在基于Transformer的MoE门控网络中。我们提出的模型在标准基准测试中优于所有现有的TSF模型,甚至超过了基于MoE框架的最新方法。
🔬 方法详解
问题定义:时间序列预测(TSF)任务旨在根据历史数据预测未来趋势。现有方法,特别是基于Transformer和LLM的方法,虽然在某些数据集上表现出色,但容易受到数据特性和突发事件的影响,泛化能力不足。简单的线性模型有时也能取得意想不到的效果,说明单一模型难以适应所有场景。
核心思路:论文的核心思路是利用混合专家(MoE)框架,将多个在不同方面表现优秀的SOTA模型(如xLSTM、增强线性模型、PatchTST、minGRU等)集成起来。通过学习不同模型的优势,并根据输入数据动态地选择合适的模型组合,从而提高预测的准确性和鲁棒性。
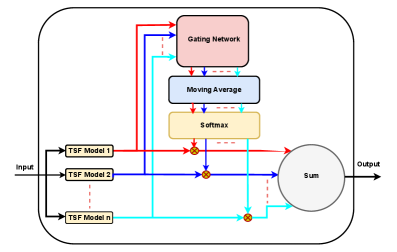
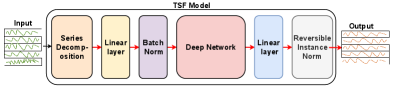
技术框架:EMTSF框架包含以下几个主要模块:1) 多个专家模型:包括xLSTM、增强线性模型、PatchTST、minGRU等;2) Transformer门控网络:用于学习不同专家模型的权重,并根据输入数据动态地选择合适的专家组合;3) 混合模块:将各个专家模型的输出按照门控网络的权重进行加权平均,得到最终的预测结果。整个框架采用端到端的方式进行训练。
关键创新:EMTSF的关键创新在于将多种互补的SOTA模型集成到一个MoE框架中,并使用Transformer作为门控网络。这种设计能够充分利用不同模型的优势,提高预测的准确性和鲁棒性。此外,使用Transformer作为门控网络,能够更好地捕捉时间序列数据中的复杂依赖关系。
关键设计:Transformer门控网络的具体结构和参数设置未知,论文中可能没有详细描述。损失函数可能采用均方误差(MSE)或类似的回归损失函数。专家模型的选择和配置也是关键设计,需要根据具体任务和数据集进行调整。论文中可能没有详细描述具体的训练策略和超参数设置。
🖼️ 关键图片
📊 实验亮点
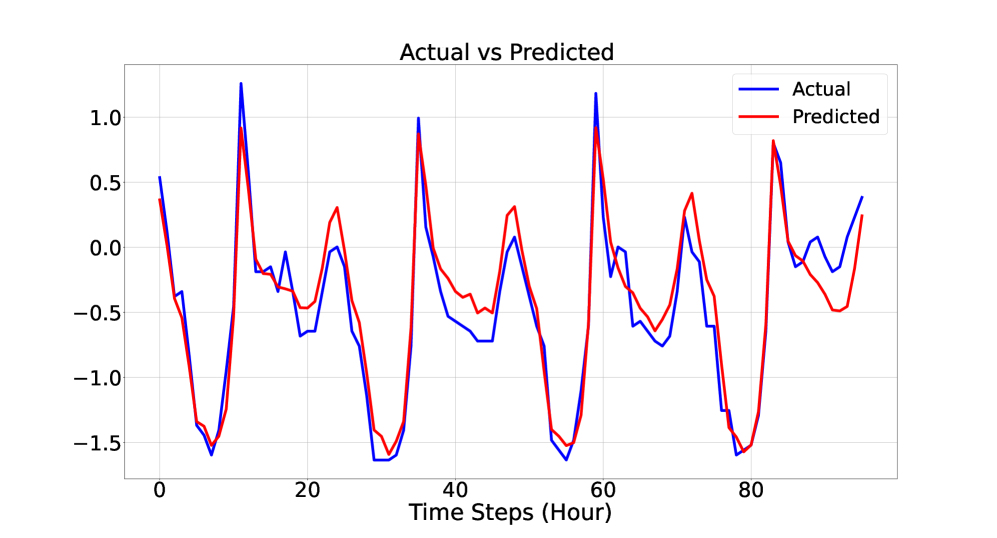
论文提出的EMTSF模型在标准时间序列预测benchmark上取得了显著的性能提升,超越了现有的SOTA模型,包括基于MoE框架的最新方法。具体的性能数据和提升幅度未知,需要在论文中查找。实验结果表明,EMTSF能够有效地融合不同模型的优势,提高预测的准确性和鲁棒性。
🎯 应用场景
EMTSF可应用于金融市场预测、能源需求预测、供应链管理、疾病传播预测等多个领域。通过提高时间序列预测的准确性和鲁棒性,可以帮助企业和政府做出更明智的决策,降低风险,提高效率。该研究的成果有助于推动时间序列分析和预测技术的发展。
📄 摘要(原文)
The immense success of the Transformer architecture in Natural Language Processing has led to its adoption in Time Se ries Forecasting (TSF), where superior performance has been shown. However, a recent important paper questioned their effectiveness by demonstrating that a simple single layer linear model outperforms Transformer-based models. This was soon shown to be not as valid, by a better transformer-based model termed PatchTST. More re cently, TimeLLM demonstrated even better results by repurposing a Large Language Model (LLM) for the TSF domain. Again, a follow up paper challenged this by demonstrating that removing the LLM component or replacing it with a basic attention layer in fact yields better performance. One of the challenges in forecasting is the fact that TSF data favors the more recent past, and is sometimes subject to unpredictable events. Based upon these recent insights in TSF, we propose a strong Mixture of Experts (MoE) framework. Our method combines the state-of-the-art (SOTA) models including xLSTM, en hanced Linear, PatchTST, and minGRU, among others. This set of complimentary and diverse models for TSF are integrated in a Trans former based MoE gating network. Our proposed model outperforms all existing TSF models on standard benchmarks, surpassing even the latest approaches based on MoE frameworks.