Beyond Higher Rank: Token-wise Input-Output Projections for Efficient Low-Rank Adaptation
作者: Shiwei Li, Xiandi Luo, Haozhao Wang, Xing Tang, Ziqiang Cui, Dugang Liu, Yuhua Li, Xiuqiang He, Ruixuan Li
分类: cs.CL, cs.LG
发布日期: 2025-10-27
备注: Accepted by NeurIPS 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出Token-wise Projected LoRA (TopLoRA),实现更细粒度的参数高效微调。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 参数高效微调 低秩适应 大型语言模型 Token-wise投影 自适应学习
📋 核心要点
- 标准LoRA对所有token使用相同的投影权重,忽略了token间的语义差异,限制了模型对token特定信息的捕捉能力。
- TopLoRA的核心思想是根据输入token动态调整LoRA权重,学习token-wise的输入-输出投影,实现更细粒度的参数调整。
- 实验结果表明,TopLoRA在多个模型和数据集上始终优于LoRA及其变体,验证了其有效性。
📝 摘要(中文)
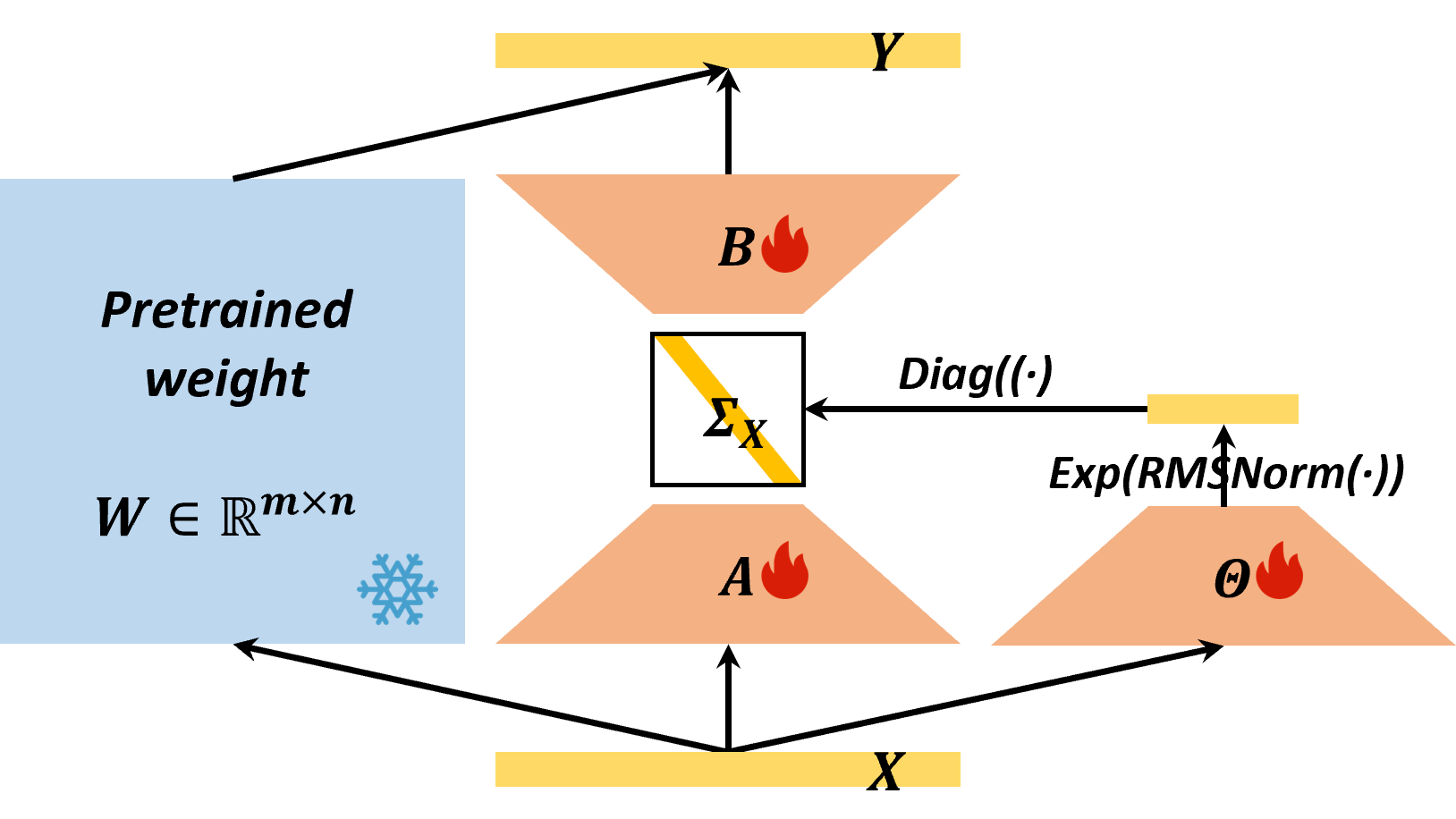
低秩适应(LoRA)是一种广泛应用于大型语言模型(LLM)的参数高效微调(PEFT)方法。LoRA本质上描述了输入空间到低维输出空间的投影,其维度由LoRA秩决定。在标准LoRA中,所有输入token共享相同的权重,并进行相同的输入-输出投影。由于token之间固有的语义差异,这限制了LoRA捕获token特定信息的能力。为了解决这个限制,我们提出了Token-wise Projected Low-Rank Adaptation (TopLoRA),它根据输入token动态调整LoRA权重,从而以端到端的方式学习token-wise的输入-输出投影。形式上,TopLoRA的权重可以表示为$BΣ_X A$,其中$A$和$B$是低秩矩阵(与标准LoRA中一样),$Σ_X$是由每个输入token $X$生成的对角矩阵。值得注意的是,TopLoRA并没有增加LoRA权重的秩,而是通过学习token-wise LoRA权重(即token-wise输入-输出投影)实现了更细粒度的适应。在多个模型和数据集上的大量实验表明,TopLoRA始终优于LoRA及其变体。
🔬 方法详解
问题定义:LoRA通过低秩矩阵分解来近似权重更新,从而减少了微调所需的参数量。然而,标准的LoRA对所有输入token使用相同的低秩投影,忽略了不同token之间语义信息的差异。这限制了模型捕捉token特定信息的能力,从而影响了微调效果。因此,如何使LoRA能够根据不同的token进行自适应调整,是本文要解决的问题。
核心思路:TopLoRA的核心思路是引入token-wise的权重调整。具体来说,对于每一个输入token,TopLoRA都会生成一个对应的对角矩阵,该矩阵用于调整LoRA的低秩矩阵。通过这种方式,不同的token可以拥有不同的LoRA权重,从而实现token级别的自适应微调。
技术框架:TopLoRA的整体框架与LoRA类似,都是在预训练模型的线性层中插入低秩矩阵。不同之处在于,TopLoRA在低秩矩阵的基础上,增加了一个token-wise的权重调整模块。该模块根据输入token生成一个对角矩阵,然后将该矩阵与LoRA的低秩矩阵相乘,得到最终的token-wise LoRA权重。
关键创新:TopLoRA最重要的创新在于引入了token-wise的权重调整机制。与标准的LoRA相比,TopLoRA能够根据不同的token进行自适应调整,从而更好地捕捉token特定信息。此外,TopLoRA并没有增加LoRA权重的秩,而是在不增加参数量的前提下,实现了更细粒度的微调。
关键设计:TopLoRA的关键设计在于如何生成token-wise的对角矩阵。论文中并没有详细说明如何生成该矩阵,但可以推测是使用一个小型神经网络,以输入token的embedding作为输入,输出一个对角矩阵。此外,TopLoRA的损失函数与LoRA相同,都是使用交叉熵损失函数。
🖼️ 关键图片


📊 实验亮点
实验结果表明,TopLoRA在多个模型和数据集上都优于LoRA及其变体。例如,在文本分类任务中,TopLoRA相比LoRA取得了显著的性能提升。这些结果验证了TopLoRA的有效性,表明其能够更好地捕捉token特定信息,从而提升模型性能。
🎯 应用场景
TopLoRA可应用于各种需要参数高效微调的大型语言模型任务,例如文本分类、文本生成、机器翻译等。其token-wise的自适应能力使其在处理具有复杂语义信息的文本时具有优势,能够提升模型性能。该方法还有潜力应用于其他模态的模型微调,例如图像和语音。
📄 摘要(原文)
Low-rank adaptation (LoRA) is a parameter-efficient fine-tuning (PEFT) method widely used in large language models (LLMs). LoRA essentially describes the projection of an input space into a low-dimensional output space, with the dimensionality determined by the LoRA rank. In standard LoRA, all input tokens share the same weights and undergo an identical input-output projection. This limits LoRA's ability to capture token-specific information due to the inherent semantic differences among tokens. To address this limitation, we propose Token-wise Projected Low-Rank Adaptation (TopLoRA), which dynamically adjusts LoRA weights according to the input token, thereby learning token-wise input-output projections in an end-to-end manner. Formally, the weights of TopLoRA can be expressed as $BΣ_X A$, where $A$ and $B$ are low-rank matrices (as in standard LoRA), and $Σ_X$ is a diagonal matrix generated from each input token $X$. Notably, TopLoRA does not increase the rank of LoRA weights but achieves more granular adaptation by learning token-wise LoRA weights (i.e., token-wise input-output projections). Extensive experiments across multiple models and datasets demonstrate that TopLoRA consistently outperforms LoRA and its variants. The code is available at https://github.com/Leopold1423/toplora-neurips25.