SI-Bench: Benchmarking Social Intelligence of Large Language Models in Human-to-Human Conversations
作者: Shuai Huang, Wenxuan Zhao, Jun Gao
分类: cs.CL
发布日期: 2025-10-27
备注: 17 pages, 9 figures
🔗 代码/项目: GITHUB
💡 一句话要点
SI-Bench:构建社交智能基准,评估大语言模型在人际对话中的表现
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 社交智能 人际对话 大型语言模型 基准测试 社会科学
📋 核心要点
- 现有方法依赖模拟对话,无法捕捉真实人际互动中细微的语言风格和关系动态。
- SI-Bench构建了一个包含真实人际对话的数据集,并基于社会科学理论进行标注,用于评估LLM的社交智能。
- 实验表明,SOTA模型在过程推理上超越人类专家,但在回复质量上仍有差距,且CoT推理可能降低性能。
📝 摘要(中文)
随着大型语言模型(LLMs)发展出拟人化的能力,它们越来越多地被部署为自主代理与人类互动。然而,评估它们在真实和复杂的社交互动中的表现仍然是一个重大挑战。以往的研究大多通过模拟代理之间的互动来构建数据集,但这种方法无法捕捉到真实人类对话中存在的地道的语言风格和关系动态。为了解决这一差距,我们推出了SI-Bench,这是一个旨在评估LLMs社交智能的新基准。SI-Bench基于广泛的社会科学理论,包含从社交网络应用中收集的2221个真实的多轮对话。我们进一步选择了312个对话的子集,对8个主要模型进行了人工标注。实验表明,SOTA模型在复杂社会情境下的过程推理方面已经超过了人类专家,但在回复质量方面仍然落后于人类。此外,引入思维链(CoT)推理可能会降低LLMs在社交对话任务中的性能。所有数据集均可在https://github.com/SI-Bench/SI-Bench.git上公开获取。
🔬 方法详解
问题定义:现有的大语言模型在社交互动中的表现评估不足,主要原因是缺乏真实的人际对话数据。以往的研究通常使用模拟的agent-to-agent对话数据,这无法捕捉到真实人类对话中复杂的语言风格、情感表达和关系动态,导致评估结果与实际应用场景存在偏差。因此,如何构建一个能够真实反映人类社交互动的数据集,并在此基础上评估LLM的社交智能,是一个亟待解决的问题。
核心思路:SI-Bench的核心思路是利用真实的人际对话数据,并结合社会科学理论,构建一个全面的社交智能评估基准。通过收集真实的社交网络应用中的对话数据,可以保证数据集的真实性和多样性。同时,基于社会科学理论进行标注,可以从多个维度评估LLM的社交智能,例如理解他人意图、表达情感、维护关系等。
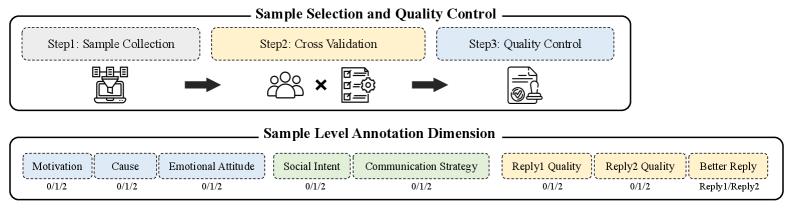
技术框架:SI-Bench的整体框架包括数据收集、数据标注和模型评估三个主要阶段。首先,从社交网络应用中收集大量的多轮对话数据。然后,选择一部分对话进行人工标注,标注维度包括对话主题、情感倾向、社交策略等。最后,使用标注好的数据集评估不同LLM的社交智能,并分析其优缺点。
关键创新:SI-Bench的关键创新在于其数据集的真实性和标注的全面性。与以往的模拟对话数据集相比,SI-Bench的数据集来源于真实的人际互动,能够更准确地反映LLM在实际应用中的表现。此外,SI-Bench的标注维度涵盖了社交智能的多个方面,能够更全面地评估LLM的社交能力。
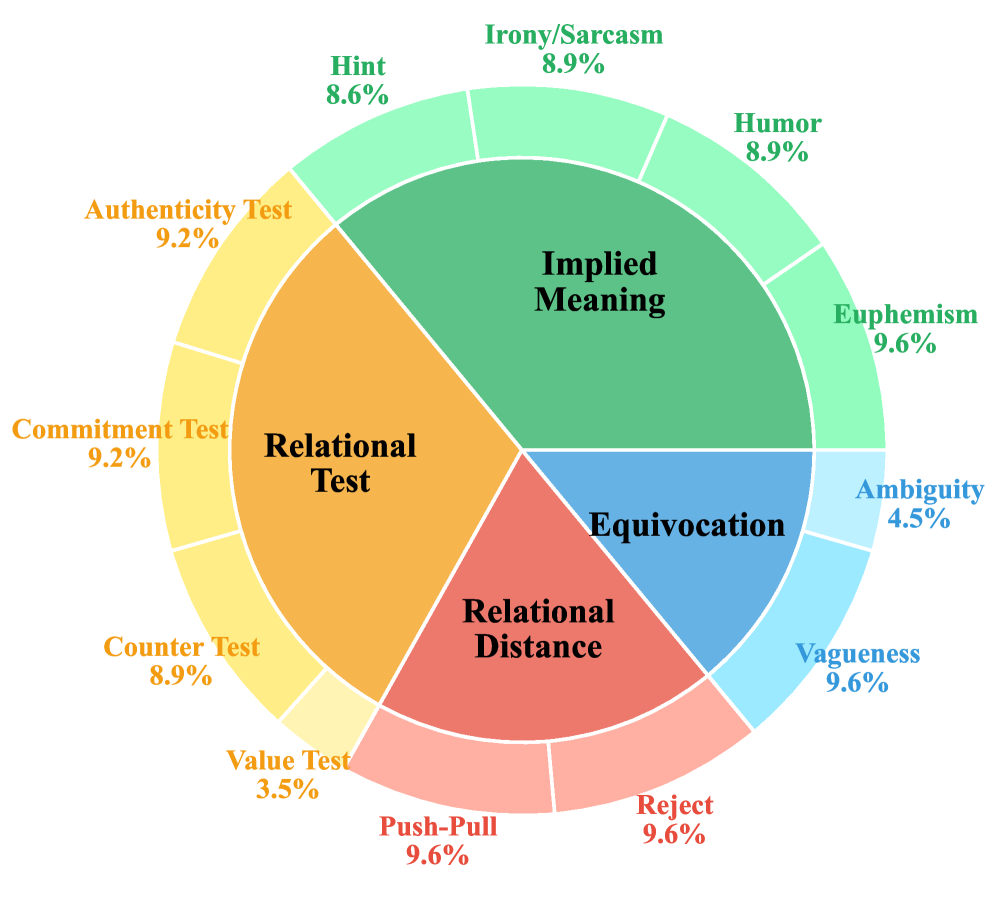
关键设计:SI-Bench的数据集包含2221个多轮对话,其中312个对话进行了人工标注。标注维度包括:1) 理解他人意图;2) 表达情感;3) 维护关系;4) 社交策略;5) 回复质量;6) 过程推理;7) 常识推理;8) 道德判断。评估指标包括准确率、召回率、F1值等。此外,论文还探讨了思维链(CoT)推理对LLM社交智能的影响。
🖼️ 关键图片

📊 实验亮点
实验结果表明,SOTA模型在复杂社会情境下的过程推理方面已经超过了人类专家,但在回复质量方面仍然落后于人类。此外,引入思维链(CoT)推理可能会降低LLMs在社交对话任务中的性能。例如,在某些社交场景下,CoT推理可能导致模型过度分析,反而忽略了人类情感和社交暗示。
🎯 应用场景
SI-Bench的研究成果可以应用于开发更具社交智能的对话系统,例如智能客服、社交机器人、心理咨询助手等。通过使用SI-Bench评估和改进LLM的社交能力,可以使其更好地理解人类的情感和意图,从而提供更自然、更有效的交互体验。此外,该研究还可以促进社会科学和人工智能领域的交叉研究,为理解人类社交行为提供新的视角。
📄 摘要(原文)
As large language models (LLMs) develop anthropomorphic abilities, they are increasingly being deployed as autonomous agents to interact with humans. However, evaluating their performance in realistic and complex social interactions remains a significant challenge. Most previous research built datasets through simulated agent-to-agent interactions, which fails to capture the authentic linguistic styles and relational dynamics found in real human conversations. To address this gap, we introduce SI-Bench, a novel benchmark designed to evaluate aspects of social intelligence in LLMs. Grounded in broad social science theories, SI-Bench contains 2,221 authentic multi-turn dialogues collected from a social networking application. We further selected a subset of 312 dialogues for manual annotation across 8 major models. The experiments show that SOTA models have surpassed the human expert in process reasoning under complex social situations, yet they still fall behind humans in reply quality. Moreover, introducing Chain-of-Thought (CoT) reasoning may degrade the performance of LLMs in social dialogue tasks. All datasets are openly available at https://github.com/SI-Bench/SI-Bench.git.