A Survey on LLM Mid-Training
作者: Chengying Tu, Xuemiao Zhang, Rongxiang Weng, Rumei Li, Chen Zhang, Yang Bai, Hongfei Yan, Jingang Wang, Xunliang Cai
分类: cs.CL
发布日期: 2025-10-27 (更新: 2025-11-04)
💡 一句话要点
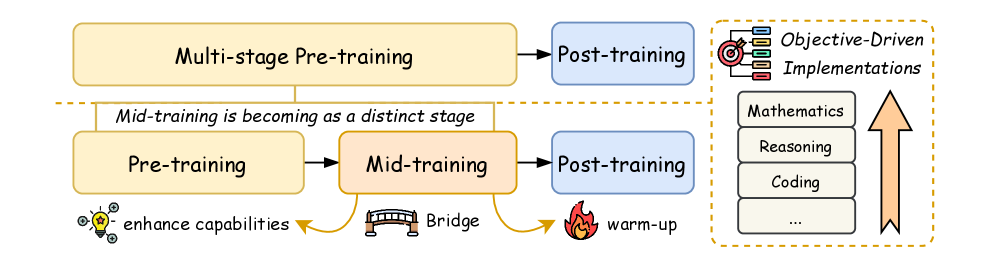
综述LLM中训练:弥合预训练与后训练,提升特定能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 中训练 多阶段训练 能力提升 数据管理
📋 核心要点
- 现有LLM训练方法在特定能力(如数学、编码、推理)的提升上存在不足,难以兼顾基础能力。
- 论文核心在于定义并分析LLM中训练阶段,通过中间数据和计算资源,有针对性地提升模型特定能力。
- 该综述分析了主流模型在中训练阶段的实现,为未来LLM训练策略提供了全面的分类和可操作的见解。
📝 摘要(中文)
大型语言模型(LLM)的最新进展突显了多阶段训练的显著优势,其中中训练作为一个关键阶段,连接了预训练和后训练。中训练的特点是使用中间数据和计算资源,系统地增强特定能力,如数学、编码、推理和长上下文扩展,同时保持基础能力。本综述为大型语言模型(LLM)提供了中训练的正式定义,并研究了包括数据管理、训练策略和模型架构优化在内的优化框架。我们分析了以目标驱动干预为背景的主流模型实现,阐述了中训练如何作为LLM能力逐步发展中一个独特而关键的阶段。通过阐明中训练的独特贡献,本综述提供了一个全面的分类和可操作的见解,支持未来在LLM发展中的研究和创新。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在预训练和后训练之间如何有效提升特定能力的问题。现有方法要么侧重于预训练的大规模通用能力获取,要么侧重于后训练的特定任务微调,缺乏一个中间阶段来有针对性地增强模型在数学、编码、推理等方面的能力,同时保持其基础能力。
核心思路:论文的核心思路是明确中训练(Mid-Training)的概念,将其定义为连接预训练和后训练的关键阶段。通过精心设计的数据集和训练策略,在中训练阶段对模型进行有针对性的能力提升,从而弥补预训练和后训练之间的差距。这种方法允许在不牺牲基础能力的前提下,显著提升模型的特定能力。
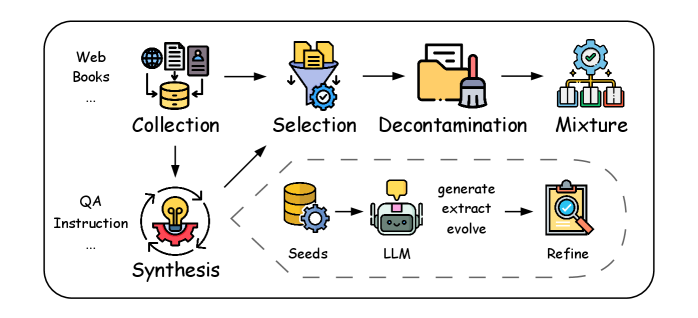
技术框架:论文构建了一个中训练的优化框架,主要包含以下几个模块:1) 数据管理(Data Curation):选择或构建适合特定能力提升的中间数据集。2) 训练策略(Training Strategies):设计合适的训练目标和优化算法,例如,使用特定领域的损失函数或采用 curriculum learning 的方式。3) 模型架构优化(Model Architecture Optimization):根据需要调整模型结构,例如,增加特定领域的专家模块。
关键创新:论文最重要的技术创新点在于明确了中训练的概念,并将其作为一个独立的、重要的训练阶段进行研究。与传统的预训练和后训练方法相比,中训练能够更有效地提升模型的特定能力,并且能够更好地平衡基础能力和特定能力之间的关系。
关键设计:论文分析了主流模型在中训练阶段的具体实现,例如,针对数学能力提升,可以使用包含大量数学题目的数据集进行训练,并采用特定的损失函数来鼓励模型学习数学推理规则。针对编码能力提升,可以使用代码数据集进行训练,并采用代码生成和代码理解相结合的训练方式。
🖼️ 关键图片
📊 实验亮点
该综述系统性地分析了LLM中训练的各个方面,包括数据管理、训练策略和模型架构优化。通过对主流模型实现的分析,揭示了中训练在提升特定能力方面的有效性。该研究为未来的LLM训练提供了重要的参考和指导,有望推动LLM在各个领域的应用。
🎯 应用场景
该研究成果可广泛应用于各种需要特定能力增强的LLM应用场景,例如,可以用于开发更强大的智能助手、更专业的代码生成工具、更精准的数学解题模型等。通过中训练,可以显著提升LLM在特定领域的性能,从而拓展其应用范围和实际价值,并为未来的LLM发展提供新的方向。
📄 摘要(原文)
Recent advances in foundation models have highlighted the significant benefits of multi-stage training, with a particular emphasis on the emergence of mid-training as a vital stage that bridges pre-training and post-training. Mid-training is distinguished by its use of intermediate data and computational resources, systematically enhancing specified capabilities such as mathematics, coding, reasoning, and long-context extension, while maintaining foundational competencies. This survey provides a formal definition of mid-training for large language models (LLMs) and investigates optimization frameworks that encompass data curation, training strategies, and model architecture optimization. We analyze mainstream model implementations in the context of objective-driven interventions, illustrating how mid-training serves as a distinct and critical stage in the progressive development of LLM capabilities. By clarifying the unique contributions of mid-training, this survey offers a comprehensive taxonomy and actionable insights, supporting future research and innovation in the advancement of LLMs.