Beyond Direct Generation: A Decomposed Approach to Well-Crafted Screenwriting with LLMs
作者: Hang Lei, Shengyi Zong, Zhaoyan Li, Ziren Zhou, Hao Liu, Liang Yu
分类: cs.CL, cs.AI
发布日期: 2025-10-27 (更新: 2026-01-07)
💡 一句话要点
提出双阶段精炼框架DSR,解决LLM生成高质量剧本时创意与格式难以兼顾的问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 剧本生成 大型语言模型 双阶段精炼 数据合成 创意写作 格式转换 自然语言处理
📋 核心要点
- 现有LLM直接生成剧本的方法难以同时兼顾创意叙事和严格格式,导致生成质量不高。
- DSR框架将剧本生成分解为创意叙事生成和格式转换两个阶段,使模型能够专注于各自任务。
- 通过混合数据合成解决训练数据稀缺问题,实验表明DSR显著优于现有基线,接近人类水平。
📝 摘要(中文)
剧本是电视制作的基础,定义了叙事结构、角色发展和对话。大型语言模型(LLM)在创意写作方面显示出巨大潜力,但直接端到端生成方法通常无法生成制作精良的剧本。我们认为,这种失败源于迫使单个模型同时掌握两种截然不同的能力:创造性的叙事构建和严格的格式遵守。由此产生的输出可能模仿表面风格,但缺乏专业使用所需的深度结构完整性和故事讲述实质。为了使LLM能够生成高质量的剧本,我们引入了双阶段精炼(DSR),这是一个将创意叙事生成与格式转换分离的分解框架。第一阶段将简短的概要转化为丰富的新颖风格散文。第二阶段将此叙事提炼成专业格式的剧本。这种分离使模型能够在每个阶段专注于一种独特的能力。实施DSR的一个关键挑战是缺乏配对的概要到小说训练数据。我们通过混合数据合成来解决这个问题:反向合成将现有剧本解构为结构化输入,而正向合成则利用这些输入来生成高质量的叙事文本作为训练目标。专业编剧的盲测评估表明,DSR实现了75%的胜率,优于Gemini-2.5-Pro等强大的基线,并达到了人类水平表现的82.7%。我们的工作表明,具有定制数据合成的分解生成架构可以有效地使LLM专注于复杂的创意领域。
🔬 方法详解
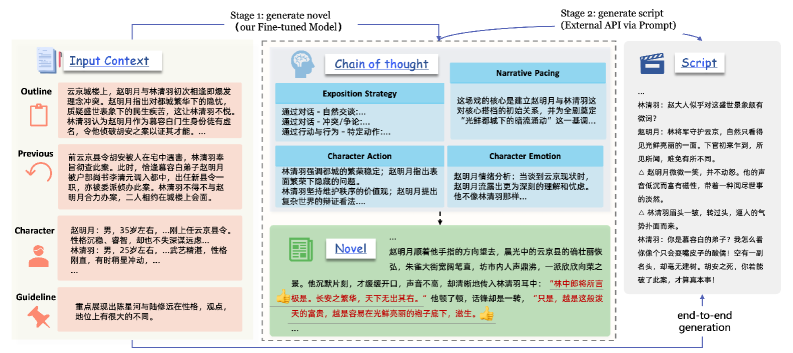
问题定义:论文旨在解决大型语言模型(LLM)在直接生成剧本时,难以同时兼顾创意叙事和严格格式要求的问题。现有端到端方法生成的剧本往往缺乏深度结构和故事性,无法满足专业需求。
核心思路:论文的核心思路是将剧本生成过程分解为两个阶段:首先生成具有丰富创意内容的叙事文本,然后将该文本转换为符合专业格式的剧本。这种分解允许模型在每个阶段专注于不同的能力,从而提高整体生成质量。
技术框架:DSR框架包含两个主要阶段:1) 叙事生成阶段:将简短的剧本大纲转换为小说风格的叙事文本。2) 格式精炼阶段:将叙事文本转换为符合行业标准的剧本格式。为了训练模型,论文采用混合数据合成方法,包括反向合成(将现有剧本解构为大纲)和正向合成(利用大纲生成叙事文本)。
关键创新:DSR框架的关键创新在于将剧本生成任务分解为两个专门化的阶段,并采用混合数据合成方法来解决训练数据稀缺的问题。这种分解架构允许模型更好地学习创意叙事和格式转换的技能。
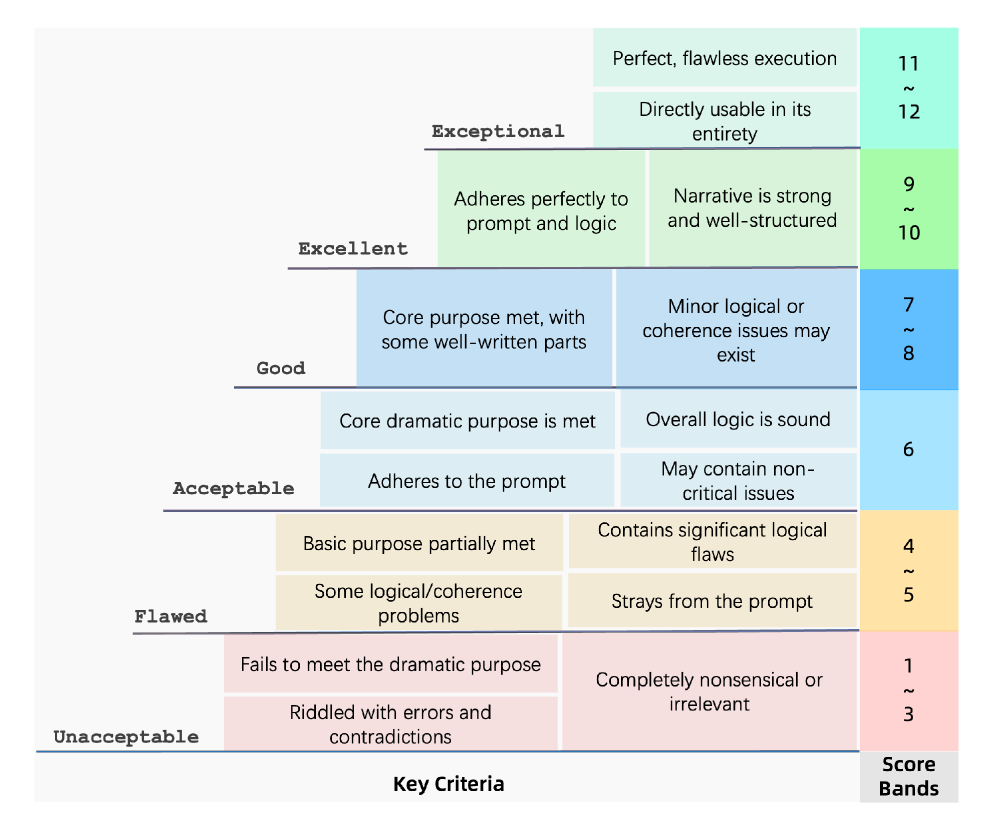
关键设计:论文的关键设计包括:1) 使用LLM作为叙事生成和格式精炼的模型。2) 设计反向合成和正向合成的数据生成流程,以创建高质量的训练数据。3) 采用专业编剧进行盲测评估,以客观评估DSR的性能。
🖼️ 关键图片

📊 实验亮点
实验结果表明,DSR框架在剧本生成质量方面显著优于现有基线模型,包括Gemini-2.5-Pro。专业编剧的盲测评估显示,DSR的胜率达到75%,并达到了人类水平表现的82.7%。这些数据表明,DSR框架能够有效地提高LLM生成剧本的质量。
🎯 应用场景
该研究成果可应用于自动化剧本创作、辅助编剧工作、以及其他需要创意文本生成和格式转换的领域。通过DSR框架,可以降低剧本创作的门槛,提高创作效率,并为影视行业带来新的可能性。未来,该技术还可扩展到其他类型的创意写作,如小说、游戏剧本等。
📄 摘要(原文)
The screenplay serves as the foundation for television production, defining narrative structure, character development, and dialogue. While Large Language Models (LLMs) show great potential in creative writing, direct end-to-end generation approaches often fail to produce well-crafted screenplays. We argue this failure stems from forcing a single model to simultaneously master two disparate capabilities: creative narrative construction and rigid format adherence. The resulting outputs may mimic superficial style but lack the deep structural integrity and storytelling substance required for professional use. To enable LLMs to generate high-quality screenplays, we introduce Dual-Stage Refinement (DSR), a decomposed framework that decouples creative narrative generation from format conversion. The first stage transforms a brief outline into rich, novel-style prose. The second stage refines this narrative into a professionally formatted screenplay. This separation enables the model to specialize in one distinct capability at each stage. A key challenge in implementing DSR is the scarcity of paired outline-to-novel training data. We address this through hybrid data synthesis: reverse synthesis deconstructs existing screenplays into structured inputs, while forward synthesis leverages these inputs to generate high-quality narrative texts as training targets. Blind evaluations by professional screenwriters show that DSR achieves a 75% win rate against strong baselines like Gemini-2.5-Pro and reaches 82.7% of human-level performance. Our work demonstrates that decomposed generation architecture with tailored data synthesis effectively specializes LLMs in complex creative domains.