Adaptive Blockwise Search: Inference-Time Alignment for Large Language Models
作者: Mohammad Atif Quamar, Mohammad Areeb, Nishant Sharma, Ananth Shreekumar, Jonathan Rosenthal, Muslum Ozgur Ozmen, Mikhail Kuznetsov, Z. Berkay Celik
分类: cs.CL
发布日期: 2025-10-27
💡 一句话要点
AdaSearch:针对大语言模型推理时对齐的自适应分块搜索算法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型对齐 推理时优化 自适应搜索 分块搜索 计算预算分配
📋 核心要点
- 现有推理时对齐方法计算资源分配均匀,忽略了响应中不同token的重要性差异,导致对齐效果次优。
- AdaSearch通过自适应地调整计算预算,将更多的搜索精力集中在对齐任务中更关键的初始token上。
- 实验结果表明,AdaSearch在多个LLM和任务上优于Best-of-N和微调等基线方法,显著提升了对齐效果。
📝 摘要(中文)
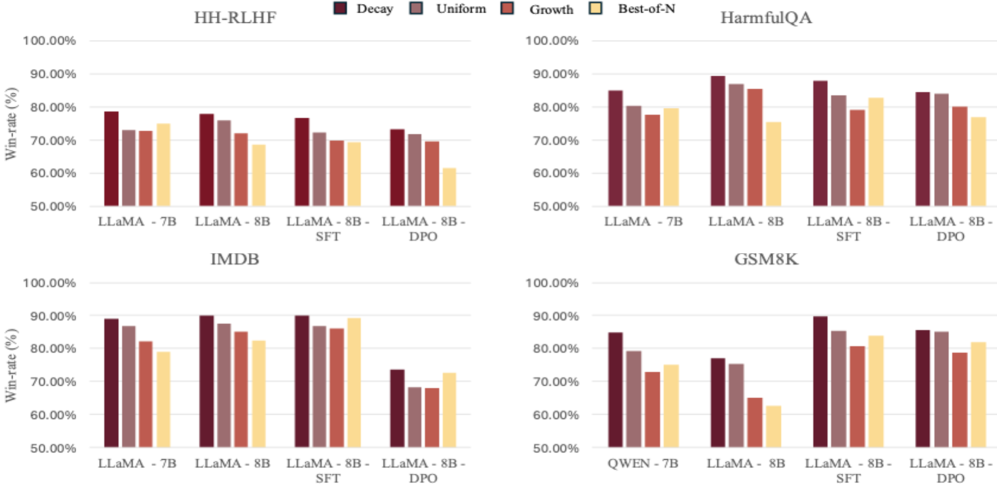
大语言模型(LLM)的对齐仍然是一个关键挑战。推理时方法为微调提供了一种灵活的替代方案,但它们均匀的计算开销通常会产生次优的对齐效果。我们假设,对于许多对齐任务,响应的初始token至关重要。为了利用这一原则,我们引入了AdaSearch,一种新颖的分块搜索策略。它使用采样策略自适应地分配固定的计算预算,并将搜索重点放在这些关键token上。我们将AdaSearch应用于顺序解码,并引入其树搜索对应方法AdaBeam。我们对八个LLM的全面评估表明,AdaSearch优于强大的Best-of-N和微调基线。具体而言,在无害生成、受控情感生成和数学推理任务中,相对于Best-of-N,胜率提高了10%以上。
🔬 方法详解
问题定义:论文旨在解决大语言模型(LLM)推理时对齐问题。现有的推理时对齐方法,如Best-of-N,通常对所有token分配相同的计算资源,没有考虑到不同token对于最终对齐效果的贡献度差异。这种均匀分配的方式导致计算资源的浪费,并且无法达到最优的对齐效果。
核心思路:论文的核心思路是,对于许多对齐任务,响应的初始token对于最终的对齐效果具有更大的影响。因此,应该将更多的计算资源分配给这些关键的初始token,从而提高整体的对齐性能。AdaSearch通过自适应地调整计算预算,实现对不同token的差异化处理。
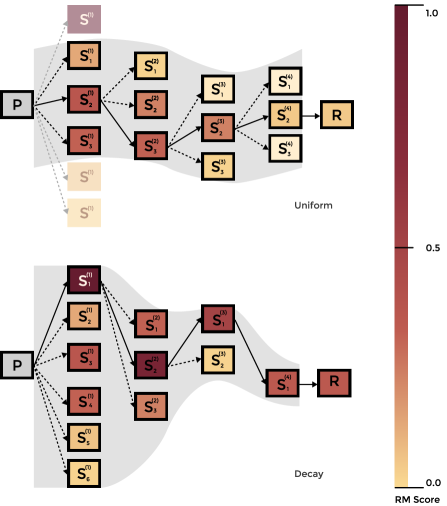
技术框架:AdaSearch主要包含两个变体:AdaSearch for sequential decoding 和 AdaBeam (AdaSearch for tree-search)。它们都基于一个核心思想:根据预定义的采样策略,自适应地分配计算预算。具体来说,AdaSearch在解码的早期阶段进行更密集的搜索,随着解码的进行,搜索的密度逐渐降低。这种策略使得模型能够更好地探索初始token的可能性,从而生成更符合对齐目标的响应。
关键创新:AdaSearch的关键创新在于其自适应的计算预算分配策略。与传统的均匀分配方法不同,AdaSearch能够根据token的重要性动态地调整搜索的深度和广度。这种自适应性使得模型能够更有效地利用有限的计算资源,从而提高对齐性能。AdaBeam是AdaSearch在树搜索上的扩展,进一步提升了搜索效率。
关键设计:AdaSearch的关键设计在于采样策略的设计。论文中使用了多种采样策略,例如线性衰减、指数衰减等。这些策略决定了计算预算在不同token之间的分配方式。此外,AdaSearch还涉及一些超参数的设置,例如总的计算预算、搜索的深度和广度等。这些参数需要根据具体的任务和模型进行调整,以达到最佳的性能。
🖼️ 关键图片

📊 实验亮点
实验结果表明,AdaSearch在多个LLM和任务上均优于Best-of-N和微调等基线方法。例如,在无害生成、受控情感生成和数学推理任务中,相对于Best-of-N,AdaSearch的胜率提高了10%以上。这些结果证明了AdaSearch的有效性和优越性。
🎯 应用场景
AdaSearch可应用于各种需要LLM对齐的场景,例如安全内容生成、情感控制、数学推理等。该方法能够提升LLM在这些场景下的性能,使其生成更符合人类价值观和期望的响应。此外,AdaSearch的自适应计算预算分配策略也为其他LLM推理优化方法提供了新的思路。
📄 摘要(原文)
LLM alignment remains a critical challenge. Inference-time methods provide a flexible alternative to fine-tuning, but their uniform computational effort often yields suboptimal alignment. We hypothesize that for many alignment tasks, the initial tokens of a response are disproportionately more critical. To leverage this principle, we introduce AdaSearch, a novel blockwise search strategy. It adaptively allocates a fixed computational budget using a sampling schedule, focusing search effort on these critical tokens. We apply AdaSearch to sequential decoding and introduce its tree-search counterpart, AdaBeam. Our comprehensive evaluation across eight LLMs demonstrates that AdaSearch outperforms strong Best-of-N and fine-tuning baselines. Specifically, win-rates improve by over 10% for harmlessness generation, controlled sentiment generation, and for mathematical reasoning tasks relative to Best-of-N.